



What is data leakage?
Data leakage is the unchecked exfiltration of organizational data to a third party. It occurs through various means such as misconfigured databases, poorly protected network servers, phishing attacks, or even careless data handling.
Data leakage can happen accidentally: 82% of all organizations give third parties wide read access to their environments, which poses major security risks and serious privacy concerns. However, data leakage also occurs due to malicious activities including hacking, phishing, or insider threats where employees intentionally steal data.
Potential impacts of data leakage
Data leakage can have profound and far-reaching impacts:
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
The rising threat of machine learning (ML) leakage
When training a model using a data set different from that of a large language model (LLM), machine learning or artificial intelligence (AI) bias can occur. This situation typically arises due to a mismanagement of the preprocessing phase of ML development. A typical example of ML leakage is using the mean and standard deviation of an entire training dataset instead of the entire training subset.
Data leakage occurs in machine learning models through target leakage or train-test contamination. In the latter, the data intended for testing the model leaks into the training set. If a model is exposed to test data during training, its performance metrics will be misleadingly high.
In target leakage, subsets used for training include information unavailable at the prediction phase of ML development. Although LLMs perform well under this scenario, they give stakeholders a false sense of model efficacy, leading to poor performance in real-world applications.


Common causes of data leakage
Data leakage occurs for a variety of reasons; the following are some of the most common.
Human error
Human error can happen at any level within an organization, often without malicious intent. For example, employees may accidentally send sensitive information, such as financial records or personal data, to the wrong email address.
Phishing attacks
Phishing attacks manifest in various forms but have one method: Cybercriminals bait privileged accounts into providing valuable details. For example, attackers can send seemingly legitimate emails asking employees to click on malicious links and log into a given account. By doing so, the employee volunteers their login credentials to the attacker, which is then used for one or several malicious purposes.
Poor configuration
Misconfigured databases, cloud services, and software settings create vulnerabilities that expose sensitive data to unauthorized access. Misconfigurations often occur due to oversight, lack of expertise, or failure to follow security best practices. Leaving default settings unchanged, such as default usernames and passwords, can grant easy access to cybercriminals.
Incorrect app settings, failing to apply security patches and updates, and inadequate access controls/permissions settings can also create security holes.
Weak security measures
Weak security measures diminish an organization's security posture. Using simple, easy-to-guess passwords; failing to implement strong password policies; granting excessive permissions and not following the principle of least privilege (PoLP); or reusing passwords across multiple accounts increases the risk of data leakage.
Also, leaving data unencrypted—at rest and in transit—predisposes the data to leakage. Not implementing the principle of least privilege (PoLP) and relying on outdated security protocols/technologies can create gaps in your security framework.
State of AI in the Cloud [2025]
Data leakage is a major risk, especially in AI systems. Wiz’s State of AI Security Report 2025 uncovers how organizations are managing data exposure risks in AI, including vulnerabilities in AI-as-a-service providers.
Get the report

Strategies to prevent leakage
1. Data Preprocessing and Sanitization
Anonymization and Redaction
Anonymization involves altering or removing personally identifiable information (PII) and sensitive data to prevent it from being linked back to individuals. Redaction is a more specific process that involves removing or obscuring sensitive parts of the data, such as credit card numbers, Social Security numbers, or addresses.
Without proper anonymization and redaction, AI models can "memorize" sensitive data from the training set, which could be inadvertently reproduced in model outputs. This is especially dangerous if the model is used in public or client-facing applications.
Best Practices:
Use tokenization, hashing, or encryption techniques to anonymize data.
Ensure that any redacted data is permanently removed from both structured (e.g., databases) and unstructured (e.g., text files) datasets before training.
Implement differential privacy (discussed later) to further reduce the risk of individual data exposure.
Data Minimization
Data minimization involves only collecting and using the smallest necessary dataset to achieve the AI model’s objective. The less data collected, the lower the risk of sensitive information being leaked.
Collecting excessive data increases the risk surface for breaches and the chances of leaking sensitive information. By using only what's necessary, you also ensure compliance with privacy regulations like GDPR or CCPA.
Best Practices:
Conduct a data audit to assess which data points are essential for training.
Implement policies to discard non-essential data early in the preprocessing pipeline.
Regularly review the data collection process to ensure that no unnecessary data is being retained.
2. Model Training Safeguards
Proper Data Splitting
Data splitting separates the dataset into training, validation, and test sets. The training set teaches the model, while the validation and test sets ensure the model’s accuracy without overfitting.
If data is improperly split (e.g., the same data is present in both the training and test sets), the model can effectively “memorize” the test set, leading to overestimation of its performance and potential exposure of sensitive information in both training and prediction phases.
Best Practices:
Randomize datasets during splitting to ensure no overlap between the training, validation, and test sets.
Use techniques like k-fold cross-validation to robustly assess model performance without data leakage.
Regularization Techniques
Regularization techniques are employed during training to prevent overfitting, where the model becomes too specific to the training data and learns to “memorize” rather than generalize from it. Overfitting increases the likelihood of data leakage since the model can memorize sensitive information from the training data and reproduce it during inference.
Best Practices:
Dropout: Randomly drop certain units (neurons) from the neural network during training, forcing the model to generalize rather than memorize patterns.
Weight Decay (L2 Regularization): Penalize large weights during training to prevent the model from fitting too closely to the training data.
Early Stopping: Monitor model performance on a validation set and stop training when the model's performance starts to degrade due to overfitting.
Differential Privacy
Differential privacy adds controlled noise to the data or model outputs, ensuring that it becomes difficult for attackers to extract information about any individual data point in the dataset.
By applying differential privacy, AI models are less likely to leak details of specific individuals during training or prediction, providing a layer of protection against adversarial attacks or unintended data leakage.
Best Practices:
Add Gaussian or Laplace noise to training data, model gradients, or final predictions to obscure individual data contributions.
Use frameworks like TensorFlow Privacy or PySyft to apply differential privacy in practice.
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. Secure Model Deployment
Tenant isolation
In a multi-tenant environment, tenant isolation creates a logical or physical boundary between each tenant's data, making it impossible for one tenant to access or manipulate another's sensitive information. By isolating each tenant's data, businesses can prevent unauthorized access, reduce the risk of data breaches, and ensure compliance with data protection regulations.
Tenant isolation provides an additional layer of security, giving organizations peace of mind knowing that their sensitive AI training data is protected from potential leaks or unauthorized access.
Best Practices:
Logical Separation: Use virtualization techniques like containers or virtual machines (VMs) to ensure that each tenant’s data and processing are isolated from one another.
Access Controls: Implement strict access control policies to ensure that each tenant can only access their own data and resources.
Encryption and Key Management: Use tenant-specific encryption keys to further segregate data, ensuring that even if a breach occurs, data from other tenants remains secure.
Resource Throttling and Monitoring: Prevent tenants from exhausting shared resources by enforcing resource limits and monitoring for anomalous behavior that might compromise the system’s isolation.
Output Sanitization
Output sanitization involves implementing checks and filters on model outputs to prevent the accidental exposure of sensitive data, especially in natural language processing (NLP) and generative models.
In some cases, the model might reproduce sensitive information it encountered during training (e.g., names or credit card numbers). Sanitizing outputs ensures that no sensitive data is exposed.
Best Practices:
Use pattern-matching algorithms to identify and redact PII (e.g., email addresses, phone numbers) in model outputs.
Set thresholds on probabilistic outputs to prevent the model from overly confident predictions that could expose sensitive details.
4. Organizational Practices
Employee Training
Employee training ensures that all individuals involved in the development, deployment, and maintenance of AI models understand the risks of data leakage and the best practices to mitigate them. Many data breaches occur due to human error or oversight. Proper training can prevent accidental exposure of sensitive information or model vulnerabilities.
Best Practices:
Provide regular cybersecurity and data privacy training for all employees handling AI models and sensitive data.
Update staff on emerging AI security risks and new preventive measures.
Data Governance Policies
Data governance policies set clear guidelines for how data should be collected, processed, stored, and accessed across the organization, ensuring that security practices are consistently applied.
A well-defined governance policy ensures that data handling is standardized and compliant with privacy laws like GDPR or HIPAA, reducing the chances of leakage.
Best Practices:
Define data ownership and establish clear protocols for handling sensitive data at every stage of AI development.
Regularly review and update governance policies to reflect new risks and regulatory requirements.
5. Leverage AI Security Posture Management (AI-SPM) tools
AI-SPM solutions provide visibility and control over critical components of AI security, including the data used for training/inference, model integrity, and access to deployed models. By incorporating an AI-SPM tool, organizations can proactively manage the security posture of their AI models, minimizing the risk of data leakage and ensuring robust AI system governance.
How AI-SPM helps prevent ML model leakage:
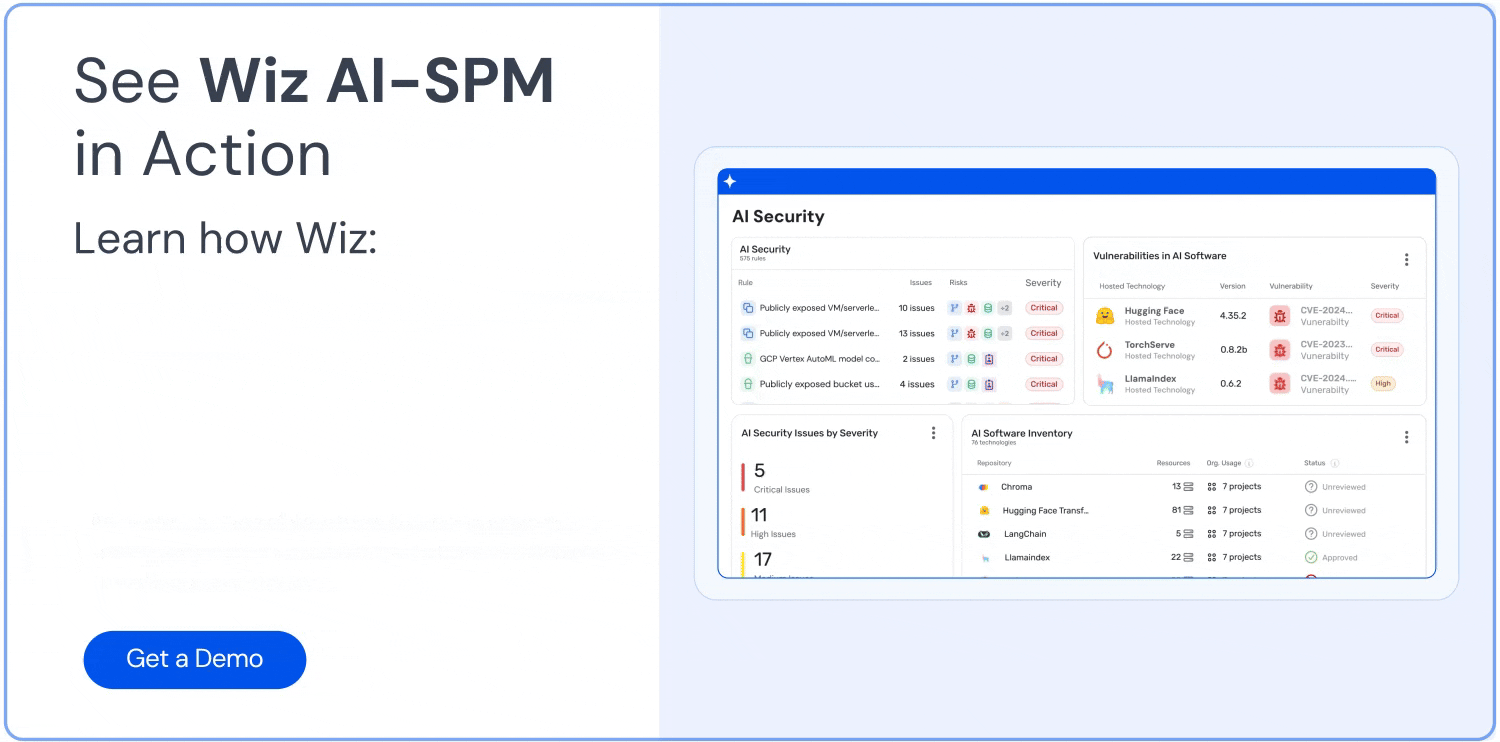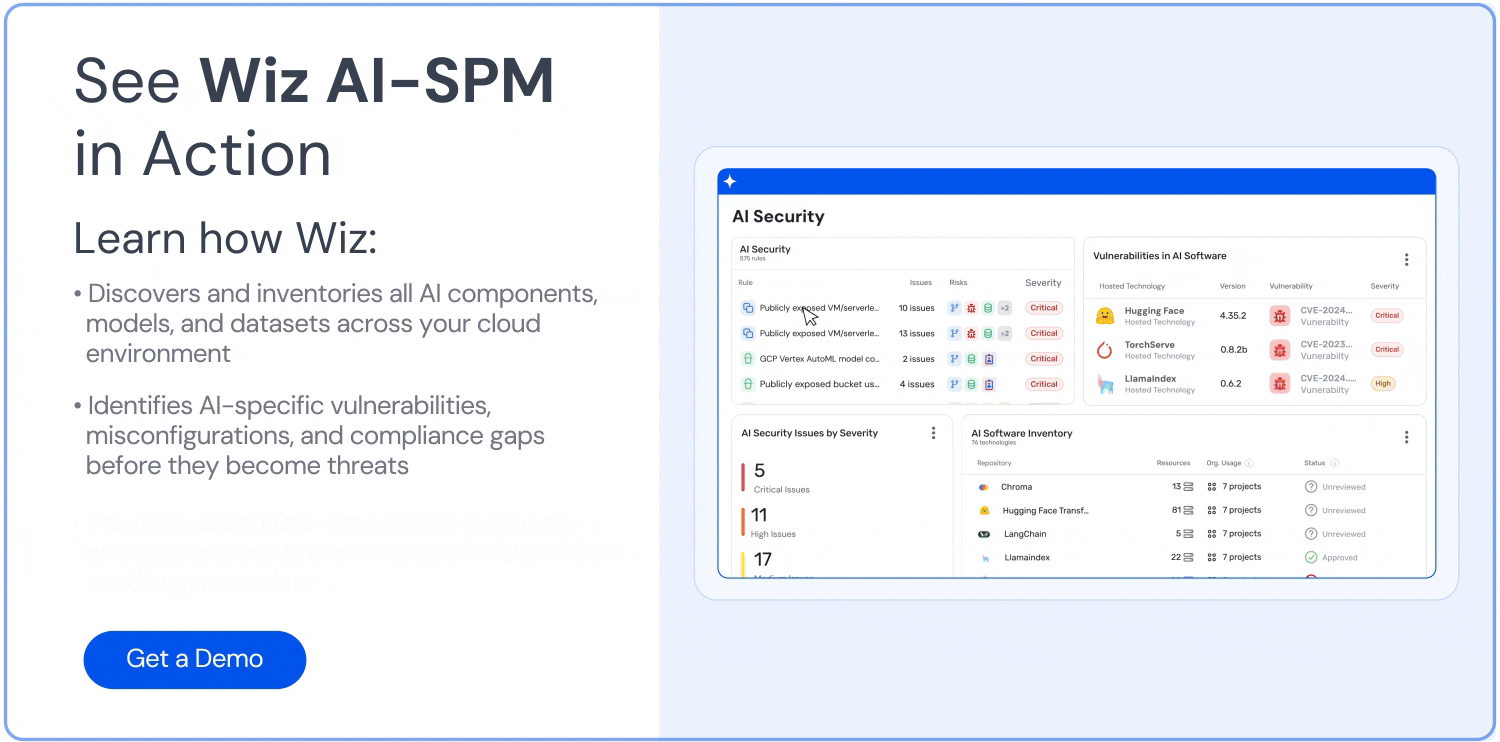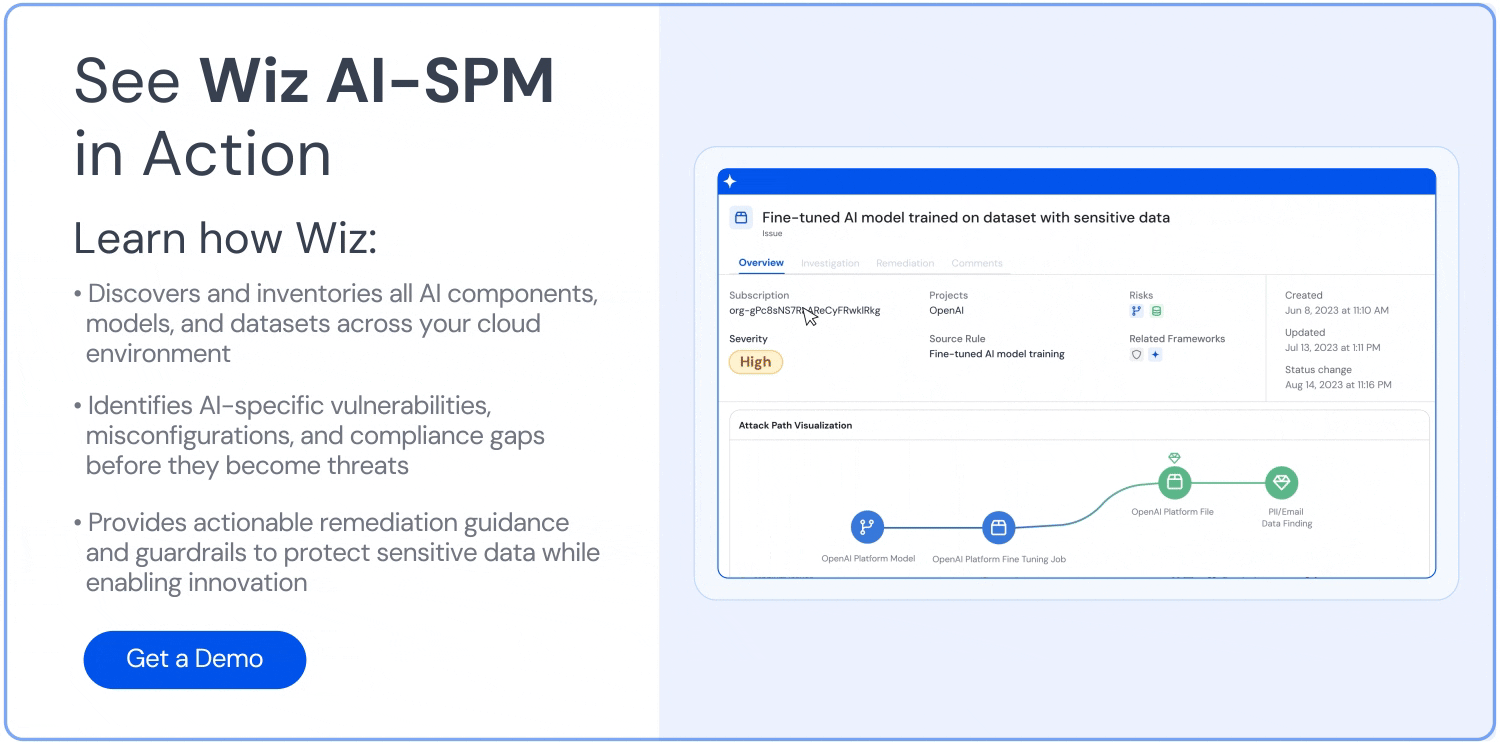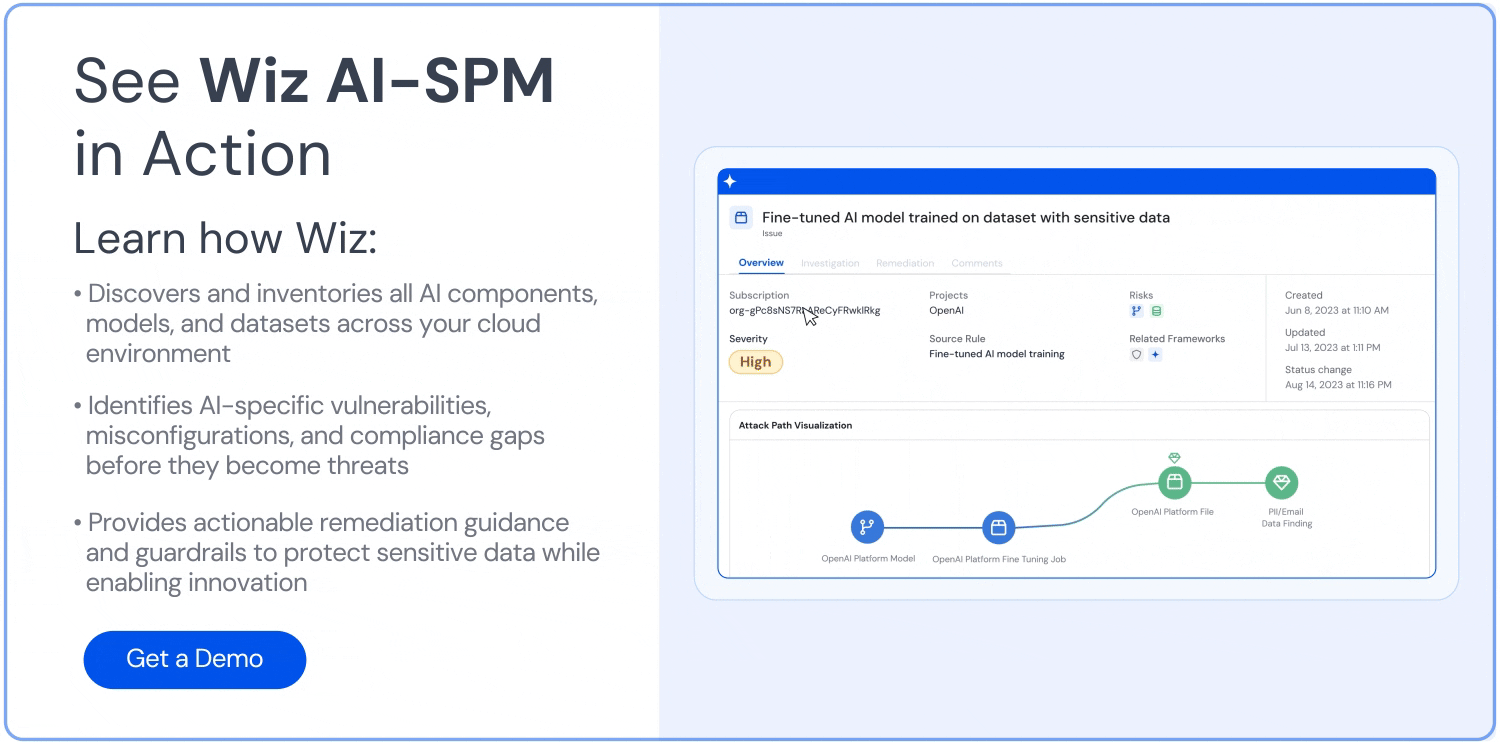
Discover and inventory all AI applications, models, and associated resources
Identify vulnerabilities in the AI supply chain and misconfigurations that could lead to data leakage
Monitor for sensitive data across the AI stack, including training data, libraries, APIs, and data pipelines
Detect anomalies and potential data leakage in real-time
Implement guardrails and security controls specific to AI systems
Conduct regular audits and assessments of AI applications


How Wiz can help
With its comprehensive data security posture management (DSPM), Wiz helps prevent and detect data leakage in the following ways.
Automatically discover and classify data
Wiz continuously monitors for critical data exposure, providing real-time visibility into sensitive information such as PII, PHI, and PCI data. It provides an up-to-date view of where data is and how it is being accessed (even in your AI systems with our AI-SPM solution). You can also create custom classifiers to identify sensitive data that is unique to your business. These features further facilitate swift response to security incidents, avoiding damage altogether or significantly minimizing the potential blast radius.
Data risk assessment
Wiz detects attack paths by correlating data findings to vulnerabilities, misconfigurations, identities, and exposures that can be exploited. You can then shut these exposure paths down before threat actors can exploit them. Wiz also visualizes and prioritizes exposure risks based on their impact and severity rate, ensuring that the most critical issues are dealt with first.
Furthermore, Wiz aids data governance by detecting—and displaying—who can access what data.
Data security for AI training data
Wiz provides a full risk assessment of your data assets, including the chance for data leakage, with out-of-the-box DSPM AI controls. Our tools provide a holistic view of your organization’s data security posture, highlight areas that need attention, and offer detailed guidance to bolster your security measures and remediate issues fast.
Continuous compliance assessment
Wiz’s continuous compliance assessment ensures your organization's security posture aligns with industry standards and regulatory requirements in real time. Our platform scans for misconfigurations and vulnerabilities, providing actionable recommendations for remediation and automating compliance reporting.
With Wiz DSPM features and functionalities, you can effectively help your organization mitigate the risks of data leakage and ensure robust data protection and compliance. Book a demo today to learn more.