



In writing the Wiz 2023 State of Kubernetes Report, we found that overall container security maturity remains low, yet these environments are appealing targets for attackers and attempts to breach them are on the rise. Moreover, once an attacker gains access, the opportunities for lateral movement and privilege escalation within a cluster are numerous.
In this blog post, we’ll take a closer look at a related subtopic connected to detection in managed and unmanaged Kubernetes (K8s) clusters: Kubernetes audit logs. This discussion builds on content I presented at fwd:cloudsec Europe (the recording link is available here for those who are interested). The talk itself drew inspiration from our implementation of Kubernetes Detection and Response (KDR), where we learned essential lessons about attack detection and prevention in Kubernetes environments. Our KDR implementation highlighted the need for Kubernetes audit logs to detect attacks like those in the DERO cryptojacking campaign, which targeted misconfigured Kubernetes clusters.
Over the course of that effort, we encountered some interesting issues with the K8s audit logs that felt worth sharing with the broader security community. Specifically, I will look at how managing audit logs across multiple Cloud Service Providers (CSPs) and self-hosted clusters presents significant challenges for security teams. Audit logs are critical for detecting attacks, ensuring compliance, and enabling forensic analysis, but their inconsistent handling across environments can lead to gaps. We’ll explore some of the practical difficulties when streaming and managing Kubernetes audit logs across multiple CSPs and unmanaged clusters, highlighting issues like default logging policies, performance considerations, and the impact on detection and forensics.
Challenges of Kubernetes Audit Logging
Kubernetes audit logs are essential for tracking activity within a cluster, allowing you to understand who did what, where, and when. For instance, the following is an audit log event generated because of an anonymous actor listing pods in the cluster:
{
"kind": "Event",
"apiVersion": "audit.k8s.io/v1",
"level": "RequestResponse",
"auditID": "a6029022-4ff0-4c54-97ed-4099d0ca1923",
"stage": "RequestReceived",
"requestURI": "/api/v1/namespaces/default/serviceaccounts?fieldManager=kubectl-create",
"verb": "create",
"user": {
"username": "kubernetes-admin",
"groups": ["system:masters", "system:authenticated"]
},
"sourceIPs": ["172.31.22.88"],
"userAgent": "kubectl/v1.23.6 (linux/amd64) kubernetes/ad33385",
"objectRef": {
"resource": "serviceaccounts",
"namespace": "default",
"apiVersion": "v1"
},
"requestReceivedTimestamp": "2022-07-31T08:36:48.679291Z",
"stageTimestamp": "2022-07-31T08:36:48.679291Z"
} The single event answers all the necessary forensics questions:
WHO performed the action (Kubernetes-admin) and from WHICH IP
WHAT action (create)
On WHAT resource (service account in default namespace)
and finally, WHEN this happened (timestamps).
It is important to understand that no other log types (network or general cloud logs) provide the Kubernetes context necessary to fully understand the context around the event.
This brings us to the ideal solution for organizations building their own detection infrastructure: configuring audit logging consistently across all clusters, sending logs to a centralized location like a SIEM (Security Information and Event Management) tool. However, this is easier said than done, particularly when dealing with different cloud providers or self-hosted environments. Here are the primary reasons why:
1. Inconsistent Default Logging Policies
A major pain point when dealing with CSPs is the inconsistency in how Kubernetes audit logging is configured by default. For example, in Amazon EKS (Elastic Kubernetes Service) and Azure AKS (Azure Kubernetes Service), audit logging is disabled by default. Administrators must manually enable it, typically through the provider’s API. This additional configuration step can lead to clusters running without audit logging enabled, leaving security teams blind to potentially malicious activity.
Contrast this with Oracle’s Kubernetes Engine, where audit logs are turned on by default, but users have no option to disable them. While this ensures that logs are always available, lack of control can introduce issues around unnecessary storage and costs. These discrepancies make it difficult to achieve uniform configuration settings across the cluster fleet. This should probably be done in an automated way while using relevant cloud API calls.
2. Vendor-Specific Log Formats
Another challenge arises from the different log formats used by CSPs. While Kubernetes has a standard format for audit logs, many cloud vendors modify or extend this format for their managed services. Google Kubernetes Engine (GKE) and OKE are prime examples: they heavily customize the audit logs, stripping some of the original Kubernetes fields and introducing its own logging format. As a result, a rule set designed to detect suspicious behavior on a vanilla Kubernetes cluster will not work correctly on GKE, leading to missed detections. For example, this is how two events look like side by side – GKE format versus the original K8s vanilla format:
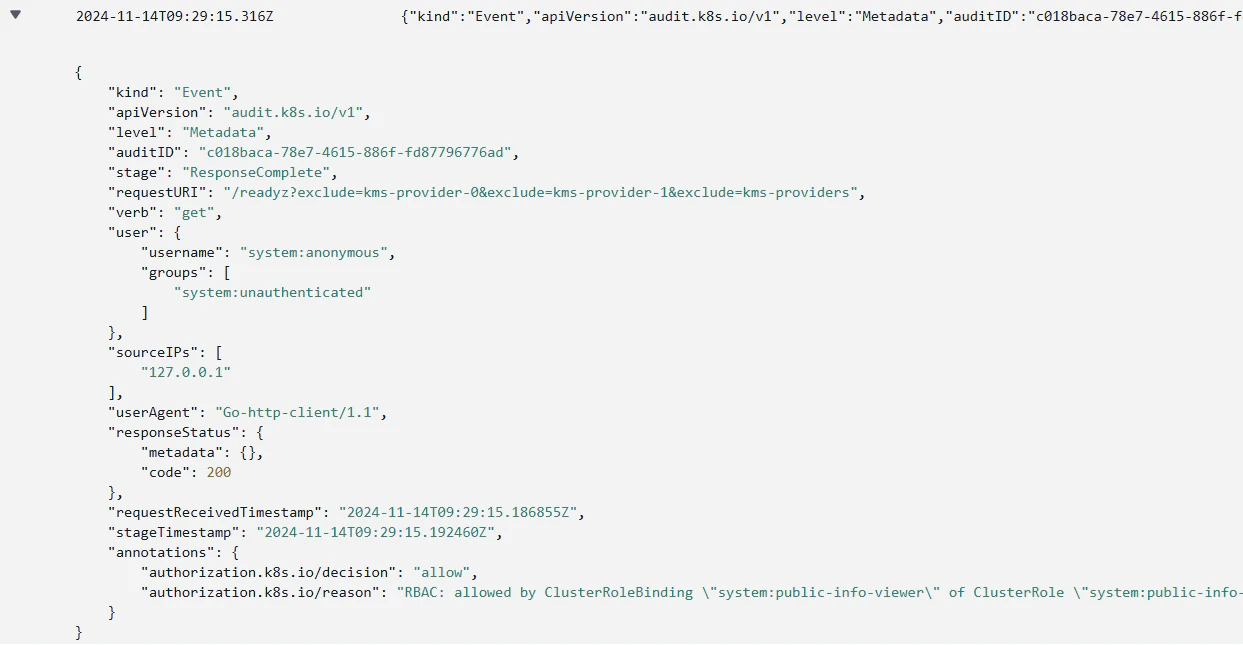
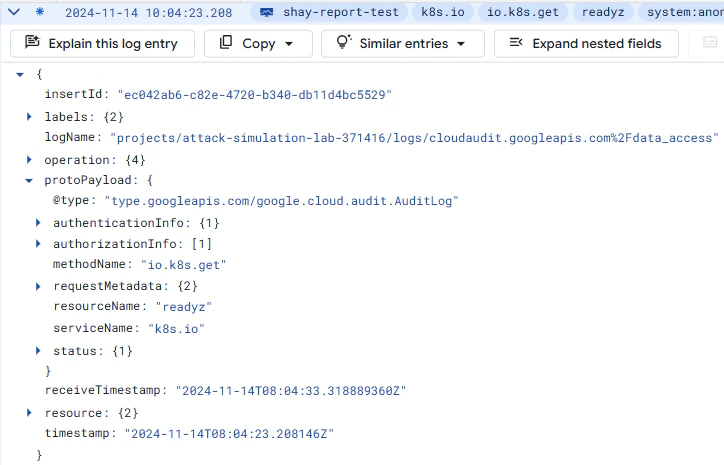
As a result, a rule set designed to detect suspicious behavior on a vanilla Kubernetes cluster will not work correctly on GKE, leading to missed detections. Consider the detection rule “Kubernetes workload created by anonymous user”. Presented below is the comparison of the rule expressed in Rego language for GKE (above) and EKS / Openshift / vanilla K8s (below):
match {
startswith(input.protoPayload.serviceName, "k8s.io")
endswith(input.protoPayload.methodName, "create")
{"system:anonymous","system:unauthenticated"}[input.protoPayload.authenticationInfo.principalEmail]
input.protoPayload.authorizationInfo[_].granted == true
}versus
match {
input.verb == "Create"
{"system:anonymous", "system:unauthenticated"}
[input.user.username]
input.annotations["authorization.k8s.io/decision"] == "allow"
} Imagine the overhead associated with maintaining separate detection rulesets. Another, also not ideal, solution might be to pre-process the audit log events to normalize them into the universal format.
3. Log Policy
There is an additional problem associated with the log policy. In most cases, Kubernetes end-users can’t be sure about which events will be monitored and which will not. Audit log policy is determined in the audit log policy file passed to the K8s API server via the –audit-policy-file parameter. Since these parameters are controlled by CSPs, end-users do not have a way to determine which events are logged. Moreover, all but one cloud provider keeps the content of this file private. Multiple attempts by customers to gain visibility and control into the log were left unanswered by CSPs. To call out a few examples:
4. Performance and Latency Considerations
Managing Kubernetes audit logs across multi-cloud or hybrid environments can also introduce latency and performance issues. When audit logs are streamed to centralized systems like CloudWatch or Azure Monitor, there can be significant delays between the time an event occurs and when it appears in the log stream. This can hinder real-time detection and response, especially in fast-moving attack scenarios. Additionally, the cost associated with storing and querying large volumes of audit logs, especially in high-traffic environments, can become prohibitively expensive.
Impact on Detection and Forensic Activity
The above challenges have a direct impact on detection and forensic investigations in Kubernetes environments. Audit logs are a key component in detecting and analyzing attacks, but gaps in coverage, format inconsistencies, and latency issues can limit their usefulness.
Missed Detection of Key Attacker Techniques: Inconsistent logging policies and incomplete logs can obscure attacker techniques like privilege escalation and lateral movement. For instance, if impersonation events or resource specifications are missing, detecting these actions becomes more difficult.
Wiz Research finds architecture risks that may compromise AI-as-a-Service providers
Wiz researchers discovered architecture risks that may compromise AI-as-a-Service providers and put customer data at risk. Wiz and Hugging Face worked together to mitigate the issue.
Read more

Maintenance Overhead: When CSPs alter log formats, existing detection rules may fail. Security teams must either maintain multiple sets of rules or standardize formats, increasing workload and potential for error.
Limitations in Forensic Investigations: During post-incident analysis, gaps in logs, format inconsistencies, and missing events hinder investigations. Attackers might exploit these omissions to conceal their actions.
Other Options and Solutions
Given the challenges in relying solely on Kubernetes audit logs, the Wiz Kubernetes security stack offers a more comprehensive solution. Wiz combines agentless scanning with real-time detection, using a combination of audit logs, cloud-specific logs, network behavior monitoring, and other sources. This approach allows for continuous detection of threats like remote code execution, crypto-mining, and lateral movement, covering the full scope of Kubernetes security needs.
Security teams should consider augmenting audit logs with additional sources, such as:
Dynamic admission controllers that monitor state changes in the cluster, providing real-time insight into changes that may not be captured by audit logs.
Cloud-specific logs (e.g., AWS CloudTrail, Azure Activity Logs) to capture events at the infrastructure level.
VPC Flow Logs and Network Policies for network-level visibility, which can help correlate Kubernetes actions with external network behavior.
Conclusion
Managing Kubernetes audit logs across multiple cloud providers presents significant challenges, from inconsistent logging policies and formats to performance and latency issues. These “gotchas” can negatively impact detection and forensic capabilities, leaving organizations vulnerable to advanced attacks. To summarize the above issues in one place we have created the following graphic taxonomy:
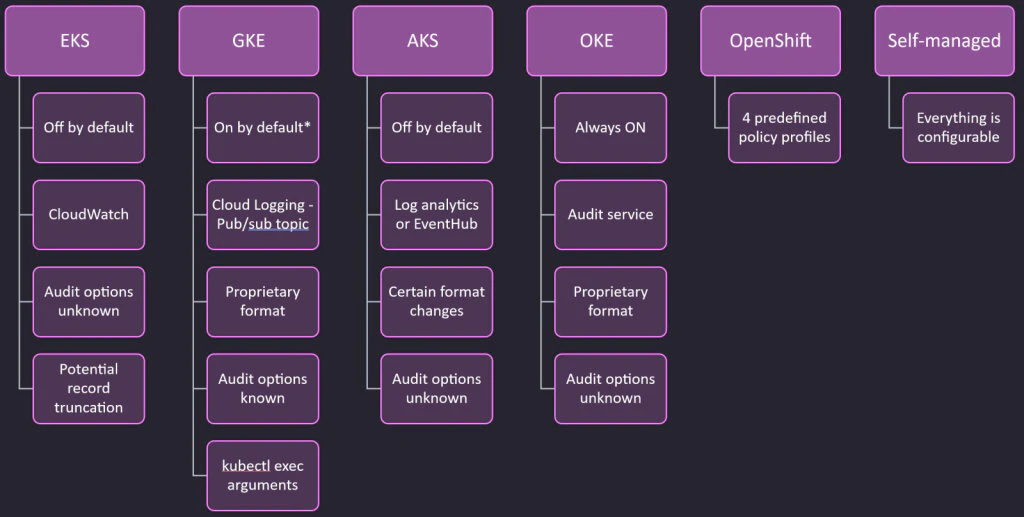
To mitigate these risks, security teams should adopt a multi-faceted approach, integrating audit logs with additional data sources and normalizing log formats where possible to ensure consistent, actionable insights.
















