

What is incident response?
Incident response is a strategic approach to detecting and responding to cyberattacks. It comprises a coordinated series of procedures to help you detect, remove and recover from the impact of a threat in an organized, efficient and timely manner. Furthermore, it covers preparation and fine-tuning measures, such as documented plans and playbooks, tools and technologies, testing, and reviews, to help ensure it meets these goals.
Incident response is a part of incident management, which refers to the broader way in which you would handle an attack, involving senior management, legal teams, HR, communications, and the wider IT department.
This guide essentially focuses on incident response. But it briefly covers other aspects of incident management, as it's important an organization take a holistic approach to handling future incidents.
Let's begin by running through a few basic concepts.

What is a security incident?
Incident response teams need to act quickly in the event they're called into action. So they cannot afford time-consuming misunderstandings that can arise through the incorrect use of terminology. That's why they need to understand exactly what constitutes a security incident and how it differs from similar terms such as security event and attack.
A security event is the presence of unusual network behavior, such as a sudden spike in traffic or privilege escalation, that could be the indicator of a security breach. However, it doesn't necessarily mean you have a security issue. On further investigation, it may turn out to be a perfectly legitimate activity.
A security incident is one or more correlated security events with confirmed potential negative impact, such as the loss of or unauthorized access to data—whether deliberate or accidental.
An attack is a premeditated breach of security with malicious intent.
Types of security incident
You should be adequately prepared for different types of incidents whatever its nature. So you'll need to consider a range of scenarios. These include different types of application and underlying infrastructure—but, above all, different types of attack.
The most common of these are:
Denial-of-service (DoS): An attempt to flood a service with bogus requests, thereby making it unavailable to legitimate users.
Application compromise: An application that's been hacked, using techniques such as SQL injection, cross-site scripting (XSS), and cache poisoning, with a view to corrupting, deleting or exfiltrating data, or running other forms of malicious code.
Ransomware: A type of malware that uses encryption to block access to your data. The attacker then demands a ransom in exchange for the encryption keys.
Data breach: A security breach that specifically involves unauthorized access to sensitive or confidential data.
Man-in-the-middle (MitM): A modern-day form of wiretapping where an adversary covertly intercepts the data exchange between two parties and manipulates the communication between them.
You should develop a deep understanding into the different types of attack and potential vulnerabilities in your systems accordingly. This will help you formulate response procedures and identify tooling and technology requirements. At the same time, it will help you improve your security defenses and reduce the risk of a major incident arising in the first place.
The Cloud Security Threat Report
The Wiz Threat Research team looks back on the past year to highlight trends and the state of multi cloud usage based on visibility across our customer base.
Download Report

Incident response in the cloud
In view of the widespread adoption of the cloud, incident response is evolving to meet the challenges brought about by new types of threat and different application deployment models.
However, many organizations still rely on outdated incident response procedures. They therefore need to remain adequately prepared by adapting their response strategies to the new attack surface. For example, by:
Ensuring the incident response team receives sufficient training to understand your cloud-based IT environment
Implementing tooling that's specifically designed for the complex and dynamic nature of the cloud
Making use of the telemetry available from their cloud service provider (CSP)
The Cloud Threat Landscape
A comprehensive threat intelligence database of cloud security incidents, actors, tools and techniques.
Explore
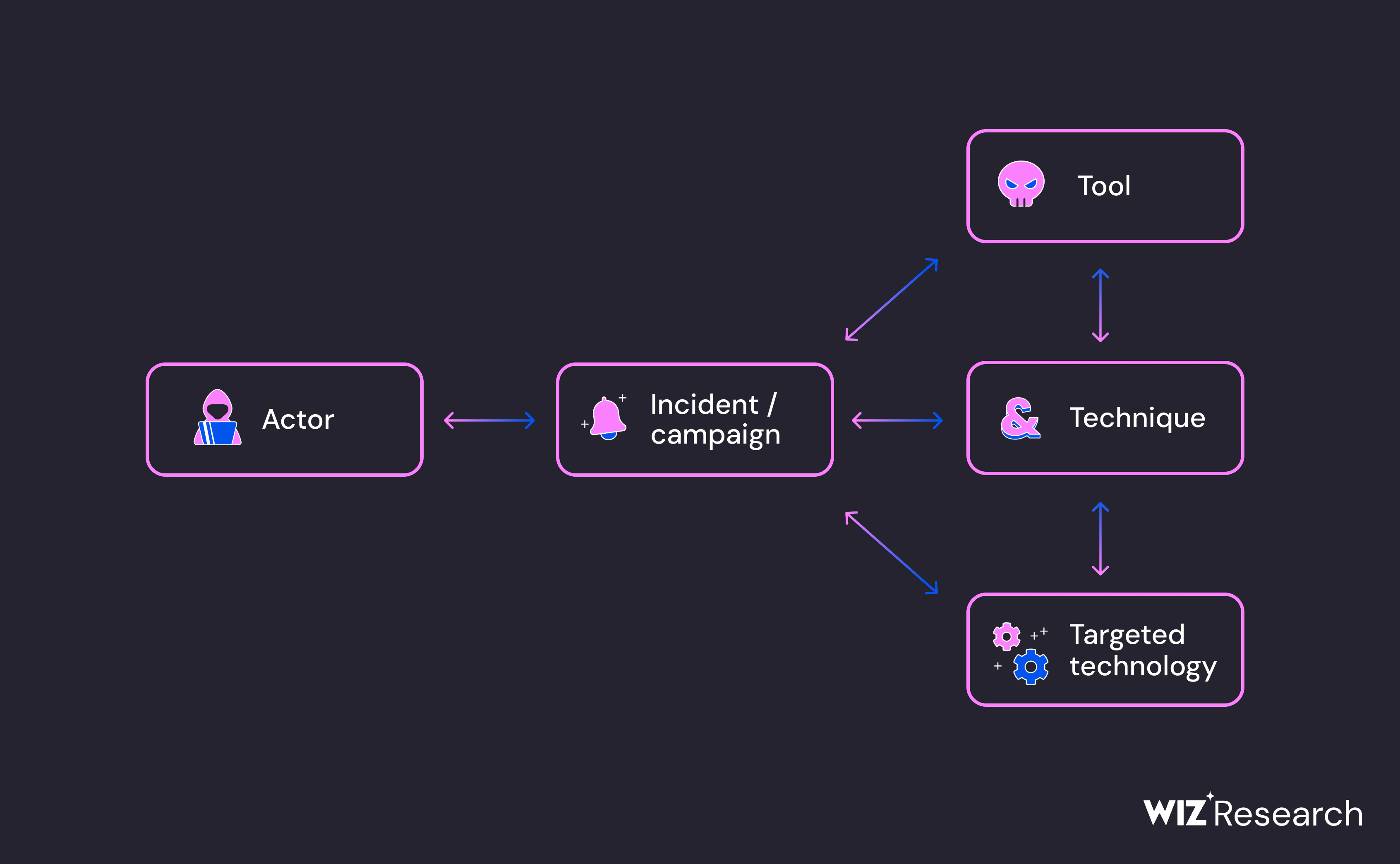
Incident response documentation
A formally documented course of action is an essential component of any robust incident response strategy, as it provides a clear roadmap for handling incidents and ensures you're suitably equipped to do so.
As a general rule, incident response material consists of three types of document, as follows.
Incident response policy
The policy document sets the ball rolling for your initiative, serving as a broad blueprint for your incident response strategy.
It seeks buy-in from senior decision makers by putting the business case for incident response. It mandates the creation of an incident response team and a fully fledged incident response program. It should be approved by the leadership team, giving you the authority to take your mission forward.
It is a single document that provides the stepping stone to more detailed documentation geared towards the practicalities of the incident response process.
Incident response plan
The incident response plan expands upon your policy document by explaining in greater detail the measures you should have in place for handling cybersecurity incidents. It runs through the full response lifecycle with outline plans on how to:
Detect and classify a security incident
Determine the full workings of the attack
Limit the impact on your IT systems and business operations
Eliminate the threat
Recover from the incident
Furthermore, it sets out:
Preparations you'll make in anticipation of an attack
Proposals for post-incident activity for analysis and reviews
An incident response plan is also a single document, laying down the groundwork that supports your incident response playbooks.
Incident response playbooks
In general terms, an incident response playbook is a document that provides a highly detailed set of procedures for handling a specific type of incident.
Each playbook is tailored to different circumstances. For example, you'd typically create a series of playbooks for different attack vectors. However, you can also use a playbook to provide instructions for a specific role in the incident response team. This is commonplace in the wider incident management process. For instance, you'd typically create playbooks for legal and PR teams to help them meet compliance requirements and handle communications respectively.
The incident response team
The incident response team is a cross-functional group of people responsible for orchestrating the incident response operation.
It is assembled from a diverse array of job roles across the organization and usually includes the following:
Executive sponsor. A member of senior management, such as the chief security officer (CSO) or chief information security officer (CISO), who serves as an advocate for your incident response initiative. They will often assume responsibility for reporting progress to your company's executive team.
Incident response manager: The team lead, who develops and refines incident response strategy and coordinates activity. They take overall responsibility and authority throughout the response process.
Communications team: Representatives from your PR, social media and HR departments, along with spokespeople and company bloggers, who would be responsible for keeping staff, customers, the public, and other stakeholders informed of developments.
Legal team: Designated legal representatives, who deal with the compliance and criminal implications of an incident, along with potential breaches of contract.
Technical team. Individuals from your IT and security operations teams, who are suitably qualified to perform the technical duties involved in detecting, analyzing, containing and removing the threat.
Incident response lifecycle
A well-structured and systematic incident response lifecycle is core to effective incident management, providing a step-by-step process for dealing with an attack. However, you don't need to start from scratch to develop your own response lifecycle, as a number of frameworks are available to guide you through the process.
These include:
NIST 800-61: Computer Security Incident Handling Guide
SANS 504-B Incident Response Cycle
ISO/IEC 27035 Series: Information Technology — Information Security Incident Management
On similar lines, Wiz recently published an incident response plan template that's aimed specifically at those responsible for protecting public cloud, hybrid cloud and multicloud deployments.
Although each incident response framework takes a slightly different approach, they all essentially break the lifecycle down into the following phases.
Preparation
The worst time to start working on a response strategy is just when an incident strikes, as you need to act quickly to minimize the damage and reduce disruption to your business. That's why preparation is so important.
The preparation phase of incident response ensures you have everything in place ahead of time so you can respond to an incident without delay. It will include arrangements such as:
The formation of the incident response team
An up-to-date asset inventory to help ensure you have all bases covered
Capture of log data to support timeline analysis after an incident
Procurement of tooling for rapid detection and containment
Implementation of an issue-tracking system for escalating cases and monitoring progress
Contingency measures to minimize disruption to business operations
Incident response training
Incident response testing exercises
Cyber insurance cover
Detection
The detection phase takes a methodical approach to identifying whether a security incident has occurred or is about to occur. The first signs of an attack include:
a high number of failed login attempts
unusual service access requests
privilege escalations
blocked access to accounts or resources
missing data assets
slow running systems
a system crash
However, detection is one of the most challenging aspects of incident response, as it involves correlating information from a range of sources to confirm that such events represent an actual security incident. Sources may include:
Workload telemetry
Telemetry available from a CSP
Third-party threat intelligence
Feedback from end users
Other parties in your software supply chain
Investigation/Analysis
The incident investigation phase comprises a systematic series of steps to determine the root cause of the attack, the likely impact on your deployments, and appropriate corrective action.
As with the detection phase, it involves piecing together event data from different log sources to build up a full picture of the incident.
Containment
The purpose of the containment phase is to:
Minimize the blast radius of an attack
Limit the impact on your IT systems and business operations
Buy time before taking more comprehensive remediation action
Methods will vary with the type of incident. For example, to contain a denial-of-service (DoS) attack, you'd implement network measures, such as IP address filtering. But, in many other cases, you'd isolate resources to prevent lateral movement of the attack. The way you'd do this would depend on the type of infrastructure. In a traditional IT setting, a security tool such as endpoint detection and response (EDR) would be the most efficient method. But in a cloud-based environment, it's generally simpler to change the security group settings of the resource through the control plane.
Did you know? Gartner recognizes cloud investigation and response automation (CIRA) as an indispensable technology in the cybersecurity landscape. Gartner views CIRA as a strategic investment for organizations looking to fortify their security posture in the cloud. Simply put, the shift to cloud computing brings unprecedented opportunities but also introduces new risks.
Eradication
Eradication is the phase in which you completely remove the threat so that it's no longer present anywhere within your organization’s network.
Ways to rid your systems of a threat include:
Removing malicious code
Reinstalling applications
Rotating secrets such as login credentials and API tokens
Blocking points of entry
Patching vulnerabilities
Updating infrastructure-as-code (IaC) templates
Restoring files to their pre-infection state
It's also vital to scan both affected and unaffected systems following remediation—to ensure no traces of the intrusion have been left behind.
Post-incident review
The review phase provides the opportunity to refine your response strategy so you're better equipped to handle potential incidents in the future. It should consider the way in which you responded to the incident, feedback from the incident response team, and the impact of the incident on your business operation.
The following are types of questions you should raise when conducting your review:
Was our documentation sufficiently clear?
Was the information accurate?
Did members of the incident response team understand their roles and responsibilities?
How long did it take to complete different tasks?
Do we need any further measures to prevent similar incidents in the future?
Were there any gaps in our security tooling?
Did we make any mistakes that delayed recovery time?
Did the incident reveal any violation of compliance requirements?
Business continuity and disaster recovery (BCDR)
Business continuity (BC) is the series of contingency measures your organization should have in place to keep mission-critical operations running during a period of disruption, such as a security incident. Disaster recovery (DR), on the other hand, is the set of provisions you make for restoring systems to normal—with the minimum of downtime and impact to your business.
Both disciplines are therefore integral to the success of your response. However, they need to coordinate with your incident management strategy to:
Ensure you trigger BCDR procedures at the most appropriate point in the response lifecycle
Minimize the risk of threat persistence
To meet these objectives, you need to give due consideration to:
The security of any failover system
Backup hygiene practices to prevent infection
Recovery priorities
System dependencies
Tools and technologies
The right tooling is a godsend when you are faced with a live security incident and need to address the threat as quickly as possible. So, to wrap up, we've listed some of the incident response tools and technologies you'll need for effective response, along with the role they play in the response lifecycle.
| Technology | Description | Role in response lifecycle |
|---|---|---|
| Threat detection and response (TDR) | A category of security tools that monitor environments for signs of suspicious activity and provide remediation capabilities to contain and eradicate threats. Examples of TDR technology include endpoint detection and response (EDR) and cloud detection and response (CDR). | Detection, investigation, containment, and eradication |
| Security information and event management (SIEM) | An aggregation platform that enriches logs, alert, and event data from disparate sources with contextual information, thereby enhancing visibility and understanding for better incident detection and analysis. | Detection and investigation |
| Security orchestration, automation and response (SOAR) | A security orchestration platform that integrates different security tools, providing streamlined security management through a unified interface. Allows you to create playbooks to perform predefined automated responses. | Detection, investigation, containment, and eradication |
| Intrusion detection and prevention system (IDPS) | A traditional defense system that detects and blocks network-level threats before they reach endpoints. | Detection and investigation |
| Threat intelligence platform (TIP) | An emerging technology that collects and rationalizes external information about known malware and other threats. TIP helps security teams quickly identify the signs of an incident and prioritize their efforts through insights into the latest attack methods adversaries are using. | Detection, investigation, containment, and eradication |
| Risk-based vulnerability management (RBVM) | A security solution that scans your IT environment for known vulnerabilities and helps you prioritize remediation activity based on the risk such vulnerabilities pose to your organization. | Containment and eradication |
Wiz for Cloud-Native IR
Wiz offers a comprehensive Cloud Detection and Response (CDR) solution to help organizations effectively detect, investigate, and respond to security incidents in cloud environments. Here are the key aspects of Wiz's approach to cloud incident response:
Contextualized Threat Detection: Wiz correlates threats across real-time signals and cloud activity in a unified view, allowing defenders to rapidly uncover attacker movement in the cloud. This contextualization helps prioritize alerts and reduce false positives, addressing the issue of alert fatigue that many security teams face.
Cloud-Native Monitoring: The platform monitors workload events and cloud activity to detect both known and unknown threats and malicious behavior. This cloud-native approach is crucial, as traditional security solutions often struggle with the dynamic nature of cloud environments.
Automated Response Playbooks: Wiz provides out-of-the-box response playbooks designed to investigate and isolate affected resources using cloud-native capabilities. It also automates evidence collection, enabling security teams to move quickly through containment, eradication, and recovery phases.
Security Graph for Root Cause Analysis: Wiz's Security Graph offers automated Root Cause and Blast Radius Analysis, which is essential for incident response. It helps answer critical questions like how a resource was compromised and what potential paths an attacker could take in the environment. Learn more ->
Cloud Forensics: Wiz enhances its forensics capabilities by providing an automated way to collect important evidence when a resource may have been compromised. This includes copying VM volumes, downloading forensics packages with logs and artifacts, and using runtime sensors to view processes on containers or VMs.
Blast Radius Assessment: The Security Graph allows IR teams to quickly identify the scope of impact, trace attack paths, and spot the root cause of incidents. This is particularly useful for understanding the potential business impact of a compromised resource. Learn more ->
Runtime Monitoring: Wiz continuously monitors workloads for suspicious activity in runtime, adding context to the blast radius analysis. This includes detecting suspicious events performed by machine service accounts or specific users.