What is LLM Jacking?
LLM jacking is an attack technique that cybercriminals use to manipulate and exploit an enterprise’s cloud-based LLMs (large language models). LLM jacking involves stealing and selling cloud account credentials to enable malicious access to an enterprise’s LLMs while the victim unknowingly covers the consumption costs.
Our research shows that 7 out of 10 businesses leverage artificial intelligence (AI) services, including generative AI (GenAI) offerings from cloud providers including Amazon Bedrock and SageMaker, Google Vertex AI, and Azure OpenAI Service. These services provide developers access to LLM models like Claude, Jurassic-2, the GPT series, DALL-E, OpenAI Codex, Amazon Titan, and Stable Diffusion. By selling access to LLM models, cybercriminals can start a damaging domino effect across multiple organizational pillars.
While threat actors may conduct LLM jacking attacks to steal data themselves, they often sell LLM access to a larger web of cybercriminals. This is even more dangerous because it extends the scope and scale of potential attacks. By hijacking an enterprise’s LLMs, any cybercriminal that purchases cloud-based LLM credentials can orchestrate unique attacks.
LLM Security Best Practices [Cheat Sheet]
This 7-page checklist offers practical, implementation-ready steps to guide you in securing LLMs across their lifecycle, mapped to real-world threats.

What are the potential consequences of an LLM jacking attack?
Increased consumption costs
When cybercriminals conduct LLM jacking attacks, excessive consumption costs are the first repercussion. This is because cloud-based GenAI and LLM services, as beneficial as they are, can be quite expensive for businesses to host. Therefore, when adversaries sell access to these services and enable covert and malicious usage, the costs can add up. According to researchers, LLM jacking attacks can result in consumption costs of up to $46,000 per day. This amount can fluctuate depending on LLM pricing models.
Weaponization of enterprise LLMs
If an enterprise’s LLM models lack integrity or don’t feature robust guardrails, they can generate damaging outputs. By hijacking organization-specific LLM models or reverse-engineering LLM architectures, adversaries can use an enterprise’s GenAI ecosystem as a weapon for malicious attacks and activities. For example, by manipulating enterprise LLMs, threat actors can make them generate false or malicious outputs for both backend and customer-facing use cases. It can take enterprises a while to identify this kind of hijack, by which time the damage is often done.
Exacerbation of existing LLM vulnerabilities
LLM adoption features inherent security challenges. According to OWASP, the top 10 LLM vulnerabilities include prompt injection, training data poisoning, model denial of service, sensitive information disclosure, excessive agency, overreliance, and model theft. When cybercriminals use LLM jacking attacks, they significantly exacerbate the inherent risks and vulnerabilities associated with LLMs.
High-level snowfall effect
Considering how rapidly businesses are incorporating GenAI and LLMs in mission-critical contexts, LLM jacking attacks can have serious high-level and long-term implications. For instance, LLM jacking can expand an enterprise’s attack surface, resulting in data breaches and other major exploits.
Furthermore, since AI proficiency is a critical reputational metric for today’s enterprises, LLM jacking attacks can cause a loss of trust and respect from peers and the public. Don’t forget the devastating financial fallouts of LLM jacking, which include lower profit margins, data loss, downtime costs, and legal fees.
How do LLM jacking attacks work?
In principle, LLM jacking is similar to attacks like cryptojacking, where threat actors secretly mine cryptocurrency using an enterprise’s processing power. In both cases, threat actors use an organization’s resources and infrastructure against them. However, with LLM jacking attacks, the hacker’s crosshairs are firmly on cloud-hosted LLM services and cloud account owners.
To understand how LLM jacking works, let’s look at it from two perspectives. First, we’ll explore how businesses use LLMs, and then we’ll move on to how threat actors exploit them.
How do businesses interact with cloud-hosted LLM services?
Most cloud providers furnish enterprises with an easy-to-use interface and simple functions designed for agile LLM adoption. However, these third-party models aren’t automatically ready for use. First, they require activation.
To activate LLMs, developers have to make a request to their cloud providers. Developers can make requests in a few different ways, including via simple request forms. Once developers submit these request forms, cloud providers can quickly activate LLM services. Post-activation, developers can interact with their cloud-based LLMs using command line interface (CLI) commands.
Keep in mind that the process of sending an activation request form to a cloud provider isn’t protected by a bulletproof layer of security. Threat actors can easily do the same, so enterprises must focus on additional kinds of AI and LLM security.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

How do threat actors conduct LLM jacking attacks?
Now that you understand how businesses typically interact with cloud-hosted LLM services, let’s look at how threat actors facilitate LLM jacking attacks.
Here are the steps threat actors take to orchestrate an LLM jacking attack:
To sell cloud credentials, threat actors have to steal them first. When researchers first uncovered LLM jacking attack techniques, they traced the stolen credentials to a system using a vulnerable version of Laravel (CVE-2021-3129).
Once a threat actor steals credentials from a vulnerable system, they can sell them on illicit marketplaces to other cybercriminals who can purchase and leverage them for more advanced attacks.
With stolen cloud credentials in hand, threat actors need to assess their access and administrative privileges. To stealthily evaluate the limits of their cloud access privileges, cyberattackers can leverage the
InvokeModel APIcall.Even though the
InvokeModel APIcall is a valid request, threat actors can elicit a “ValidationException” error by setting themax_tokens_to_sampleto -1. This step is simply to ascertain whether the stolen credentials can access LLM services. Conversely, if an “AccessDenied” error pops up, threat actors then know that the stolen credentials don't have exploitable access privileges.
Adversaries can also invoke GetModelInvocationLoggingConfiguration to figure out the configuration settings on an enterprise’s cloud-hosted AI services. Remember that this step depends on the guardrails and capabilities of individual cloud providers and services. That’s why, in some cases, threat actors may not have complete visibility into an enterprise’s LLM inputs and outputs.
Conducting an LLM jacking attack doesn’t guarantee monetization for threat actors. However, there are some ways threat actors can make sure that LLM jacking is profitable. During an autopsy of an LLM jacking attack, researchers discovered that adversaries can potentially use the open-source OAI Reverse Proxy server as a centralized panel to manage stolen cloud credentials with LLM access privileges.
Once threat actors monetize their LLM jacking attacks and sell access to an enterprise’s LLM models, there’s no way to predict the kind of damage that can ensue. Other adversaries from different backgrounds and with diverse motives can purchase LLM access and use an enterprise’s GenAI infrastructure without their knowledge. While the consequences of LLM jacking attacks may initially stay hidden, the fallout can be catastrophic.


LLM jacking prevention and detection tactics
Here are some powerful ways enterprises can protect themselves from LLM jacking attacks:
Prevention Tactics
Robust Model Training:
Diverse and high-quality datasets: Ensure the model is trained on a wide range of data to prevent biases and vulnerabilities.
Adversarial training: Expose the model to malicious inputs to improve its resilience.
Reinforcement learning from human feedback (RLHF): Align the model's outputs with human values and expectations.
Strict Input Validation:
Filtering: Implement filters to block harmful or malicious prompts.
Sanitization: Cleanse inputs to remove potentially harmful elements.
Rate limiting: Limit the number of requests to prevent abuse.
Regular Model Auditing:
Vulnerability assessments: Identify potential weaknesses in the model.
Bias detection: Monitor for unintended biases in the model's outputs.
Performance monitoring: Track model performance over time to detect anomalies.
Transparent Model Documentation:
Clear guidelines: Provide clear instructions on how to use the model responsibly.
Limitations: Communicate the model's limitations and potential biases.
Continuous Learning and Adaptation:
Stay informed: Keep up-to-date on the latest LLM threats and countermeasures.
Model updates: Regularly update the model to address new vulnerabilities.
Detection Tactics
Anomaly Detection:
Outlier identification: Identify unusual or unexpected model behaviors.
Statistical analysis: Use statistical methods to detect deviations from normal patterns.
Content Monitoring:
Keyword filtering: Monitor outputs for specific keywords or phrases associated with harmful content.
Sentiment analysis: Analyze the sentiment of the generated content to identify potential issues.
Style analysis: Detect anomalies in the writing style of the generated content.
User Behavior Analysis:
Unusual patterns: Identify abnormal user behavior, such as rapid-fire requests or repetitive prompts.
Account monitoring: Monitor user accounts for suspicious activity.
Human-in-the-Loop Verification:
Quality assurance: Employ human reviewers to assess the quality and safety of generated content.
Feedback mechanisms: Collect user feedback to identify potential issues.
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

How Wiz can prevent LLM jacking attacks
Wiz’s groundbreaking AI-SPM tool solution can help prevent and mitigate LLM jacking attacks from escalating into large-scale disasters. Wiz AI-SPM can help defend against LLM jacking in several ways:
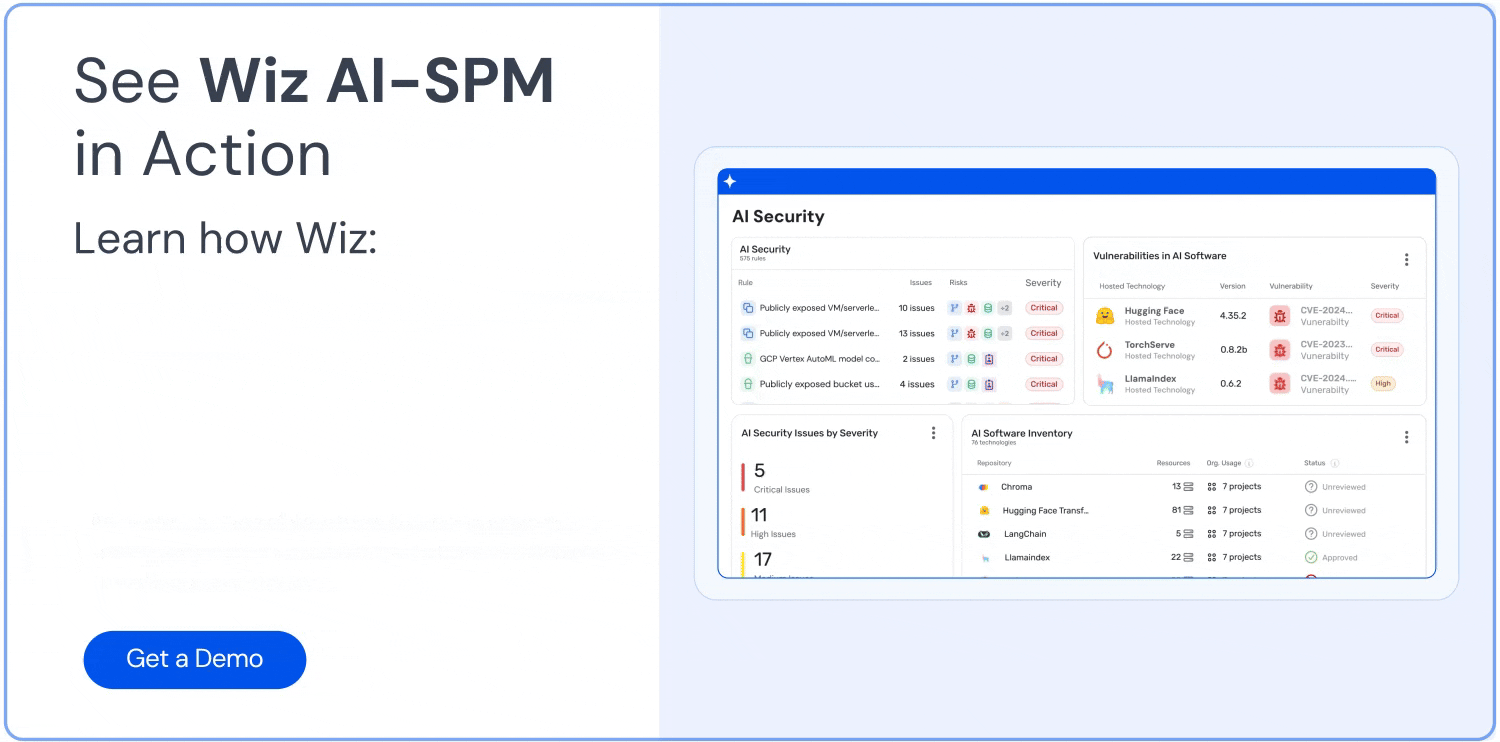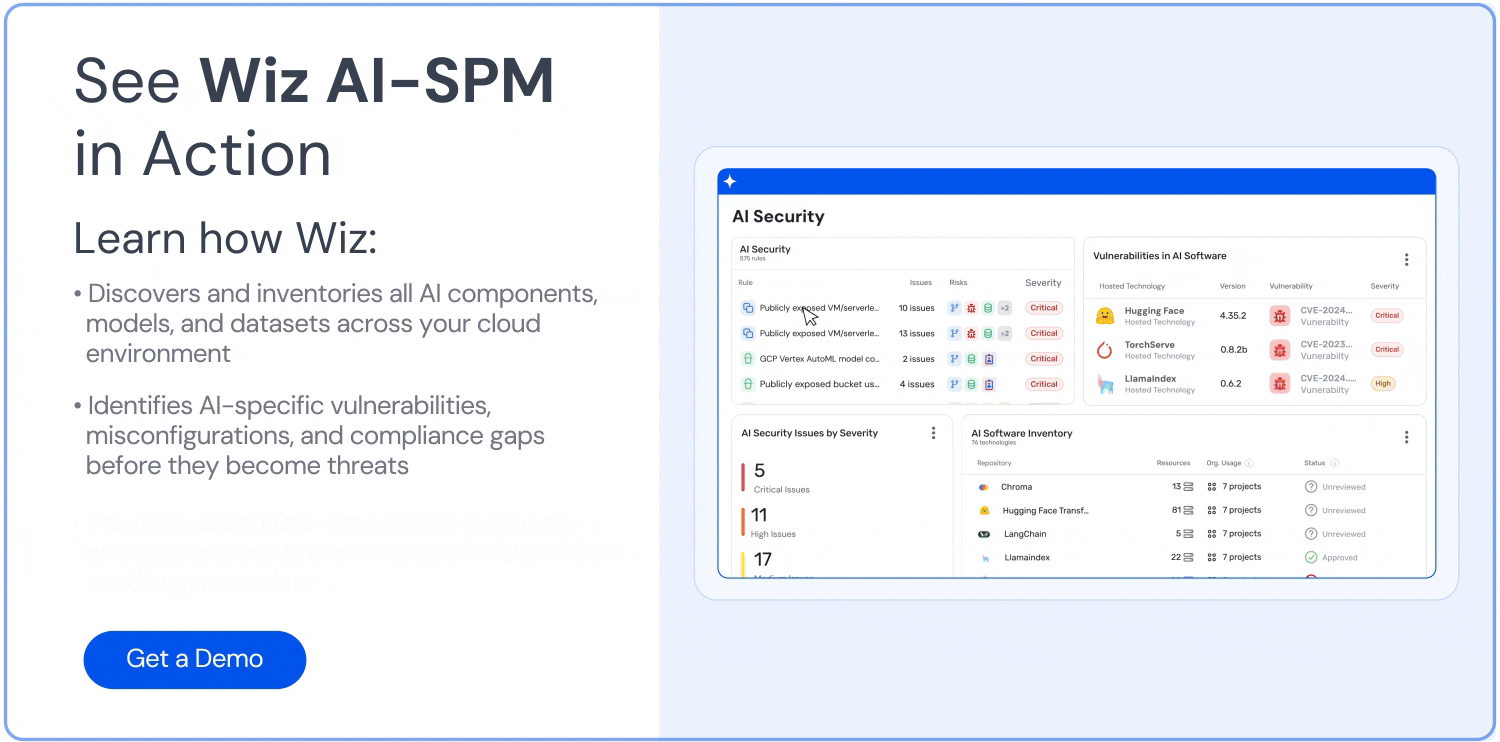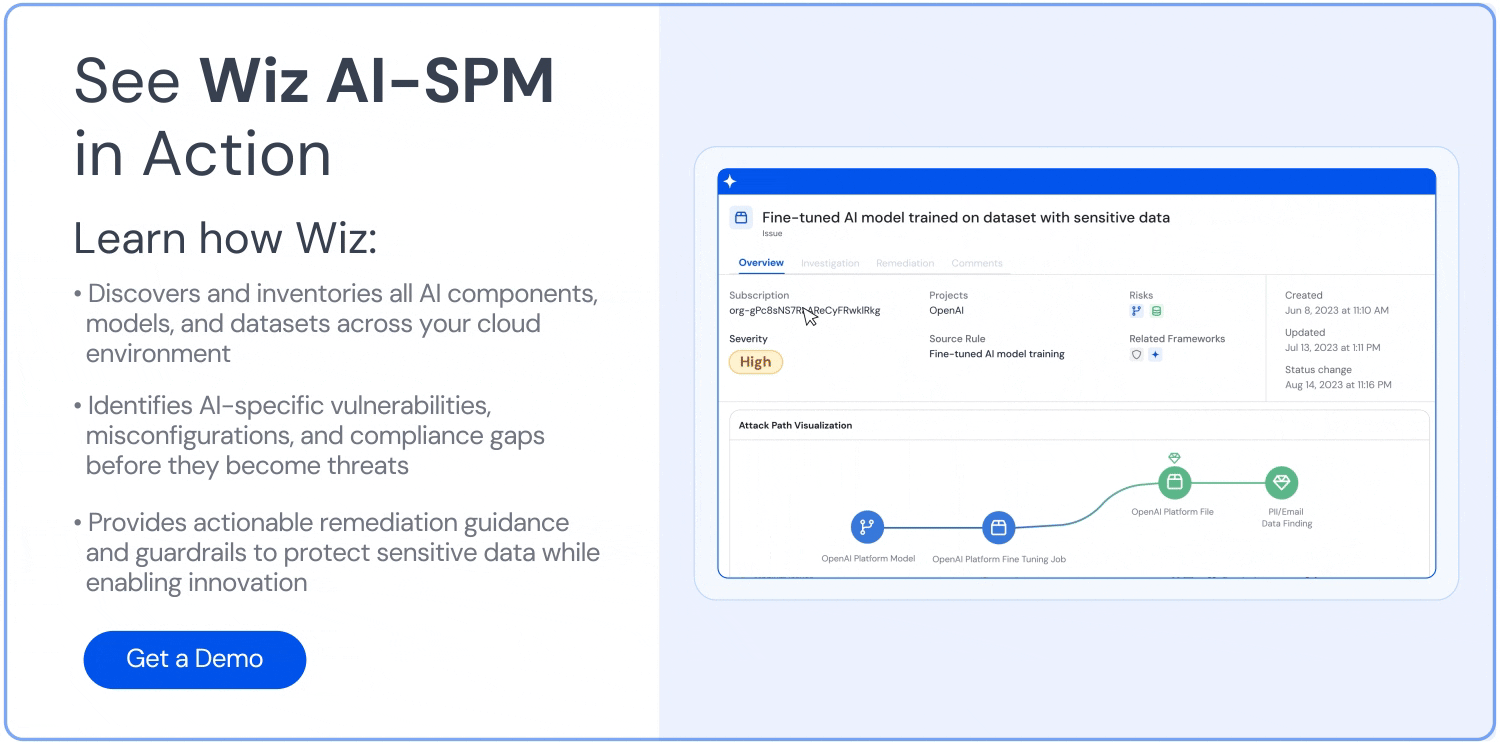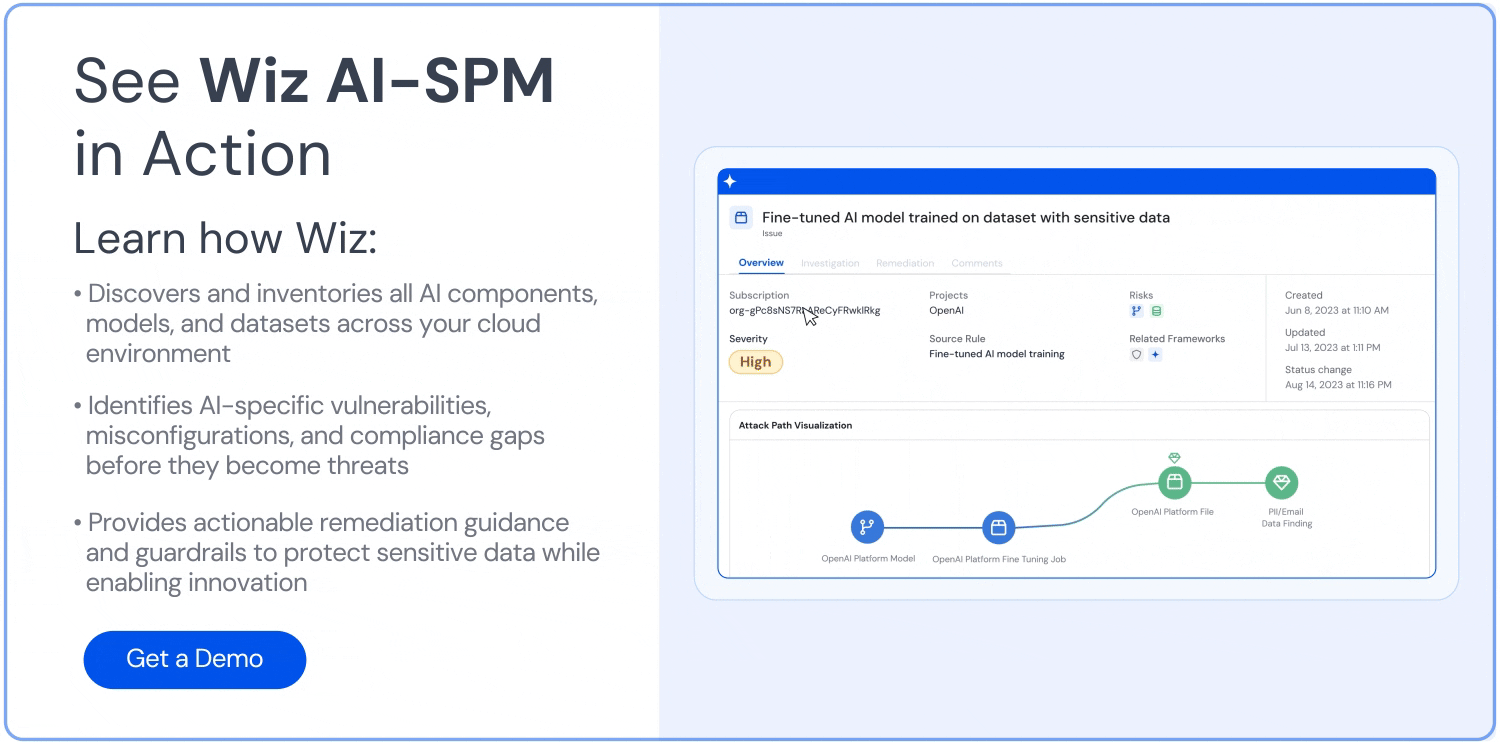
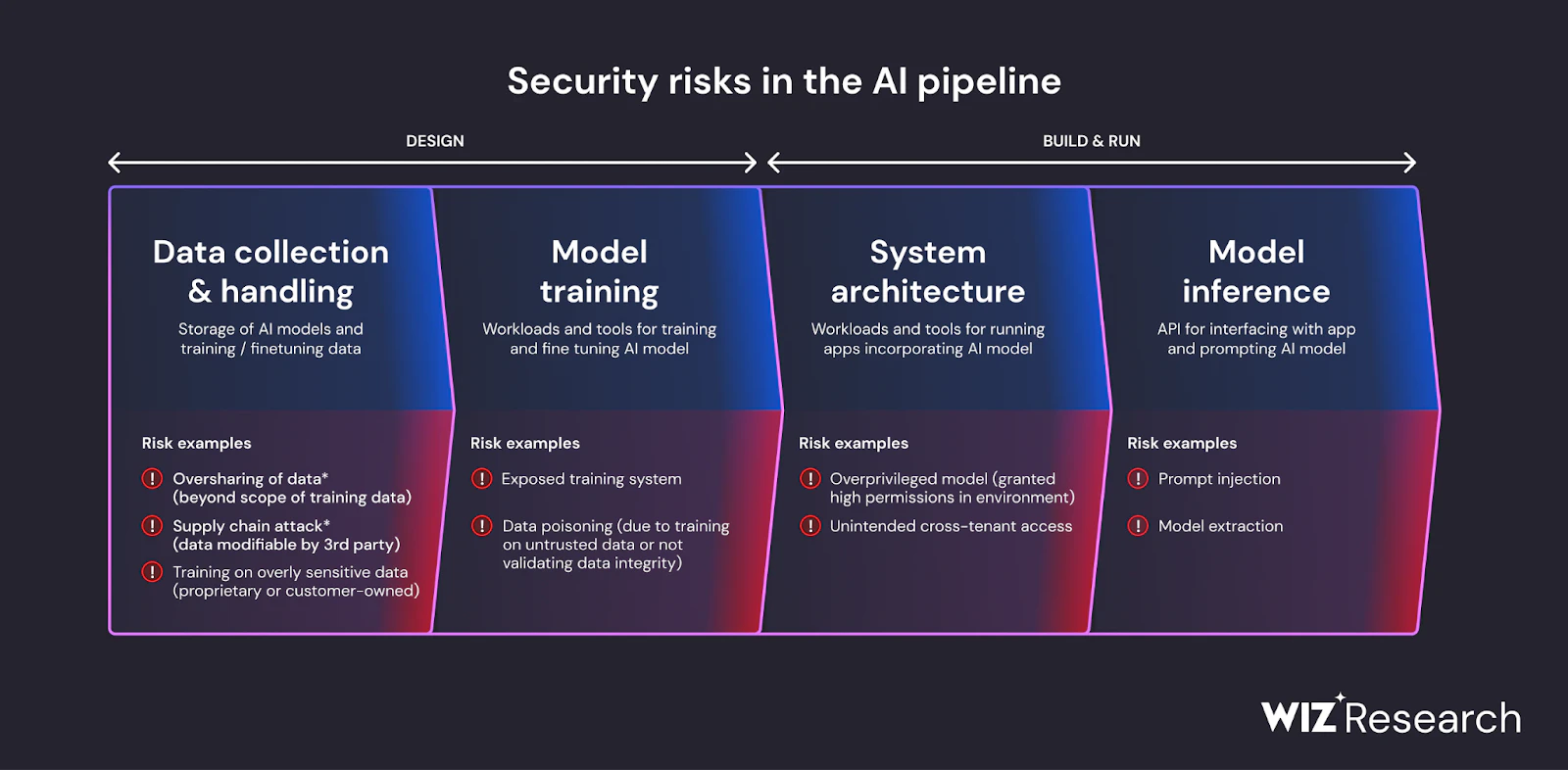
Comprehensive visibility: Wiz AI-SPM provides full-stack visibility into AI pipelines, including AI services, technologies, and SDKs, without requiring any agents. This visibility helps organizations detect and monitor all AI components in their environment, including LLMs, making it harder for attackers to exploit unknown or shadow AI resources.
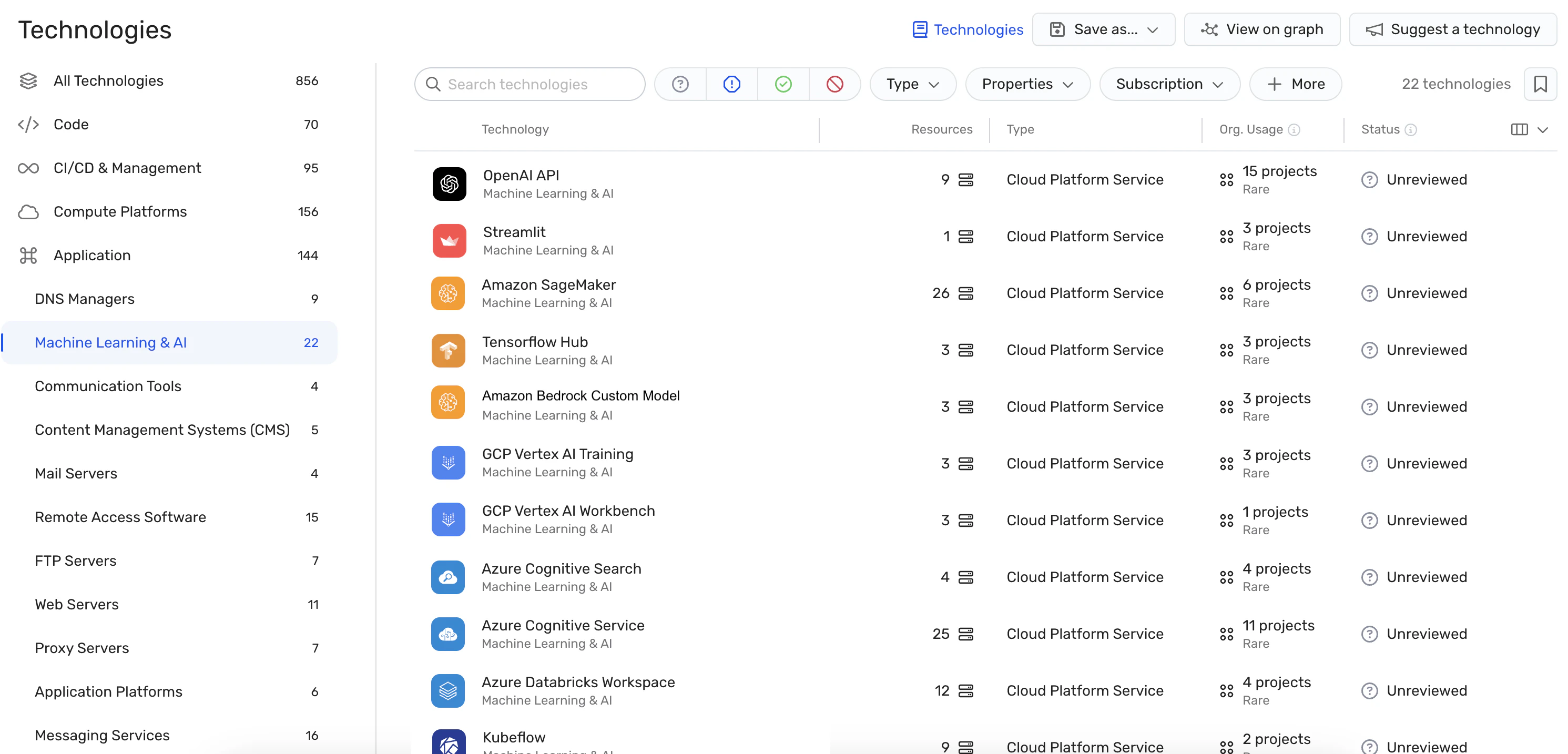
Misconfigurations detection: The platform enforces AI security best practices by detecting misconfigurations in AI services with built-in rules. This can help prevent vulnerabilities that could be exploited in LLM jacking attacks.
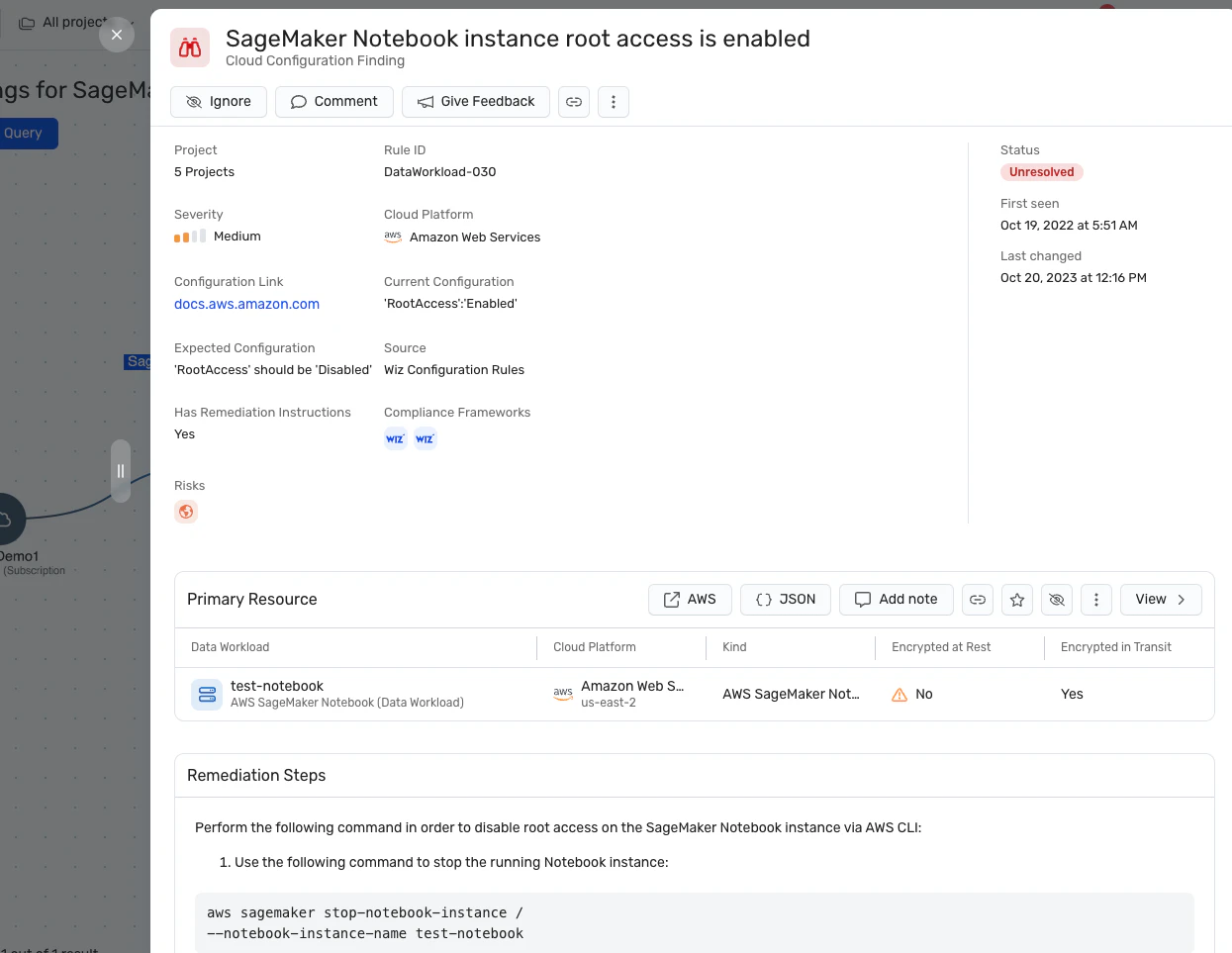
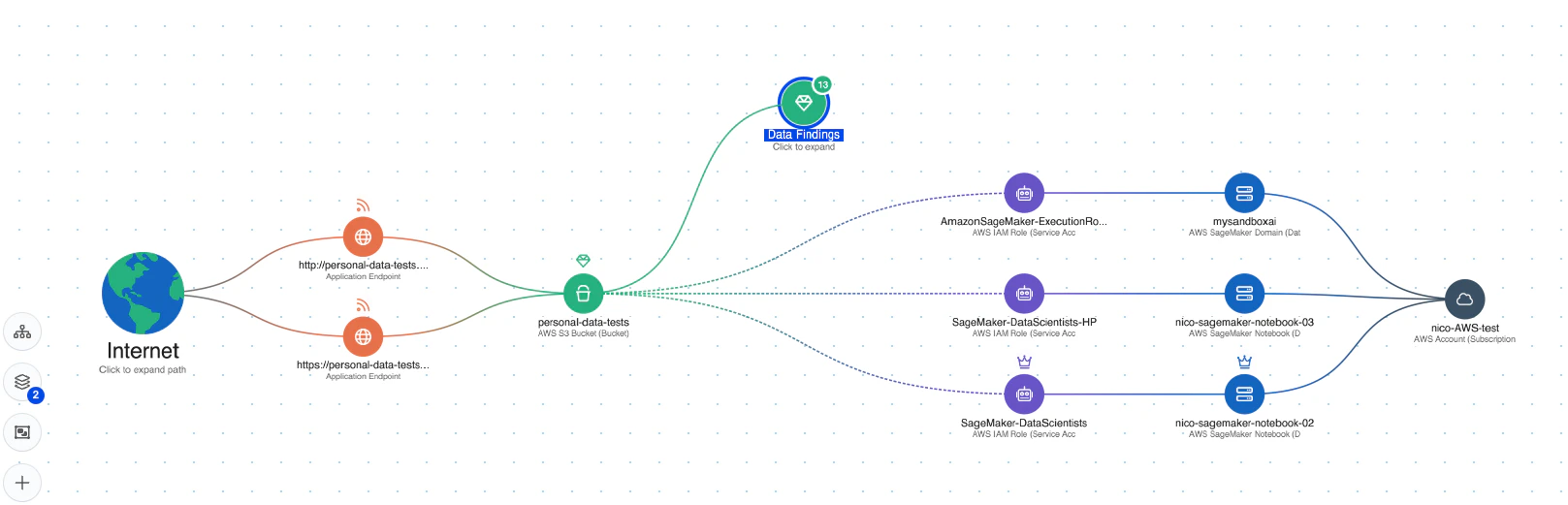
Attack path analysis: Wiz AI-SPM proactively identifies and removes attack paths to AI models by assessing vulnerabilities, identities, internet exposures, data, misconfigurations, and secrets. This comprehensive analysis can help prevent potential entry points for LLM jacking attempts.
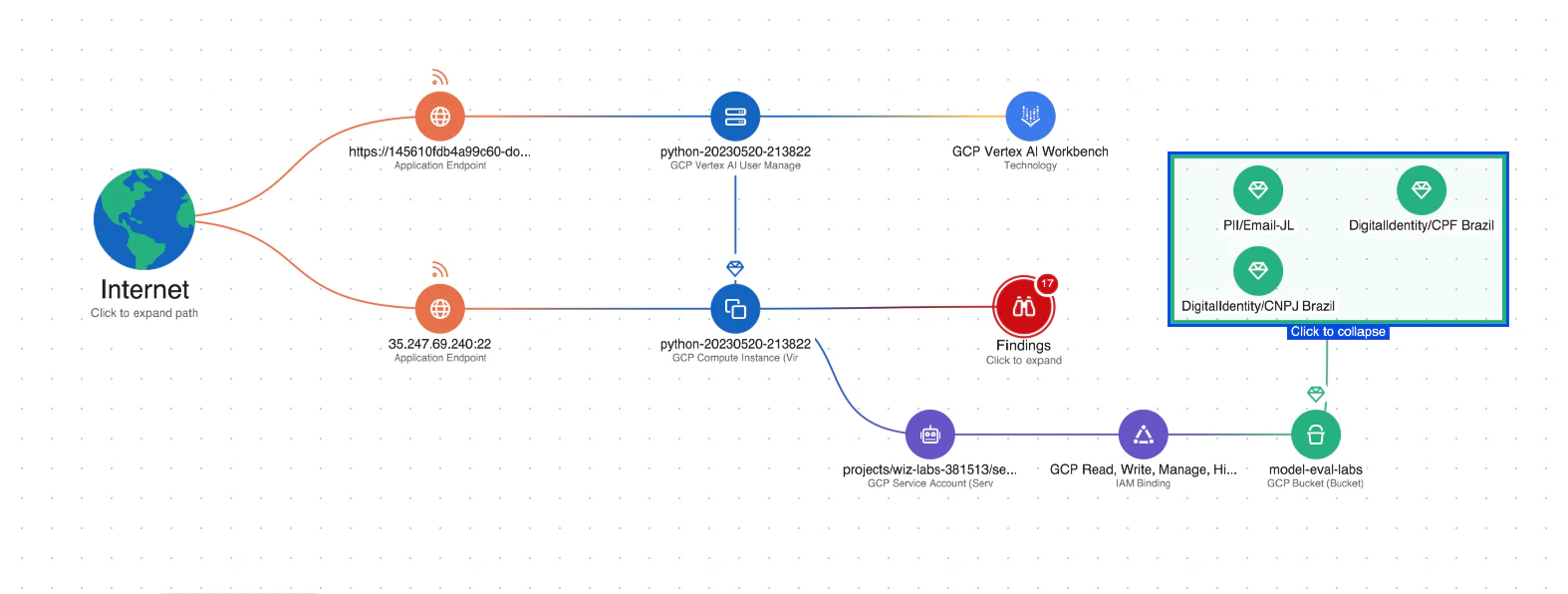
Data security for AI: The platform includes Data Security Posture Management (DSPM) capabilities specifically for AI, which can automatically detect sensitive training data and remove attack paths to it. This helps protect against data leakage that could be used in LLM jacking attacks.
Real-time threat detection: Wiz AI-SPM offers runtime protection against suspicious behavior originating from AI models. This capability can help detect and respond to LLM jacking attempts in real-time, minimizing the potential impact.
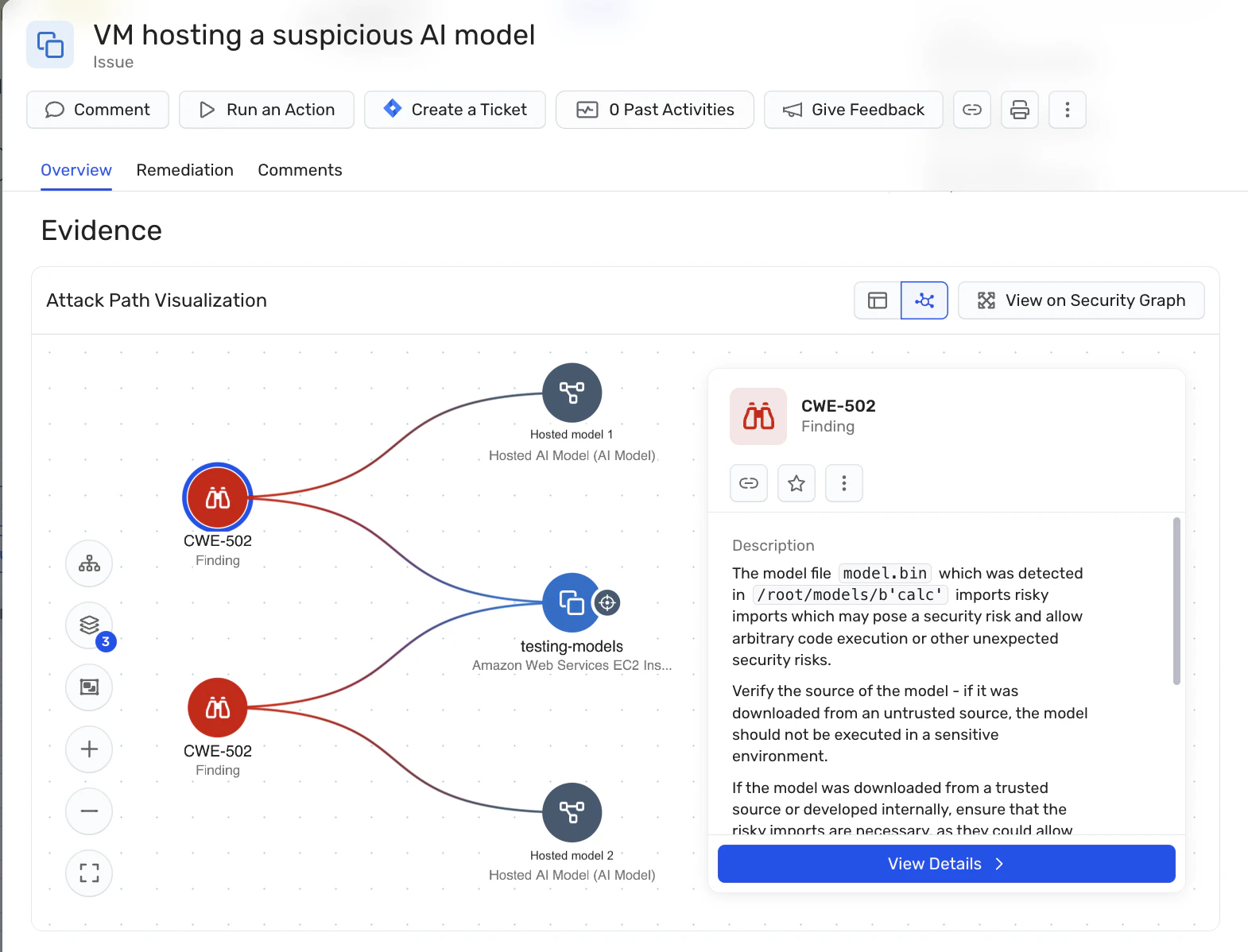
Model scanning: The platform supports identification and scanning of hosted AI models, allowing organizations to detect malicious models that could be used in LLM jacking attacks. This is particularly important for organizations that self-host AI models, as it helps address supply chain risks associated with open-source models.
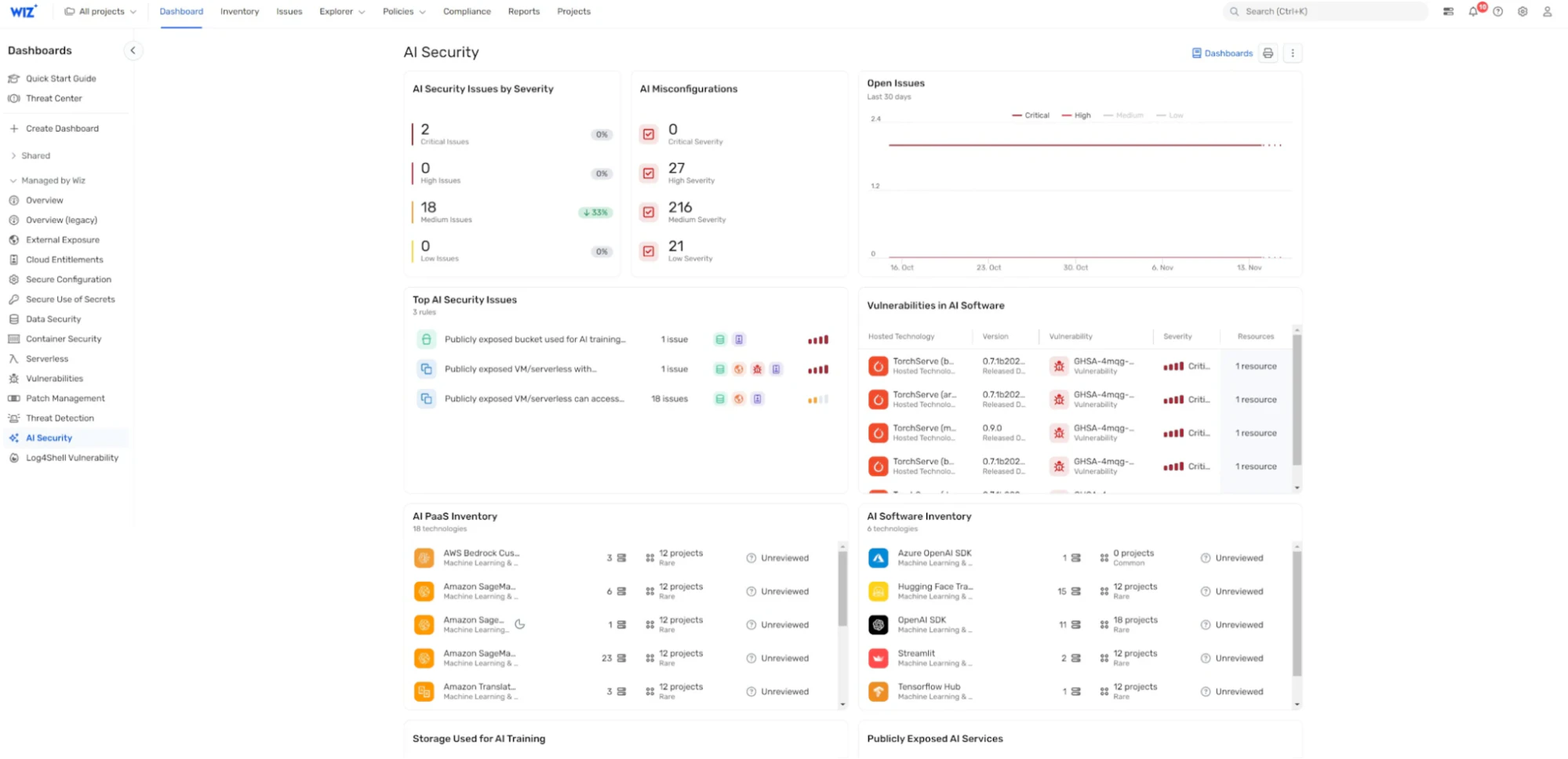
AI security dashboard: Wiz AI-SPM provides an AI security dashboard that offers an overview of the AI security posture with a prioritized queue of risks. This helps AI developers and security teams quickly focus on the most critical issues, potentially including vulnerabilities that could lead to LLM jacking.
By implementing these features, Wiz AI-SPM helps organizations maintain a strong security posture for their AI systems, making it more difficult for attackers to successfully execute LLM jacking attacks and other AI-related threats.