



Data flow mapping is the process of creating data flow diagrams (DFDs) that show the flow of data through an organization’s software system, networks, containers, storage points, and beyond. Simply put, data flow mapping displays the data process flow from origin to final destination at a glance.
In this article, we’ll take a closer look at everything you need to know about data flow mapping: its huge benefits, how to create one, and best practices, and we’ll also provide sample templates using real-life examples.
Cloud Data Security Snapshot 2025
54% of cloud environments expose sensitive data on public-facing VMs—prime targets for exfiltration. Benchmark your own exposure and get remediation guidance in the report.
Download snapshot

What data flow mapping brings to the table
Data flow mapping has a lot to offer data protection officers (DPOs), data governance specialists, and enterprises as a whole:
Security
Because it gives granular visibility into data flows, data flow mapping pinpoints vulnerabilities in the data lifecycle. (Think weak encryption, poorly implemented access controls, and unnecessary data transfer to third parties.) The benefit? An unbeatable enterprise data security posture.
For example, an e-commerce company can map out data flows to visualize how secrets are managed in their stack. With a map in place, they can discover exposed secrets and potential attacker entry points. These insights are the first step toward effective security measures, like secure coding, encryption, RBAC, and ZTA.
Just as important, if a data breach does happen, data flow maps slash the time it takes to identify vulnerable data or processes, speeding up root cause analysis and incident response.
Compliance
We all know that PII, PHI, financial records, secrets, and intellectual property need to be handled with care. Data flow mapping is a standout when it comes to vulnerability and data leakage discovery, data governance, and regulatory compliance. Without data flow maps, organizations don’t know what types of data is stored where, what third party a specific data type is sent to, and who is interacting with what data—putting data at a high risk of being breached.
Different standards require organizations to demonstrate how sensitive data is transformed and protected, and visualizing data flows helps you comply with these frameworks. Data flow mapping also makes it easier to understand the applicable data storage, processing, and transfer laws for various data sets.
For instance, to maintain compliance with HIPAA, healthcare organizations can create data flow maps to determine if data being shared with third-party organizations meets compliance requirements. Beyond HIPAA, the GDPR Data Protection Act 2018 (DPA 2018) mandates processing and storage requirements for personal data. For instance, data flow mapping is critical for maintaining a record of processing activity (ROPA) (a compliance measure described in GDPR Article 30). By showing exactly where data is and how it’s transformed, data flow mapping can help organizations with customers in the EU stay compliant with GDPR.
Operational efficiency
Visualizing data flows shows you bottlenecks that slow down transactions or end up leaking data. Data flow maps can also provide insights needed to automate processes, eliminate inefficiencies, optimize resource allocation, define data governance roles, or rejig data flows to address security and performance concerns.
Key elements of a data flow map (with examples)
Data flow diagrams (DFDs) break down data flow into several critical components and are the building blocks of data flow maps. DFD components are annotated with a range of symbols, which look different depending on the methodology you choose. The methodologies—Gane and Sarson, SSADM, Yourdon DeMarco, and Yourdon and Coad—and their notations are shown in figure 1.
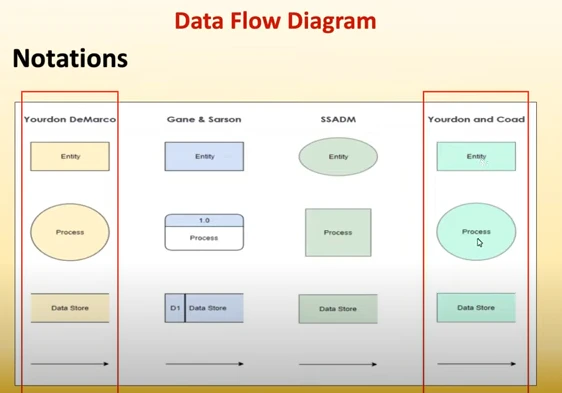
So what do these components mean? Let’s take them one at a time, using the Gane and Sarson DFD notations.
External entities
External entities are outside data sources or destinations that interact with the system, including customer input forms, external APIs, logs, email systems, and databases. External entities provide input and receive output data. They can be classified into:
a) Data sources: These are the external points that introduce data into the system to be transformed or stored. A common example of a data source is customers, who enter payment or personal identifier information into an input form on an e-commerce site.
b) Data destinations (or data sinks): Data sinks are where output data is sent. In the e-commerce DFD above, an example of a data sink would be a sales database where completed and pending orders and transaction IDs are stored so that shipping companies can complete the orders.
c) Source and destination: An external entity can be both a source and a destination. For example, a secrets management service is a data source when it sends out API tokens at runtime, but it’s a destination when tokens are sent to it for safekeeping.
In DFDs, external entities are generally labeled as nouns (e.g., Customer, Supplier)
Processes
Processes are manual or automated activities performed on data—e.g., transformation, validation, and enrichment. All DFDs must have at least one data input and output process each, labeled with the reference number at the top and the process description below.
The reference number tells you the position of the process in the DFD (like if it’s the first or second process) as well as the level of the diagram (more on this in the next section!). The process description clearly shows what the process does: The label is always an active verb plus a noun.
Data stores
Data stores are repositories where data is stored and fetched when you need it. These include on-premises servers, cloud storage solutions, and hybrid/multi-cloud environments. A data store notation always has an input and an output data flow.
Data stores are labeled using noun phrases. For example, a bank storing customer PII in an Amazon S3 bucket may label the data store as shown in figure 8.
With clear diagramming, companies know the level of protection to give the data, both at rest and in transit.
Data flows
Data flows show the movement of data between processes and external entities. A single data flow can be an input, an output, or both. If a data flow is both, the arrow will point both ways.
Levels of data flow diagrams
Data flow diagrams are categorized by level of complexity, from general overviews (context diagrams, which are the most basic interpretation) to levels 1, 2, and 3, which have increasing levels of complexity and offer deeper insights:
Context diagram: A context diagram is a single process node and gives a broad overview of how data interacts with external entities. It’s best for small-scale apps or use cases where granular details are not required.
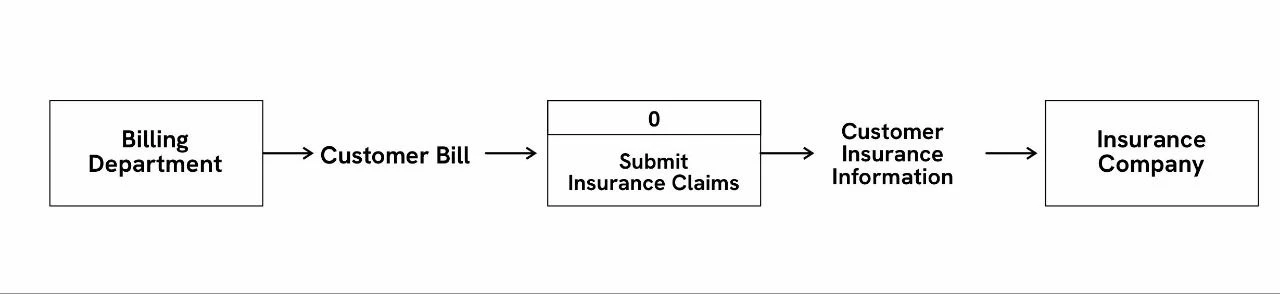
Level 0 DFDs: A 0-level DFD shows the main functions performed by the system; it also digs deeper into the single process outlined in the context diagram, offering more detail on how data moves internally.
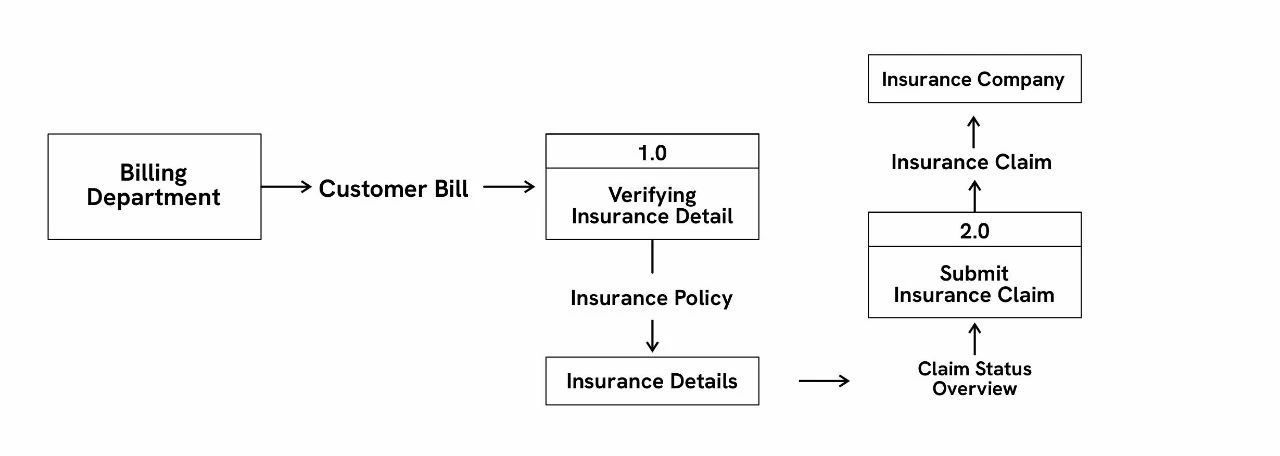
Level 1 DFDs: Level 1 DFDs break down level 0’s main processes into subprocesses to show how each task is handled within a larger function.
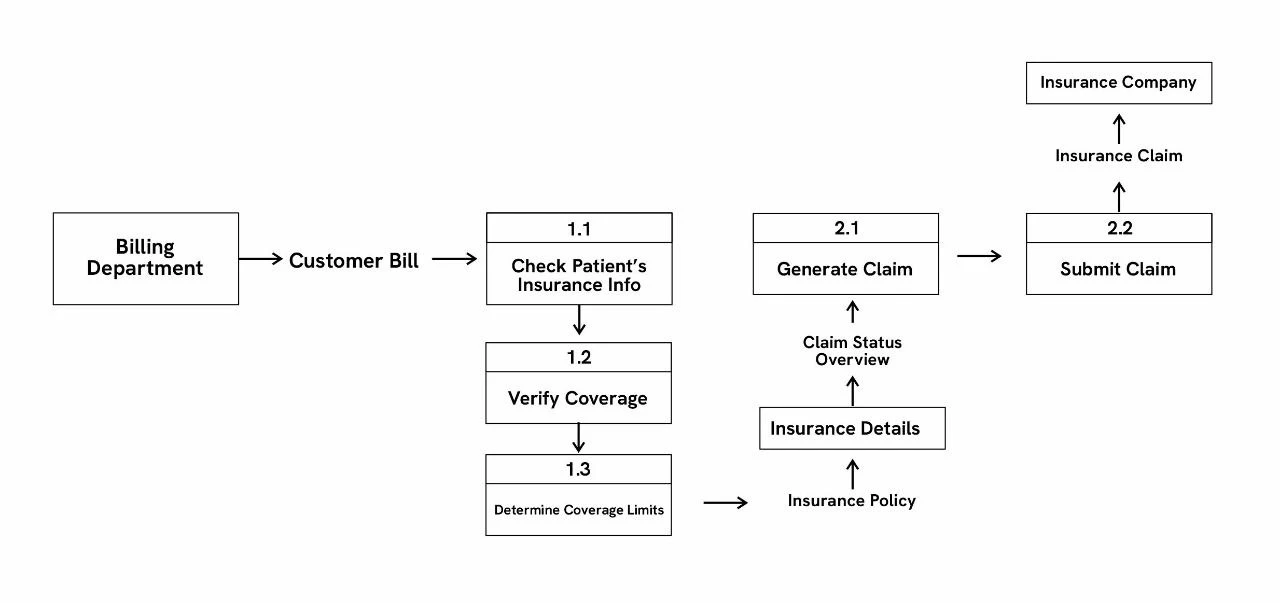
Level 2 DFDs: This level goes even deeper into level 1’s subprocesses. Level 2 DFDs are best for visualizing complex processes, like the enterprise resource planning (ERP) DFD in figure 13.
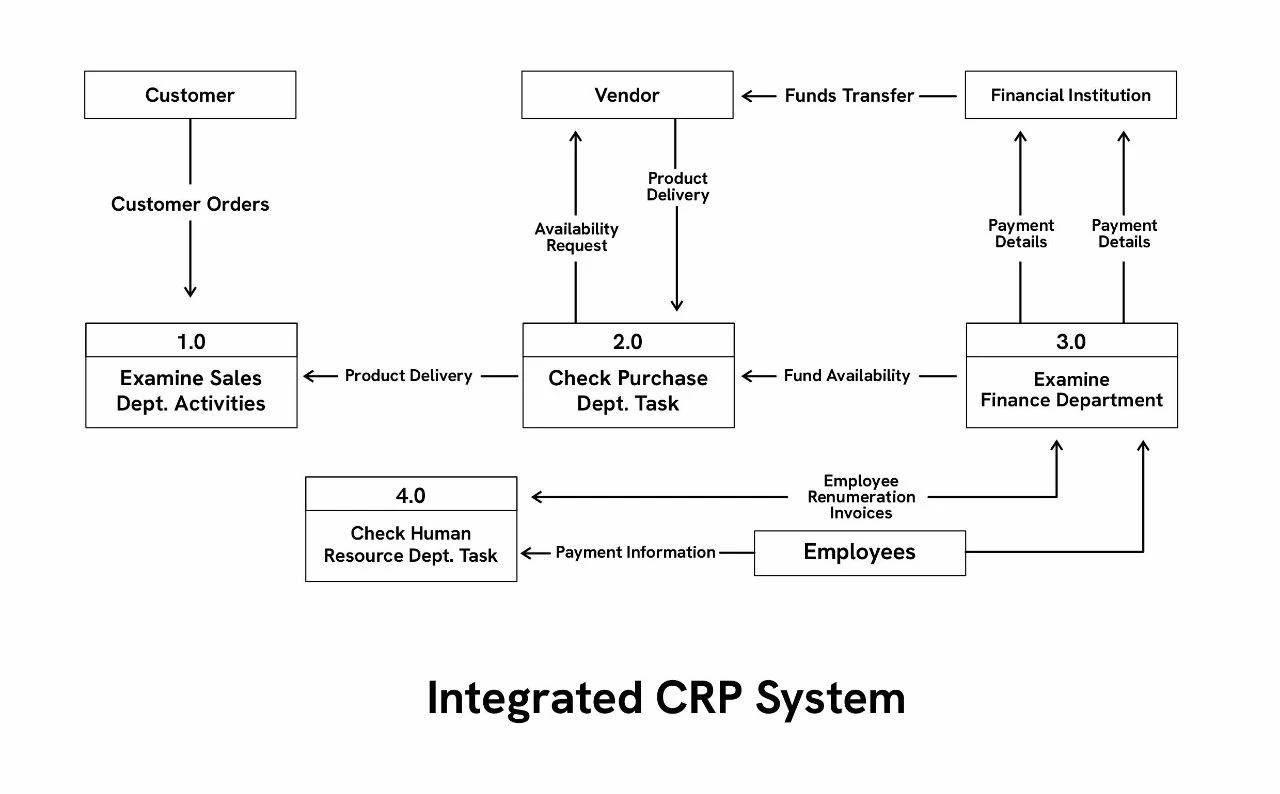
How to create a data flow map
Now that you understand how visualizing data flows enhances security and compliance, let’s explore the step-by-step process of creating data flow maps:
Step 1: Define the scope, including the data flows to cover and the level of granularity required, to make sure the map meets your specific use case.
Say you’re designing a data flow map to see how your organization’s intellectual property flows through your systems. You might decide to capture the high-level processes only, visualizing the entities interacting with your high-risk data. Or you might dig into the subprocesses, visualizing various transformative processes the entities have taken the data through, noting if it remained secure throughout.
Step 2: Map out entities, processes and data stores with access to your data. At this stage, you’ll need to answer questions like, Where’s our data handled and stored—in public clouds or on-premises? Are there external entities interacting with it? How’s the data being shared with them?
Step 3: Stick to the rules by using the appropriate notations to avoid misleading your target audience (your security teams, data protection officers, and other stakeholders).
Step 4: Collaborate with stakeholders to validate and verify your DFD. This will ensure your DFD accurately shows how data flows through your systems.
Step 5: Using insights from the data flow map, scan data and processes for security risks.
Step 6: Update your map regularly as new processes, data stores, and more evolve.
Best practices for creating data flow maps
Creating data flow maps that work begins with adopting the right approach. Here are some best practices to consider:
Start with a context diagram and expand it to your desired level of granularity. This will keep the goal in focus and minimize errors.
Choose the right tools, prioritizing any that provide deep contextual information to help you discover which data is where. An ideal tool should also pinpoint security, performance, and compliance issues that need to be addressed.
Automate where possible to minimize manual errors, ensure accuracy, and enable faster risk detection.
Ensure DFDs follow data security principles like segregation of duties, least privilege, and RBAC to prevent unauthorized access to sensitive data flows.
Work DFDs into data security posture management; use them to uncover data flow vulnerabilities and design security controls.
Common challenges with data flow mapping
Top challenges organizations face when mapping data flows include:
Complexity
Large organizations with many systems and complex data flows might face these common pitfalls that make their data flow maps inaccurate:
Black holes: A process that has an input but no output flow
Miracles: A process that has an output but no input flow
Grey holes: When the input(s) don’t have give enough info for an accurate output
Integration issues
It can be a major challenge to integrate agent-based data mapping tools with the huge range of system components needed to generate accurate data flow maps.
Tool limitations
There aren’t many data flow mapping tools out there that can visualize data flow across all components of your stack and provide key context.
See Wiz Cloud in Action
In your 10 minute interactive guided tour, you will:
Get instant access to the Wiz platform walkthrough
Experience how Wiz prioritizes critical risks
See the remediation steps involved with specific examples
Data flow mapping with Wiz
No doubt, data flow maps make a huge difference in the discovery and remediation of data risks. But without the right tools, creating them can be a major headache. That’s why Wiz offers the joint forces of Wiz DSPM + the Wiz Security Graph to give you essential insights into your enterprise’s data flows.
Wiz’s out-of-the-box data flow mapping is part of our industry-leading data security posture management (DSPM) solution. With Wiz, you can discover where your data is and also create security graphs that map out which entities have access to your data, how data assets are configured and used, and how data moves across your environments. Here’s the step-by-step process:
Discovery: Wiz identifies sensitive data like PII, PHI, PCI, intellectual property, and secrets across all your storage solutions, including public and private buckets, hosted database servers, and cloud-managed SQL databases.
Analysis: The data analyzer detects sensitive data and secrets. These findings are correlated with other risk factors like exposure, vulnerabilities, and data lineage to provide a comprehensive risk assessment.
Graph database: Wiz maintains a graph database that stores data collected from cloud and Kubernetes API connectors and models relationships between resources and risks, giving you a uniform view of your cloud environment.
Visualization: The Security Graph represents your cloud architecture using nodes and edges, modeling relationships and risks to help identify and prioritize remediation efforts.
Do you want to see everything that’s happening with your data? Try Wiz today.
Protect your most critical cloud data
Learn why CISOs at the fastest companies choose Wiz to secure their cloud environments.
