



Introduction & Overview
Ollama is one of the most popular open-source projects for running AI Models, with over 70k stars on GitHub and hundreds of thousands of monthly pulls on Docker Hub. Inspired by Docker, Ollama aims to simplify the process of packaging and deploying AI models.
Wiz Research discovered an easy-to-exploit Remote Code Execution vulnerability in Ollama: CVE-2024-37032, dubbed “Probllama.” This security issue was responsibly disclosed to Ollama’s maintainers and has since been mitigated. Ollama users are encouraged to upgrade their Ollama installation to version 0.1.34 or newer.
Our research indicates that, as of June 10, there are a large number of Ollama instances running a vulnerable version that are exposed to the internet. In this blog post, we will detail what we found and how we found it, as well as mitigation techniques and preventative measures organizations can take moving forward.
AI Security Takeaways
Taken as a whole – and in light of the Wiz Research team’s ongoing focus on the risk inherent to AI systems – our findings underscore the fact that AI security measures have been largely sidelined in favor of focusing on the transformative power of this technology, and its potential to revolutionize the way business gets done.
Organizations are rapidly adopting a variety of new AI tools and infrastructure in an attempt to hone their competitive edge. These tools are often at an early stage of development and lack standardized security features, such as authentication. Additionally, due to their young code base, it is relatively easier to find critical software vulnerabilities, making them perfect targets for potential threat actors. This is a recurring theme in our discoveries – see prior Wiz Research work on AI-as-a-service-providers Hugging Face and Replicate, as well as our State of AI in the Cloud report and last year’s discovery of 38TB of data that was accidentally leaked by AI researchers.
Over the past year, multiple remote code execution (RCE) vulnerabilities were identified in inference servers, including TorchServe, Ray Anyscale, and Ollama. These vulnerabilities could allow attackers to take over self-hosted AI inference servers, steal or modify AI models, and compromise AI applications.
The critical issue is not just the vulnerabilities themselves but the inherent lack of authentication support in these new tools. If exposed to the internet, any attacker can connect to them, steal or modify the AI models, or even execute remote code as a built-in feature (as seen with TorchServe and Ray Anyscale). The lack of authentication support means these tools should never be exposed externally without protective middleware, such as a reverse proxy with authentication. Despite this, when scanning the internet for exposed Ollama servers, our scan revealed over 1,000 exposed instances hosting numerous AI models, including private models not listed in the Ollama public repository, highlighting a significant security gap.
CROC Talks: RCE Vulnerability in Ollama explained
RCE Vulnerability in Ollama explained
Listen now

Mitigation & detection
To exploit this vulnerability, an attacker must send specially crafted HTTP requests to the Ollama API server. In the default Linux installation, the API server binds to localhost, which reduces remote exploitation risk significantly. However, in docker deployments (ollama/ollama), the API server is publicly exposed, and therefore could be exploited remotely.
Wiz customers can use the pre-built query and advisory in the Wiz Threat Center to search for vulnerable instances in their environment.
Explanation and Technical Description
Why research Ollama?
Our research team makes an active effort to contribute to the security of AI services, tooling, and infrastructure, and we also use AI in our research work.
For a different project, we looked to leverage a large-context AI model. Luckily, around that time, Gradient released their Llama3 version which has a context of 1m tokens.
Being one of the most popular open-source projects for running AI Models with over 70k stars on GitHub and hundreds of thousands of monthly pulls on Docker Hub, Ollama seemed to be the simplest way to self-host that model 😊.
Ollama Architecture
Ollama consists of two main components: a client and a server. The server exposes multiple APIs to perform core functions, such as pulling a model from the registry, generating a prediction for a given prompt, etc. The client is what the user interacts with (i.e. the front-end), which could be, for example, a CLI (command-line interface).
While experimenting with Ollama, our team found a critical security vulnerability in an Ollama server. Due to insufficient input validation, it is possible to exploit a Path Traversal vulnerability to arbitrarily overwrite files on the server. This can be further exploited into a full Remote Code Execution as we demonstrate below.
This issue is extremely severe in Docker installations, as the server runs with root privileges and listens on 0.0.0.0 by default – which enables remote exploitation of this vulnerability.
It is important to mention that Ollama does not support authentication out-of-the-box. It is generally recommended to deploy Ollama behind a reverse-proxy to enforce authentication, if the user decides to expose its installation. In practice, our research indicates that there are a large number of installations exposed to the internet without any sort of authentication.
The Vulnerability: Arbitrary File Write via Path Traversal
Ollama’s HTTP server exposes multiple API endpoints that perform various actions.
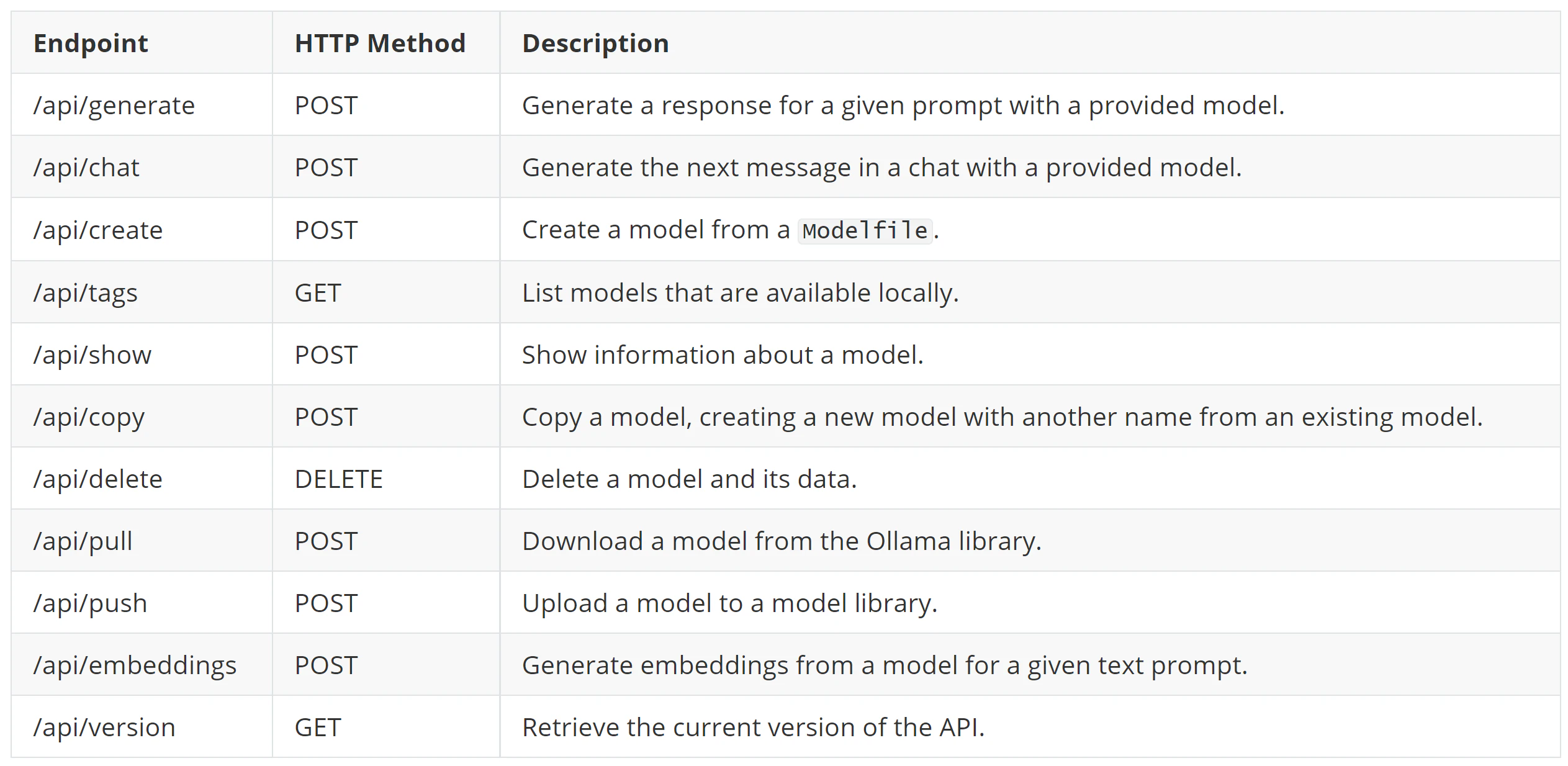
One of the endpoints,/api/pull, can be used to download a model from an Ollama registry.
By default, models are downloaded from Ollama’s official registry (registry.ollama.com), however, it is also possible to fetch models from private registries.

While Ollama's official registry can be considered "trusted," anyone can set up their own registry and host models on it. As researchers, we were interested in this attack surface – are private registries being blindly trusted? What damage could a malicious private registry cause?
What we found is that when pulling a model from a private registry (by querying the http://[victim]:11434/api/pull API endpoint), it is possible to supply a malicious manifest file that contains a path traversal payload in the digest field.
Example:
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"config": {
"mediaType": "application/vnd.docker.container.image.v1+json",
"digest": "../../../../../../../../../../../../../../../../../../../traversal",
"size": 5
},
"layers": [
{
"mediaType": "application/vnd.ollama.image.license",
"digest": "../../../../../../../../../../../../../../../../../../../../../traversal",
"size": 7020
}
]
}
The digest field of a given layer should be equal to the hash of the layer. Among other things, the digest of the layer is also used to store the model file on the disk:
/root/.ollama/models/blobs/sha256-04778965089b91318ad61d0995b7e44fad4b9a9f4e049d7be90932bf8812e828
However, we found that the digest field was used without proper validation, resulting in path traversal when attempting to store it on the filesystem. This issue can be exploited to corrupt arbitrary files on the system.
Achieving Arbitrary File Read
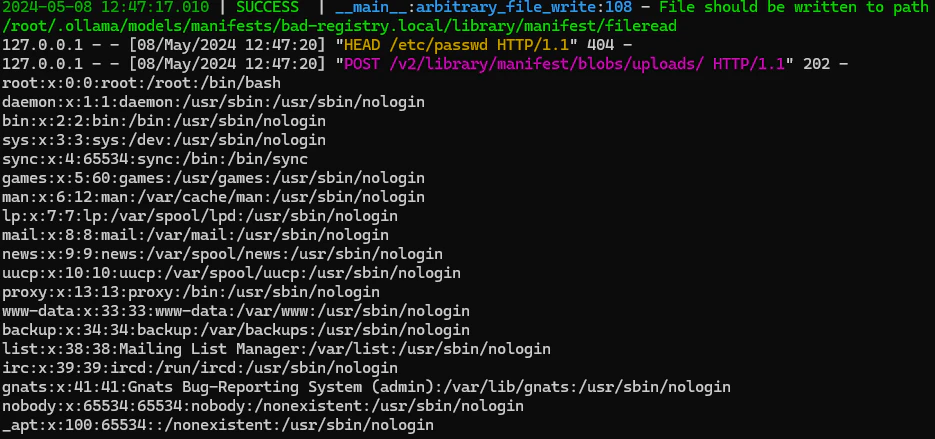
By exploiting the previous issue, we can plant an additional malicious manifest file on the server (e.g/root/.ollama/models/manifests/%ATTACKER_IP%/library/manifest/latest), which effectively registers a new model to the server. We found out that if our model’s manifest contains a traversal payload for the digest of one of its layers, when attempting to push this model to a remote registry via the http://[victim]:11434/api/push endpoint, the server will leak the content of the file specified in the digest field.
Finally, Remote Code Execution
As we mentioned previously, it is possible to exploit the Arbitrary File Write vulnerability to corrupt certain files in the system. In Docker installations, it is pretty straightforward to exploit it and achieve Remote Code Execution, as the server runs withroot privileges.
The simplest way we thought of achieving remote-code-execution would be to corrupt ld.so configuration files, specifically /etc/ld.so.preload. This file contains a whitespace -separated list of shared libraries that should be loaded whenever a new process starts. Using our Arbitrary File Write exploit-primitive, we plant our payload as a shared library on the filesystem (/root/bad.so) and then we corrupt etc/ld.so.preload to include it. Finally, we query the /api/chat endpoint on the Ollama API Server, which subsequently creates a new process and thus loads our payload!
Regarding exploitation of instances which do not run with root privileges - we do have a strategy for exploitation that leverages our /Arbitrary File Read primitive. However, it will be left as an exercise for the reader 😊
Conclusions
CVE-2024-37032 is an easy-to-exploit remote code execution that affects modern AI infrastructure. Despite the codebase being relatively new and written in modern programming languages, classic vulnerabilities such as Path Traversal remain an issue.
Security teams should update their Ollama instances to the latest version to mitigate this vulnerability. Furthermore, it is recommended not to expose Ollama to the internet unless it is protected by some sort of authentication mechanism, such a reverse-proxy.
Responsible disclosure timeline
We responsibly disclosed this vulnerability to Ollama’s development team in May 2024. Ollama promptly investigated and addressed the issue while keeping us updated.
May 5, 2024 – Wiz Research reported the issue to Ollama.
May 5, 2024 – Ollama acknowledged the receipt of the report.
May 5, 2024 – Ollama notified Wiz Research that they committed a fix to GitHub.
May 8, 2024 – Ollama released a patched version.
June 24, 2024 – Wiz Research published a blog about the issue.
Ollama committed a fix in about 4 hours after receiving our initial report, demonstrating an impressive response time and commitment to their product security.








