What is data poisoning?
Data poisoning is a type of adversarial attack that targets AI and machine learning (ML) model training datasets to degrade or control model behavior. Attackers try to slip misleading or incorrect information into the training dataset by adding new data, changing existing data, or even deleting some data to corrupt the model’s understanding.
Industries that use AI-driven decisions—liek finance, healthcare, and autonomous systems—are prime targets for poisoning because of the high impact of model misbehavior.
25 AI Agents. 257 Real Attacks. Who Wins?
Based on the sample size of hundreds of tFrom zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

The potential impact of a data poisoning attack
Due to data poisoning, systems that depend on data can become considerably less reliable and effective. According to Wiz’s State of AI in the Cloud report, “70% of cloud environments [use] AI services.”
The following are some possible effects of these AI and large language model (LLM) attacks:
| LLM issues | Impact |
|---|---|
| Teams use poisoned data for decision-making. | Malicious data can introduce biases that skew results and decisions based on the poisoned dataset. For instance, incorporating inaccurate or biased data into a financial model can result in bad investment choices that negatively affect the organization’s financial stability. Similarly, biased data in the medical field may result in inaccurate diagnoses and treatment recommendations, which could jeopardize patients’ health. |
| Organizations suffer from imprecision and inaccurate recall. | Poisoned data can degrade predictive models’ overall accuracy, precision, and recall. Unreliable outputs and increased error rates may follow, compromising entire systems. Cases like these could entail focusing on the incorrect demographic in fields like marketing or overlooking real concerns in cybersecurity. The reduced effectiveness of these models undermines their value and can lead to significant losses. |
| Security teams face potential system failure or exploitation. | Data poisoning creates backdoor attacks where hackers introduce triggers into datasets that make systems behave unpredictably, which allows them to bypass security measures or manipulate system outputs for malicious purposes. |
In critical infrastructure, vulnerabilities that attackers introduce via backdoor attacks can have severe consequences. For instance, the LAPSUS$ hacker group’s attempts to poison AI model data used a combination of tactics, including setting up a backdoor to gain system access.
How a data poisoning attack works
Data poisoning happens during the following common attacks:
Injecting false data: Attackers manipulate a data set by adding fictitious or deceptive data points or by prompt injecting, which results in inaccurate training and predictions. For example, manipulating a recommendation system to include false customer ratings can change how people judge a product’s quality.
Modifying existing data: In this type of attack, attackers alter genuine data points to introduce errors and mislead the system without adding any new data. An example is changing the values in a financial transaction database to compromise fraud detection systems or create miscalculations concerning accrued profits or losses.
Deleting data: Removing critical data points creates gaps that lead to poor model generalization. These gaps often affect model performance on edge cases—the very scenarios that many security and safety-critical systems are designed to catch. For example, a cybersecurity system may become blind to certain network attacks if attack data disappears.
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

Targeted vs. non-targeted data poisoning attacks
In targeted data poisoning attacks, malicious actors aim to achieve specific outcomes, such as causing a system to misclassify certain inputs. Backdoor attacks fall into this category, where specific triggers cause the system to behave in a predefined way. For instance, a security camera system might have a program that disregards trespassers using a specific disguise.
Non-targeted data poisoning attacks, on the other hand, undermine machine learning models by injecting corrupted or misleading data into training sets. The attacks degrade the model’s accuracy and reliability, resulting in errors in the output.
For example, in a non-targeted data poisoning attack, a hacker could add random noise or mislabeled emails to your spam filter’s training data. This would cause the model to misclassify critical emails or tickets—and potentially disrupt enterprise workflows.
2 examples of data poisoning in the real world
What does a data poisoning vulnerability look like? Below are two real-life examples of data poisoning threats:
Researchers uncover AI data poisoning vulnerabilities
In 2024, University of Texas researchers found data poisoning vulnerabilities in AI systems. During the project, which they later dubbed ConfusedPilot, these researchers studied models like Microsoft 365 Copilot and focused on retrieval-augmented generation. To test their ideas, they added malicious data into AI-referenced documents.
When users searched for information, the AI used poisoned data and returned the queries with inaccurate and false information. Even after researchers deleted the documents, queries still produced misleading output.
ConfusedPilot proved how easily poisoned data could create hallucinations, even after the researchers deleted malicious source documents. As companies rely more on AI, data points like these could disrupt operations and data integrity.
Hugging Face and Wiz stop data pipeline poisoning
When Wiz researchers worked with Hugging Face to uncover a critical risk, they found a vulnerability that allowed threat actors to upload malicious data to Hugging Face’s platform. If an attack occurred and organizations integrated malicious data, they could compromise their own AI pipeline. This type of data poisoning would allow manipulation across the entire organization’s infrastructure.
Wiz mitigated future issues by integrating detection capabilities from its platform to monitor AI components in customer environments. The solution also flagged suspicious behaviors and provided full visibility with features like AI Security Posture Management (AI-SPM).
The Attack Surface of GenAI Models
Learn security best practices to deploy generative AI models as part of your multi-tenant cloud applications and avoid putting your customers’ data at risk.
Read more

Techniques to prevent data poisoning

Defending against data poisoning requires a comprehensive approach. That’s why combining robust data management with advanced detection techniques can make a big difference in countering threat actors.
Here are a few ways you can do so:
Implement robust data validation
Strict validation procedures can stop the introduction of tainted data. Key strategies include:
Data provenance: Monitoring data provenance and history helps you locate and remove potentially harmful data sources since reliable data sources can prevent data poisoning.
Cross-validation: Validating the model on several data subsets uncovers anomalies and inconsistencies, which lowers the possibility of overfitting to tainted data. This helps you realize model performance within the expected improvement margin.
Monitor for anomalies based on training data and behavior
Automatic anomaly detection helps you spot and flag abnormal patterns that can signal tampering. Key strategies include:
Outlier detection within datasets: Use statistical methods and clustering algorithms, such as DBSCAN, to identify anomalous data points. These approaches help you identify manipulated data before it corrupts models.
Model behavior tracking: Practice consistent reviews to evaluate your model output with baselines. If there’s an unexpected shift in model precision or performance, it may be a sign that poisoning has occurred. Canary tests can help you find these issues early on.
Techniques to detect data poisoning quickly
Detecting incidents quickly can mitigate how much damage data poisoning causes your organization. You can practice the following measures to remediate issues in real time:
Include anomaly detection algorithms
Sophisticated algorithms can uncover data anomalies that point to poisoning attempts. Key strategies include:
Statistical methods: These find anomalies and trends that could point to data manipulation. Clustering techniques, for example, identify data points that highly deviate from the mean.
ML-based detection: As another layer of protection, ML models identify common patterns in tainted data. This helps you keep tabs on metrics and the functionality of models that are working directly with sensitive information.
Establish regular system audits
Periodic system audits can guarantee data dependability and identify early indicators of data poisoning. Key strategies include:
Performance monitoring: It’s possible to identify unusual declines in accuracy, precision, or recall that may be signs of data poisoning by continuously tracking system performance on a validation set.
Behavioral analysis: Analyzing system behavior on specific test cases or edge cases can reveal vulnerabilities from data poisoning. These vulnerabilities occur when systems ingest data from an unsolicited, unrecognized source.
Data integrity is crucial, as it continues to be the primary factor in decision-making across many industries, especially those that are rapidly adopting AI. As a result, maintaining an advantage over competitors and guaranteeing data-driven systems’ reliability and security both depend on ongoing innovation and cooperation.
See Wiz Cloud in Action
In your 10 minute interactive guided tour, you will:
Get instant access to the Wiz platform walkthrough
Experience how Wiz prioritizes critical risks
See the remediation steps involved with specific examples
Implementing a rapid response action plan after a data poisoning attack
What happens if a data point comes knocking at your door? Your security team needs a discovery and remediation plan that prevents, mitigates, and patches damages.
Here are five steps you can take to put one into action:
1. Implement real-time monitoring and alerts
The first line of defense is continuous monitoring. Your security team can leverage automation and alerts to secure and monitor data pipelines and AI models. Advanced monitoring solutions like Wiz also detect anomalies, validate data, and provide prioritized and contextualized risk assessments so you can target the most critical threats.
Improve your monitoring and detection today with automatic real-time reviews, customized alert thresholds, and alert integration with your incident response processes.
2. Rollback to a clean dataset or model state
If you do detect data poisoning, you need a way to quickly revert your systems to a healthy infrastructure to avoid disruption.
The most effective way to clean your dataset is to maintain regular backups for your training datasets and model checkpoints. To help with clean states, you can use version control systems like Git for code or DVC for data. Automated rollback scripts also help with fast reservations to minimize downtime.
Implement these steps by scheduling automated versioned backups for your datasets and models, using tools like DVC to manage models and reproducible data, and simulating rollback procedures for testing readiness.
3. Conduct incident investigation and root cause analysis
Once you’ve returned your dataset and models to normal, determine what happened and what vulnerability allowed the attack. To do this, focus on data lineage and tracking to determine where the poisoning occurred.
Wiz’s AI-SPM, for example, gives you visibility into your data flows, model revisions, and attack paths. With it, you can study your logs and data changes to locate the entry point.
As you implement these tracking steps, document your findings so you can update your incident response plan and prevention.
4. Revalidate and re-sanitize data
Remediation doesn’t stop after you’ve rolled back your system—now it’s time to re-examine your information. You can use tools like OpenRefine or Trifacta Wrangler to automate the process of removing suspicious data points.
Run anomaly detection and clustering algorithms for new and historical data and cross-validate information with other authoritative or credible sources.
5. Patch and strengthen data pipelines
After verifying your data, your security team should create new steps and adjustments to prevent a similar attack from happening again.
You can start by improving data provenance tracking and adding stricter access controls for all your data sources. Then, unify your data through extract, load, transform pipeline architecture to centralize your process and reduce risks from fragmented processes. Finally, consistently audit and lead penetration tests for your AI resources and pipeline.
Periodically enforce least-privilege access to sensitive data sources and rate credentials. This limits exposure in the event of a credential compromise and ensures that only authorized users have access to sensitive data, thereby reducing the risk of data poisoning.
Wiz: The simplest way to detect and mitigate data poisoning risks

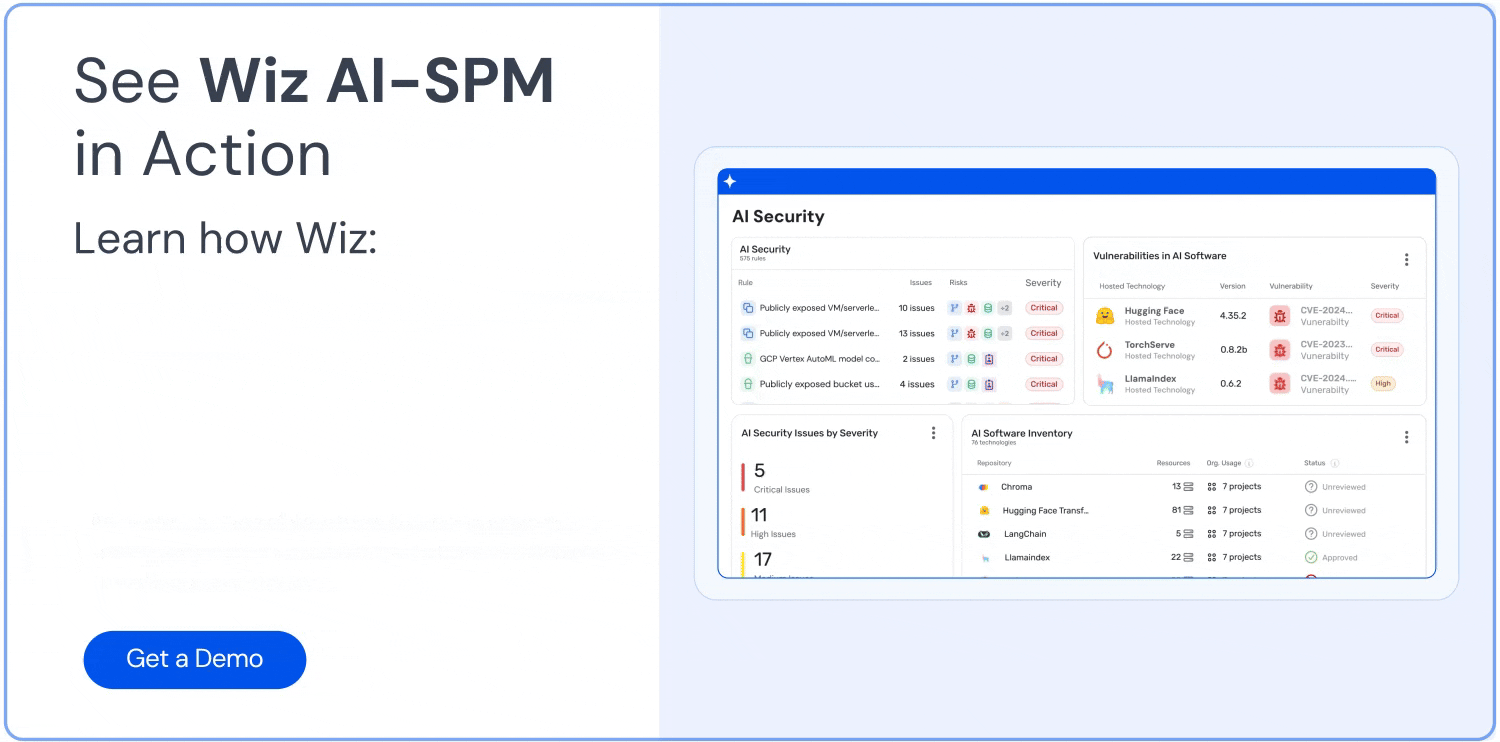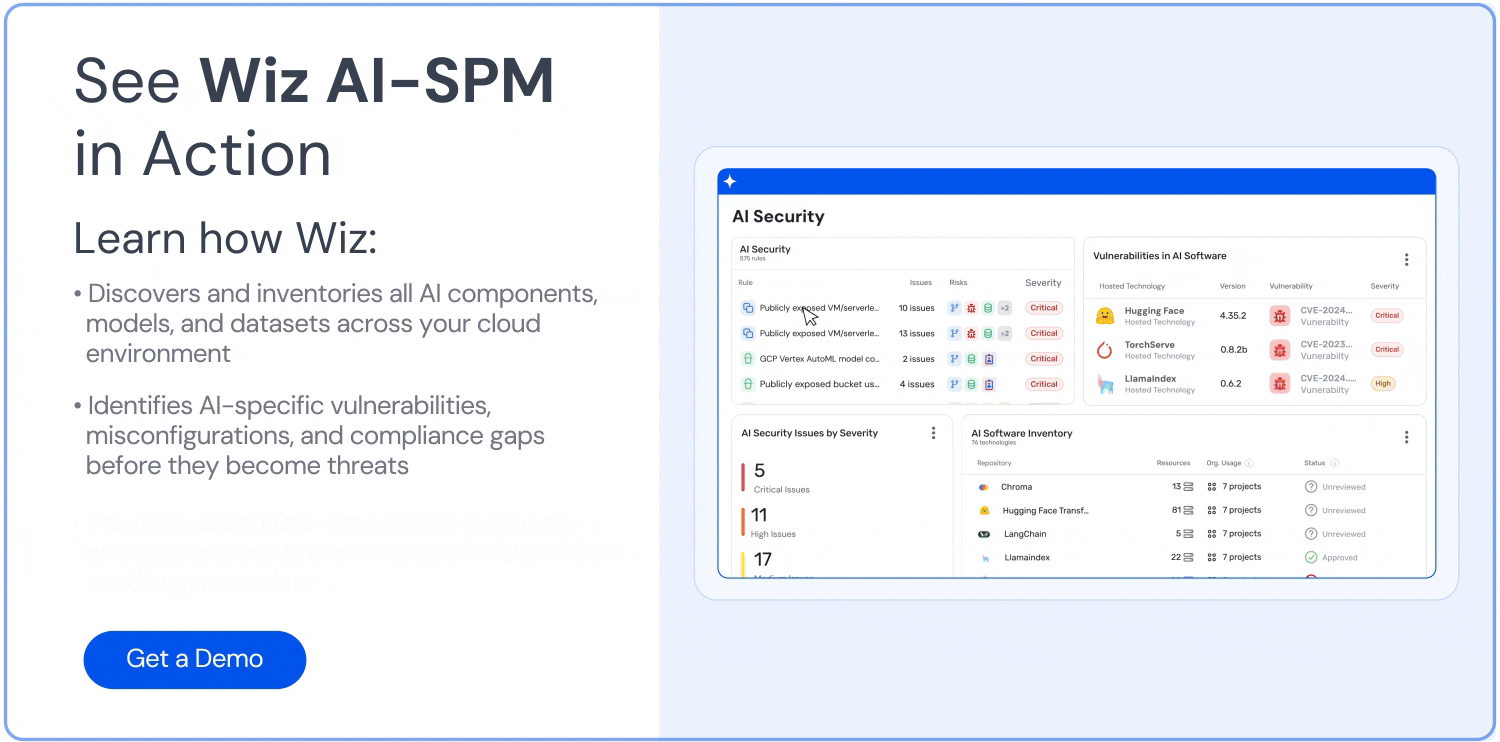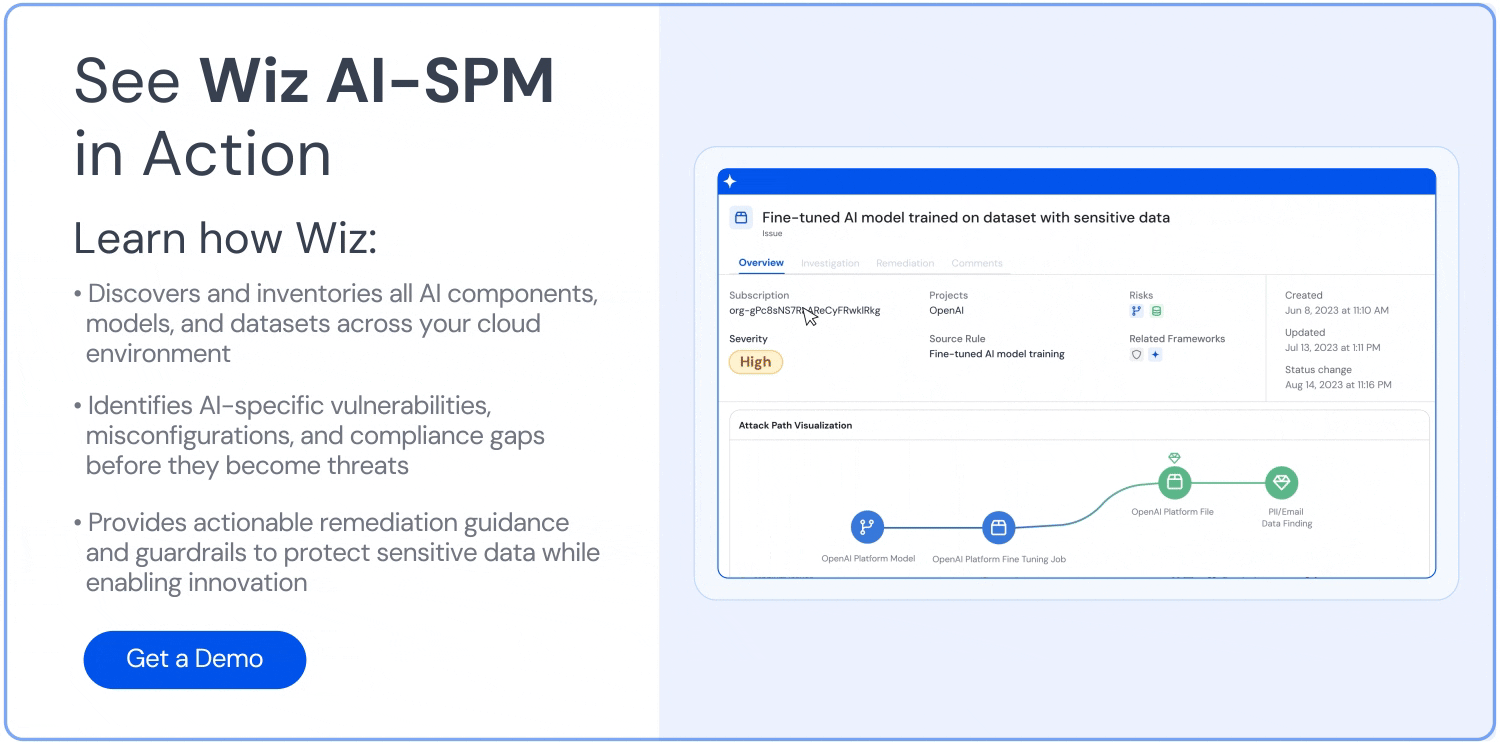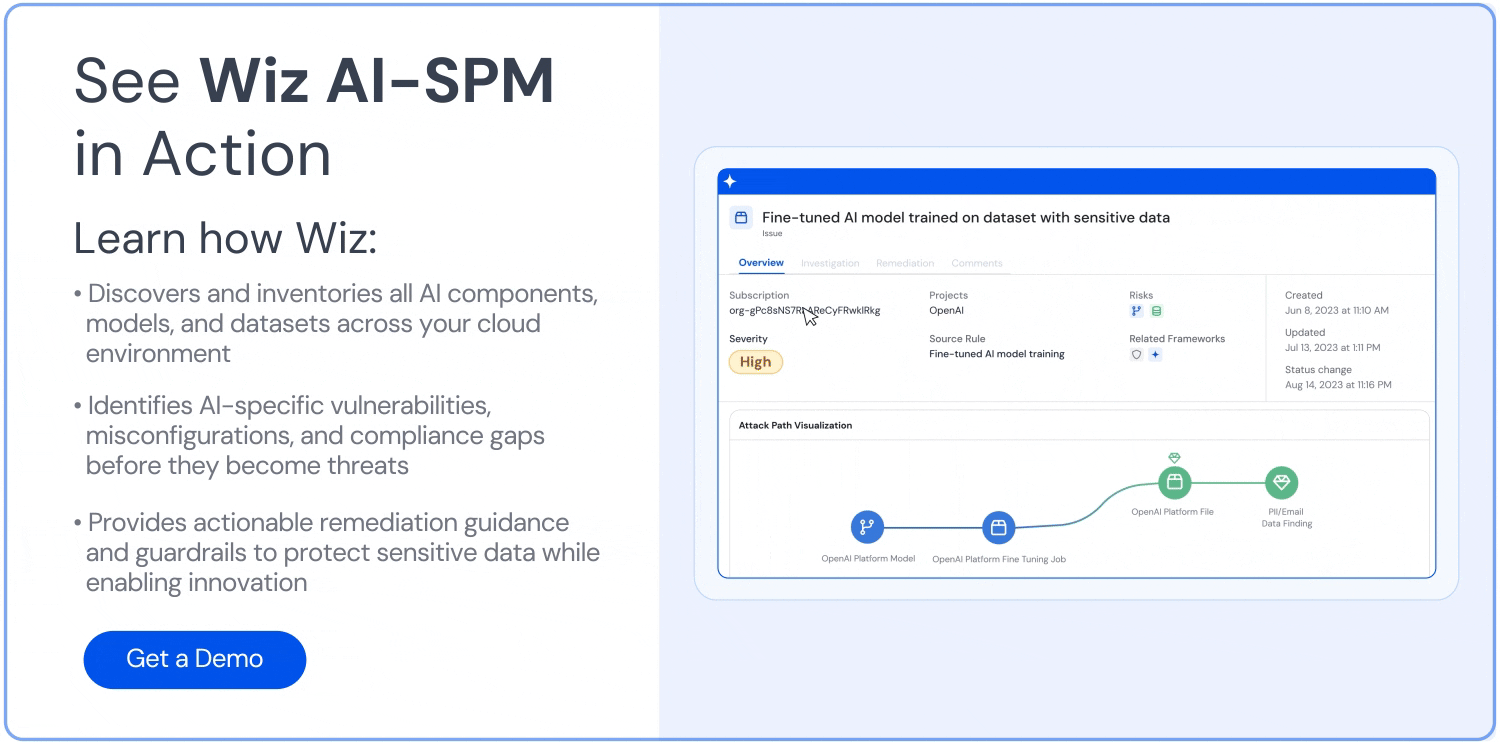
AI-SPM is a set of capabilities that secures AI pipelines and accelerates AI adoption while protecting against related risks in cloud environments. Wiz became the first cloud native application protection platform (CNAPP) to introduce AI-SPM capabilities in 2023 by providing native AI security features.

Wiz offers several features to help teams detect and mitigate data poisoning risks in AI systems:
Full-stack visibility: Wiz’s AI bill of materials provides comprehensive visibility into AI pipelines, services, technologies, and software development kits without requiring agents. This helps organizations identify potential entry points for data poisoning attacks.
Data security for AI: The platform extends its data security posture management capabilities to AI by automatically detecting sensitive training data and identifying data leakage risks. This helps you protect against unauthorized access or training data manipulation that could lead to poisoning.
Attack path analysis: Wiz’s attack path analysis extends to AI systems, which allows organizations to detect potential attack paths to AI models and training data. This helps them identify vulnerabilities that could lead to data poisoning exploitation.
AI misconfiguration detection: This solution enforces secure configuration baselines for AI services with built-in rules and AI risk management to detect misconfigurations. Proper configurations can help you prevent unauthorized access to training data and models.
Model scanning: Wiz offers model scanning capabilities that detect potential issues in AI models, including signs of data poisoning or unexpected behaviors that result from compromised training data.
AI security dashboard: This CNAPP provides an AI security dashboard that offers an overview of top AI security issues, including a prioritized queue of risks. This helps AI developers and security teams quickly identify and address potential data poisoning threats.
By combining these capabilities, Wiz’s AI-SPM solution enables organizations to proactively identify and mitigate data poisoning risks across their AI infrastructure, from training data to deployed models.
For more tips on how to assess your AI security posture, download Wiz’s AI-SPM guide today.