



TL; DR
In this blog post, we take you through our journey of developing a user-friendly text-to-query search engine for Wiz's Security Graph. We’ll discuss the challenges we faced and the innovative solutions we implemented to make complex cybersecurity data accessible to everyone. Whether you're a tech enthusiast or new to the field, we break it down in a way that’s easy to follow, highlighting how we leveraged advanced technologies to simplify the process of querying intricate cloud security data.
Intro
These days, LLMs seem to solve almost everything, but some tasks still throw curveballs—especially when the model hasn’t been trained on the topic. There’s a lot of ways to fill those gaps, so in this post, we will explain from concept to production how our engineering and research teams handled building a text search engine over Wiz’s unique Security Graph.
Challenges of querying over the Security Graph
In the cybersecurity domain, it's common to encounter custom query languages designed to interact with specialized databases and platforms. These languages enable security professionals to perform complex queries tailored to their organization's specific needs. However, mastering these custom query languages can be daunting due to their complexity and steep learning curve. Even experienced professionals may find it challenging to construct queries that fully leverage the capabilities of these systems.
Enter the Wiz Security Graph— a powerful cybersecurity tool that provides a comprehensive view of an organization's cloud infrastructure and potential security risks. It leverages advanced data analysis and machine learning to map relationships between various cloud assets, configurations, and vulnerabilities across multiple platforms. Implemented as a graph database without a structured schema, the Security Graph presents numerous combinations and paths.
As cloud ecosystems grow increasingly complex, security teams often struggle to efficiently search for the most critical and relevant data within their vast infrastructure. To navigate this complexity, we've developed a specialized Wiz Query Language for querying and searching over the graph. But even with a handy UI, getting to the heart of the data still poses challenges, even for graph pros.
Here’s an example query (JSON) for “virtual machines with unencrypted disks”:
{"relationships":[{"type":[{"type":"USES"}],"with":{"type":["VOLUME"],"where":{"encrypted":{"EQUALS":false}}}}],"type":["VIRTUAL_MACHINE"]}
Our method, while specifically tailored to Wiz's Security Graph Query Language, offers a generalizable approach applicable to other custom security query languages. By leveraging LLMs and advanced data retrieval techniques, we aim to simplify the process of constructing complex queries. This approach makes querying more accessible to users who may not be familiar with the intricacies of custom query syntaxes, ultimately enhancing efficiency and effectiveness in the cybersecurity domain.
However, the dynamic relationships between entities, possible paths of vertices and edges, constraints, and the constant addition of new technologies, vulnerabilities, and features pose significant challenges to an LLM—especially when tasked with generating a query JSON it isn't familiar with. Additionally, the continuous updates of cloud resources, attack vectors, malware, and more create challenges in keeping pace with the ever-changing cloud security domain.
Therefore, we adopted an LLM-based approach to simplify the workflow with the graph for both customers and internal Wiz users. This method not only addresses the complexities of the Wiz Security Graph but also offers insights into how similar challenges can be tackled in other custom security query languages.
Choosing the Right LLM: Sonnet 3.5 via Amazon Bedrock
One of the critical decisions in our approach was selecting the appropriate LLM that balances performance, cost, and latency. We chose Anthropic’s Sonnet 3.5 accessed through Amazon Bedrock as our LLM. It gave us the perfect balance of speed, performance, and cost-efficiency, making it an ideal choice for our users.
At Anthropic, we're focused on building models that can effectively balance performance, cost, and latency across real-world use cases. Collaborating with Wiz on Sonnet 3.5 through Amazon Bedrock highlights how these models can be leveraged to simplify complex queries while maintaining high levels of accuracy and operational efficiency. We're excited to see Sonnet 3.5 powering innovative applications in cybersecurity.
Garvan Doyle, Applied AI Lead at Anthropic
It's all about the prompt
The secret to getting the LLM to play nice with our Security Graph? The right prompts.
Instead of just asking the model to generate queries from scratch, we guided it with carefully designed prompts. This meant giving it context and constraints. Here’s how we did it:
Zero-shot learning: We asked the LLM to generate a query based on a natural language description without any prior examples.
Few-shot learning: In addition, we provided examples of successful queries and then asked the LLM to build on those.
RAG (Retrieval-Augmented Generation): We didn’t rely on the LLM alone. Using RAG, we retrieved the most relevant data from our knowledge base and fed it to the model, ensuring it had all the context it needed to generate the perfect query.
For example, when a user types “show me all VMs with unpatched vulnerabilities,” we first pull related metadata from our security graph and enrich it with LLM-generated suggestions. The result? A tight, accurate query that digs up exactly what the user is looking for—fast.
Divide-and-conquer approach
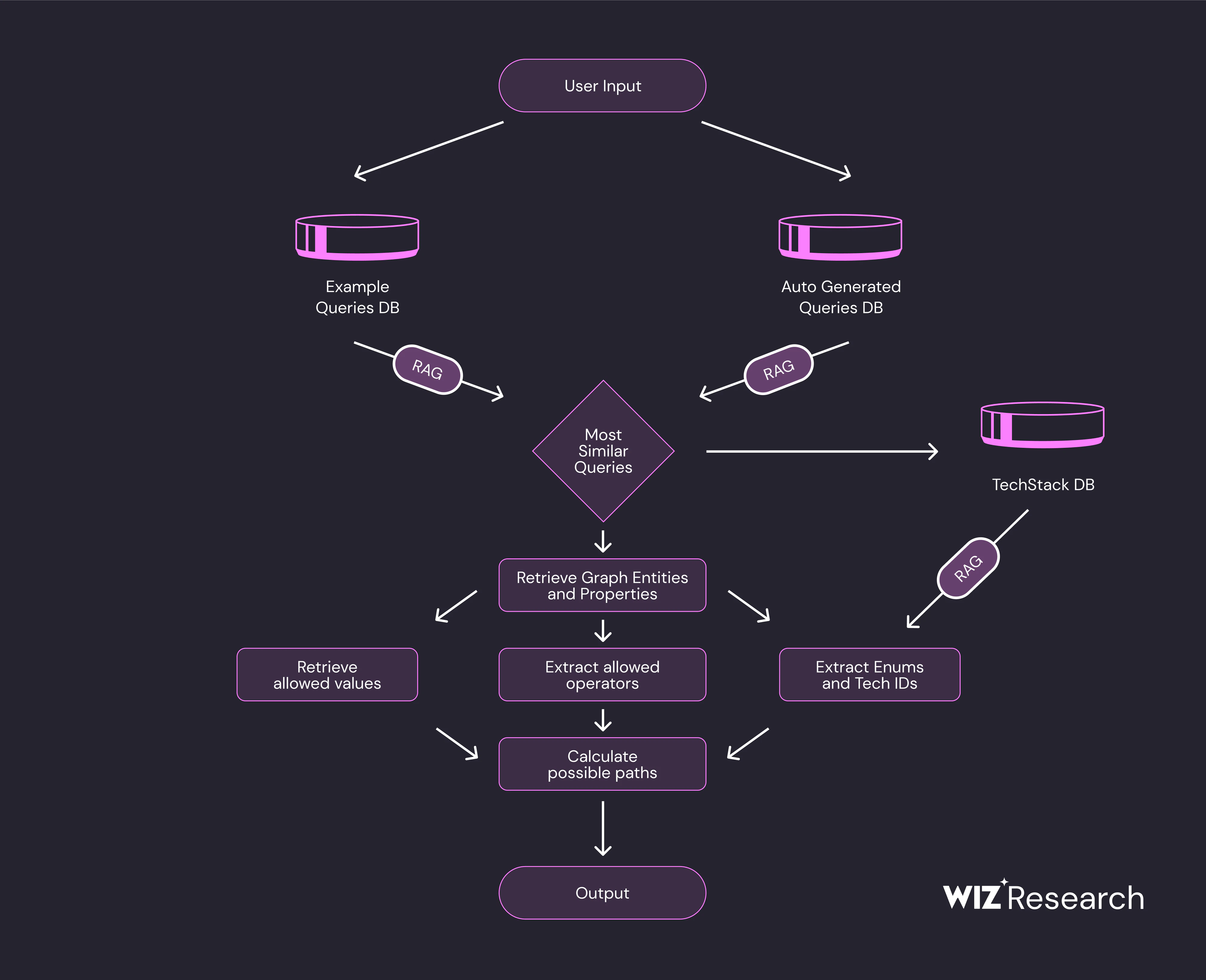
To ensure the model constructs queries that are both syntactically correct and contextually accurate, we needed to break down the process into manageable steps. Instead of just providing a static explanation of query syntax and structure, we offered the model the key building blocks to guide it. Here’s how we approached it:
From the user's input, we retrieve the most similar query examples using cosine similarity with embeddings.
We then extract all the relevant graph entities from these queries and retrieve their properties and descriptions.
Next, we gather all the allowed operators and value types associated with those entities.
For each property, we retrieve the allowed values.
We also retrieve descriptions and unique IDs for all relevant technologies.
Finally, we calculate possible paths and allowed relationships based on the retrieved information.
Each of these steps is crucial, as they are interdependent. An error in one step could significantly impact the accuracy of the final query. The structure of the prompt, which includes all of this information, is also critical. Since it’s a large amount of context to provide to the model, we went through several iterations of prompt engineering. We even collaborated with Anthropic's research team to ensure we were on the right path.
Initial review
We started by compiling a benchmark dataset of 200 query examples, each paired with its corresponding JSON. The initial results showed 80% accuracy, verified through exact matches or manual review. This performance gave us the confidence to move forward with a feature preview, sharing it with both internal teams and external users to gather feedback in real-world scenarios.
However, once data from live environments started coming in, we quickly encountered gaps between our assumptions and reality. The way real-world queries were phrased—terminology, query structures, and even the distribution of topics—diverged from the examples in our demonstration database.
To address these discrepancies, we immediately began refining our prompts and validation process. While these improvements led to slight gains in accuracy, it became clear that more extensive research was necessary. We needed a deeper understanding of the nature of real-world questions, so we could fine-tune the data and examples provided to the model.
Data First approach
Our approach centers around the initial retrieval of examples that closely match the semantic meaning of the user's input. The foundation of our model’s effectiveness lies in constructing a robust dataset filled with diverse examples that reflect the real-life questions users are likely to ask.
Take, for instance, the query, “Find me the AWS service account AROA111222333444ABCDE.” While this request is straightforward, users expect to retrieve the same results if they input just “AROA111222333444ABCDE.” By providing a wealth of examples in our database, we enable the model to infer that this string is indeed an AWS entity.
Additionally, we must remain vigilant about the constant changes within Wiz, including new vulnerabilities, emerging resources, and ongoing developments within our security graph.
We also recognize the importance of continuously reviewing our current production models alongside any new iterations. This ongoing evaluation process drives us to enhance our examples database, refine our retrieval-augmented generation (RAG) techniques, and optimize our prompt structures.
Clustering using UMAP & DBSCAN
To gain meaningful insights into the topics being queried through our LLM search engine and identify potential blind spots, we embarked on a clustering analysis of anonymized customer requests. Importantly, the anonymization process preserved the semantic meaning of each query.
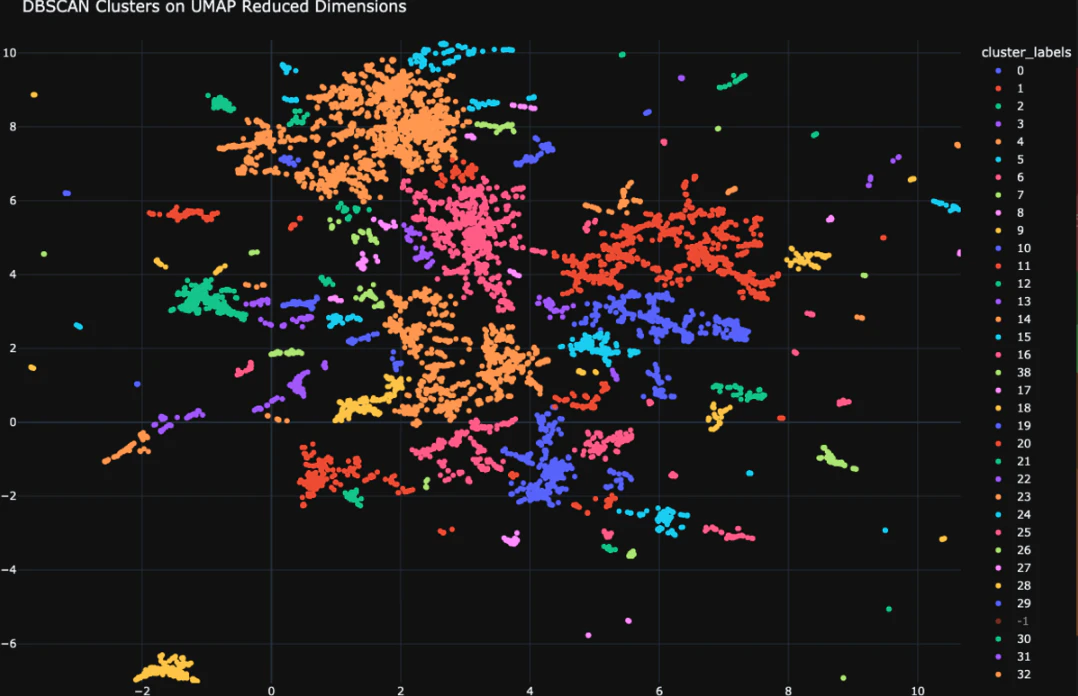
We began by embedding all input queries into vectors that represent their content. Utilizing UMAP (Uniform Manifold Approximation and Projection), a powerful dimensionality reduction algorithm, we transformed our high-dimensional data into a lower-dimensional space. This technique not only simplifies visualization but also maintains the local and global structures of the data, allowing us to uncover hidden patterns. With UMAP, clusters within our data became much more apparent.
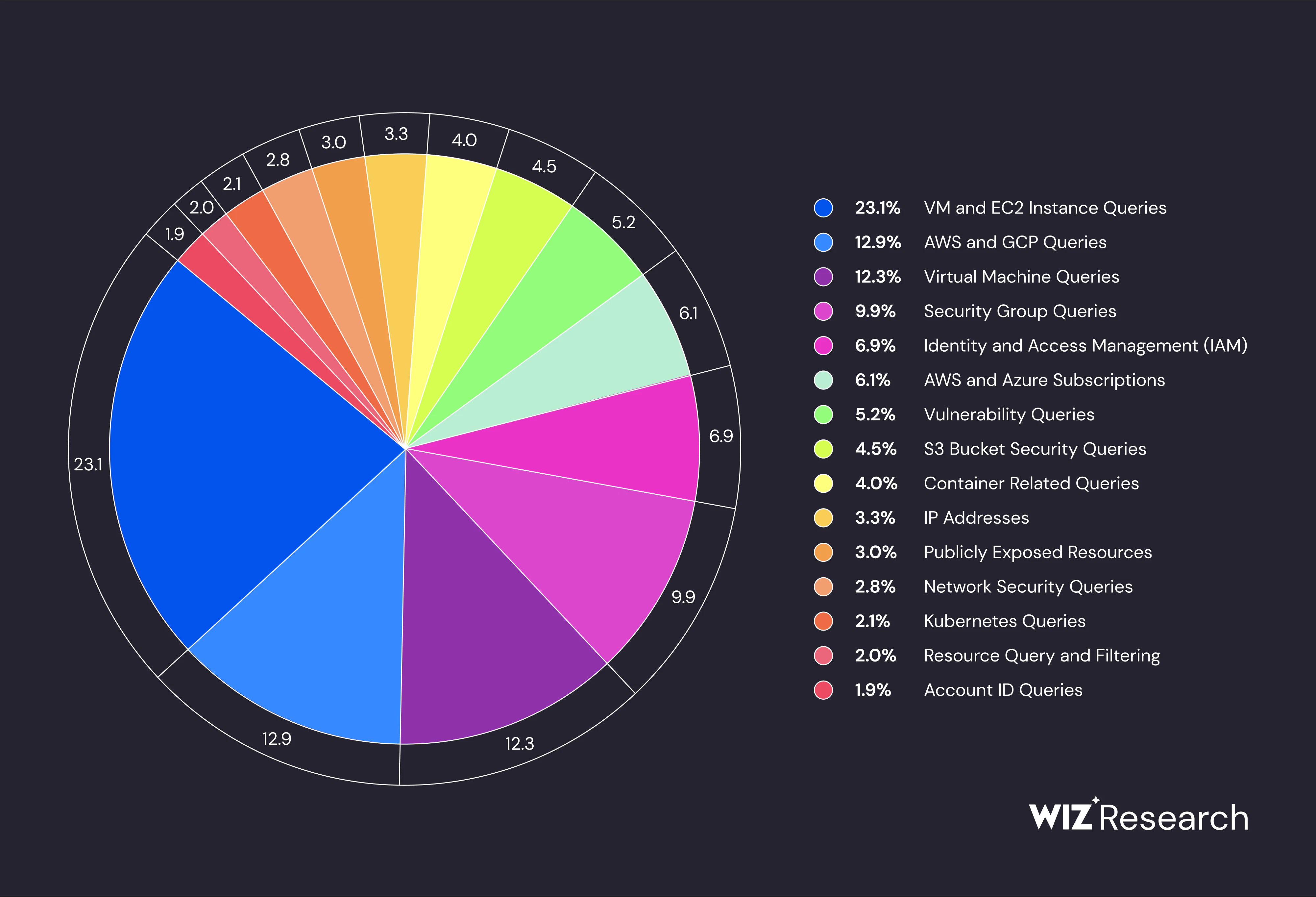
Once we distilled our data into a two-dimensional representation, we employed DBSCAN (Density-Based Spatial Clustering of Applications with Noise) to identify approximately 150 unique topics. To further analyze these clusters, we randomly selected 50 queries from each and leveraged an LLM to categorize them. For example, we might label a cluster as “EC2 Related Queries.” This categorization enabled us to examine the distribution of topics and identify areas that our example database might not adequately cover.
Query generation
With a deeper understanding of the topics and nuances of real query requests, we initiated a two-pronged approach to enrich our example database:
Manual Insertion: Our dedicated team of researchers, product managers, and security graph experts meticulously crafted query examples that closely mirror the tone and style of actual user inquiries. This hands-on effort ensures that the examples resonate with the real-world context of our users.
LLM-Generated Queries: Leveraging insights from our clustering analysis, we utilized LLMs to generate new query descriptions. Each topic generated a set of representative queries that reflected diverse real-life scenarios, closely aligned with previously observed examples. To ensure accuracy, our researchers and graph experts completed the corresponding JSON structures, creating a comprehensive dataset.
In addition, we implemented an automated query generation process to keep pace with ongoing developments. This system scans our graph schema to generate generic queries that reflect new features and entities, ensuring that every addition is represented in our example database.
These concerted efforts significantly increased the volume of relevant examples and allowed us to eliminate those that caused confusion for the LLM during JSON generation. As a result, we observed a substantial boost in accuracy, supported by positive feedback from users and expert validation through random sampling of requests.
Re-Ranking Using MMR
While our extensive research has significantly improved the accuracy of our example database, we recognize that there’s always room for refinement. The initial retrieval process can yield examples that, although relevant, may be overly similar or redundant. To enhance the quality of our generated responses, it’s essential to provide the model with not just relevant information but also a diverse array of inputs. This is where re-ranking becomes crucial.
Various techniques exist for re-ranking, but we must balance cost and performance, as some methods involve employing another LLM, which can lead to increased expenses and latency. To strike this balance, we adopted a straightforward yet effective approach.
Maximal Marginal Relevance (MMR) is an information retrieval technique designed to optimize the selection of documents or pieces of information by balancing relevance and diversity. In the context of our Retrieval-Augmented Generation (RAG) models, MMR enhances the retrieval process by ensuring that the selected query examples are not only pertinent to the user's query but also varied, effectively reducing redundancy.
For example, consider the input:
“A virtual machine containing sensitive data and an AI model that is exposed to the internet.”
Without MMR, we might retrieve the following examples:
-VM with access to sensitive data and malicious activity
-VM with sensitive data targeted by a failed brute force attack
-Application endpoint on a VM/serverless exposing sensitive data
-Publicly exposed VM/serverless with sensitive data
-Publicly exposed VM with a high/critical severity network vulnerability with a known exploit and sensitive data With MMR, however, the retrieved examples would look like this:
-VM with access to sensitive data and malicious activity
-Show me virtual machines exposed to the internet with unencrypted secrets
-Hosted AI Models
-VMs that are open to the internet on port 80
-Publicly exposed container with access to sensitive data The MMR-retrieved examples showcase greater variance and, most importantly, introduce another example that provides our LLM with relevant context regarding AI models. Without MMR, that critical context would be absent.
Summary
To elevate the accuracy of generating queries over the Wiz Security Graph with LLMs, we honed in on enhancing our examples database. Our approach involved a three-pronged strategy: manually adding query examples sourced from our team of experts, generating new descriptions through LLMs based on the clustering of real-world queries, and automatically creating generic queries for new graph features.
To ensure the model benefitted from both diversity and relevance, we integrated Maximal Marginal Relevance (MMR) into our example selection process. Furthermore, we employed UMAP and DBSCAN to cluster anonymized user inputs, enabling us to pinpoint underrepresented topics and adapt our data accordingly.
This comprehensive approach has significantly bolstered our model's accuracy, ensuring it resonates more closely with the genuine queries posed by our users in the field.

















