

Data classification is the process of organizing and categorizing data based on its importance and sensitivity. Classifying data lets you protect your most critical assets, make informed decisions about data access and retention, comply with regulations, and mitigate risks.
Data classification is more than just labeling—it's the foundation of modern data security. Effective data classification requires a structured, multi-layered methodology that gives organizations comprehensive visibility and context across their entire cloud data landscape. A robust approach follows four key phases: Cloud Data Inventory, Object Inventory & Pattern Analysis, Classification, and Action—all designed to ensure that your security efforts are targeted, contextual, and effective.
Foundations of Data Security: Classification with Wiz
A deep dive into how Wiz discovers, analyzes, and classifies sensitive data across cloud and DBaaS environments.

In this post, we’ll explore some of the challenges that can complicate cloud data classification, along with the benefits that come with this crucial step—and how a DSPM tool can help make the entire process much simpler.
Why do you need data classification?
When you collect data as part of your business, whether it’s payroll records, credit card data, Social Security numbers, medical records, financial records, intellectual property (IP), or anything else, you need to handle it responsibly.
Data security today is focused on the entire data lifecycle. Handling data isn’t something any organization can take lightly, which is why data security has also been the subject of increasing regulation. That means you need to be aware of proper data handling strategies.
At every stage of the data lifecycle, mishandling data could open your business up to financial loss and reputational damage.
Yet companies often overlook entire stages of this lifecycle in their data security plans. For instance, the final destruction phase might get skipped, leaving data remnants on storage devices even after disposal. Or data may not be as well guarded while in transit, leaving it open to man-in-the-middle and other attacks that take advantage of weak encryption.
Security Leaders Handbook: The Strategic Guide to Cloud Security
Learn the new cloud security operating model and steps towards cloud security maturity. This practical guide helps transform security teams and processes to remove risks and support secure cloud development.
Download

Challenges of data classification in the cloud
Cloud data adds a whole other world of complexity and is more vulnerable for several reasons.
It’s highly distributed, making it tough to track down. It’s ephemeral, which means you can’t always destroy data properly. The shared responsibility model of cloud providers can muddy the waters when it comes to understanding who needs to do what. And finally, you may also have large quantities of shadow data lurking in places you don’t control.
Let’s look at a few of the biggest obstacles in the way of classifying your cloud data.
Cloud environments are constantly changing
Cloud is called cloud because, well, it’s like a cloud: constantly shifting shape based on demand and dozens of other factors. Infrastructure and data are constantly being added, modified, and removed. Plus, you’ve got multiple interconnected components—VMs, storage, databases—making it difficult to identify, track, and classify data.
In addition, third party-providers add complications when it comes to figuring out where your data is, how sensitive it is, and who needs access to it. Subcontractors, for example, may have different data security practices and standards, increasing the risk of security incidents.
Data sprawl and silos
Multi-cloud environments breed inconsistency, almost by definition. Different providers have different security rules, and as your tech stack grows, it becomes harder and harder to keep track of which rules have been applied where. And understanding who has access to which data? Almost impossible.
This can lead to two major problems: data silos and data sprawl.
When you have diverse data types stored in a range of different locations in the cloud, it becomes difficult to manage consistently. Access controls or architectures implemented in one “silo” need to be applied to every other “silo.” This is often a painstaking manual process.
Data sprawl, a subset of the bigger issue of cloud sprawl, happens when data proliferates and duplicates to a point where businesses can lose control. This makes it tough to manage your data and comply with regulations, and it significantly raises the potential for data breaches.
Classifying siloed or sprawling data, especially unstructured data, is notoriously hard using automatic methods. And manual methods are tedious and time-consuming.
User awareness and training needs
Data classification is a big, organization-wide project. That means two things in terms of your users: You need a high degree of buy-in, and you need customized training, because every organization has different needs and industry standards when it comes to classification.
Ideally, you’ll automate as much of the classification process as possible, but there is still some manual intervention required. And if your team isn’t fully on board, and isn’t properly trained, you’re going to wind up with human error—leading to misclassification (oversecuring or undersecuring data) and possibly even accidental disclosure of sensitive data.
How data classification works in the cloud
The goal of data classification is creating and implementing a framework to right-size the security measures your organization needs to take. Not too much, as this is costly and hampers your agility, and not too little, because this opens you up to unwanted risk.
The process of putting this in place will involve cross-disciplinary teams and stakeholders from multiple ranks of your organization. Together, you’ll move through the following steps, which we’ll look at in a little more detail below.
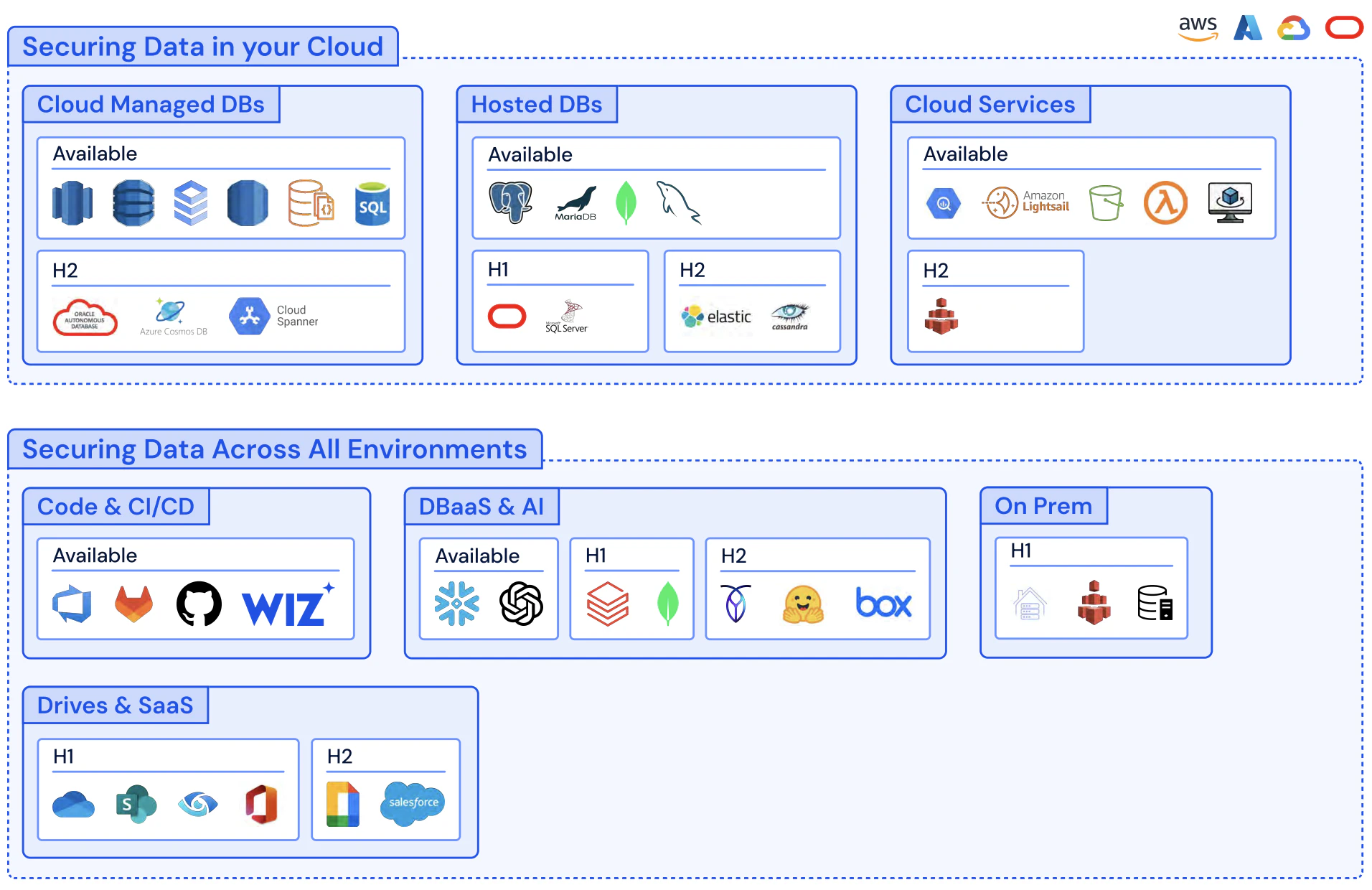
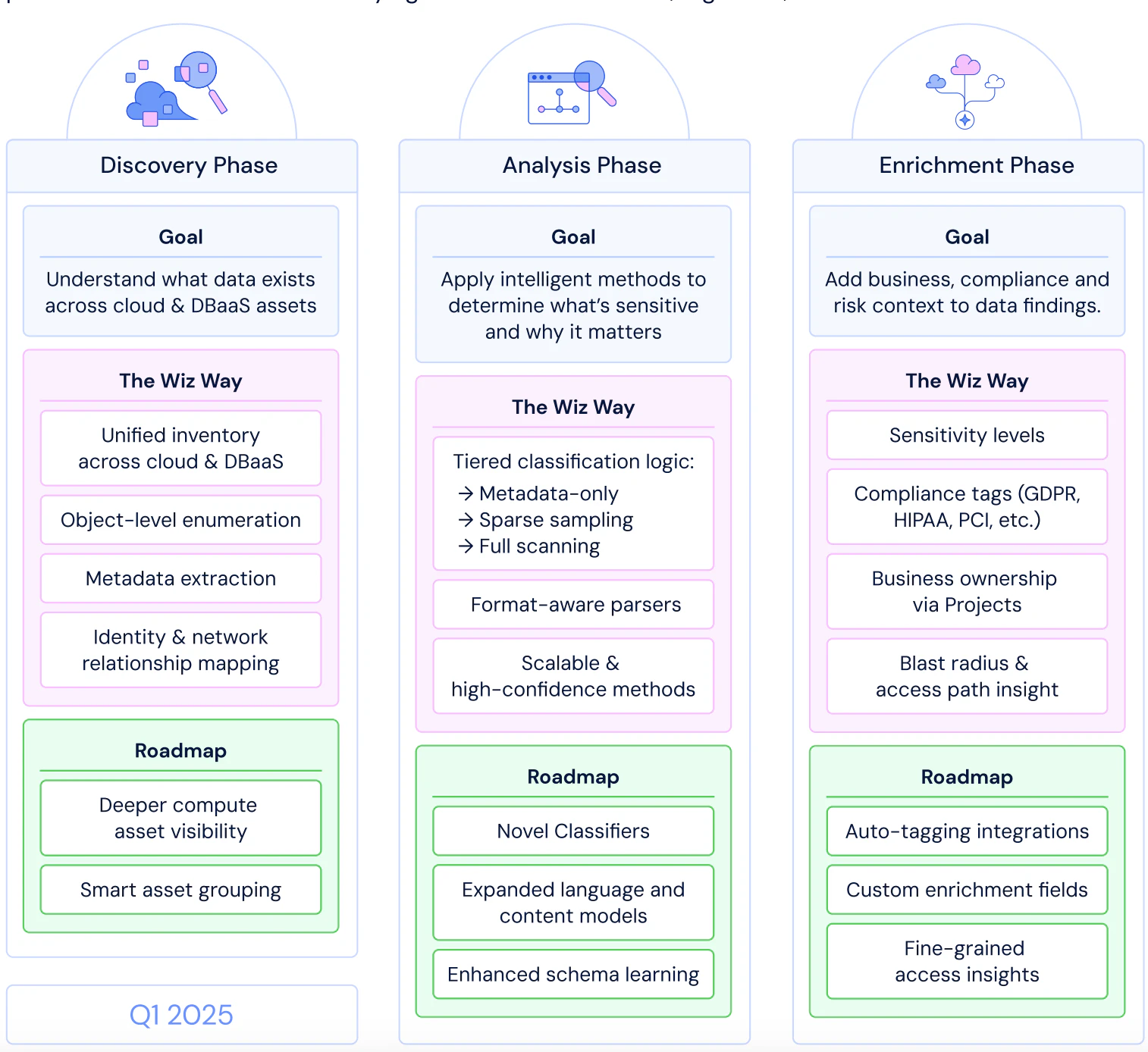
Comprehensive Cloud Data Inventory: Before classification can begin, you need complete visibility into where data lives across multi-cloud environments. This includes:
Multi-cloud coverage across major providers (AWS, Azure, GCP) and managed data platforms (data warehouses, databases)
Deep resource identification for all storage types including object storage, databases, file storage, data warehouses, containers, and ephemeral storage
Metadata collection that captures crucial elements like resource identifiers, creation timestamps, access patterns, region settings, IAM policies, network accessibility, encryption details, and more
Relationship mapping between identities, infrastructure, and data access to provide graph-based visibility of which users have access to sensitive data
This foundational mapping, continuously and automatically refreshed, ensures no blind spots across hybrid and multi-cloud environments.
Object Inventory & Pattern Analysis: Once you know where data lives, you need to understand what those assets contain. This involves:
Scalable object enumeration that adapts based on storage type, whether it's cloud-native snapshots, data warehouses, or unstructured data stores
Advanced metadata extraction and analysis to help fuel classification without inspecting full content
Content sampling and fingerprinting techniques that provide insight with minimal performance impact
Semantic clustering to transform individual objects into meaningful, contextual groups based on patterns and similarities
This intelligent organization of data makes it easier to surface sensitive patterns and understand business context, enabling more accurate classification while optimizing performance.
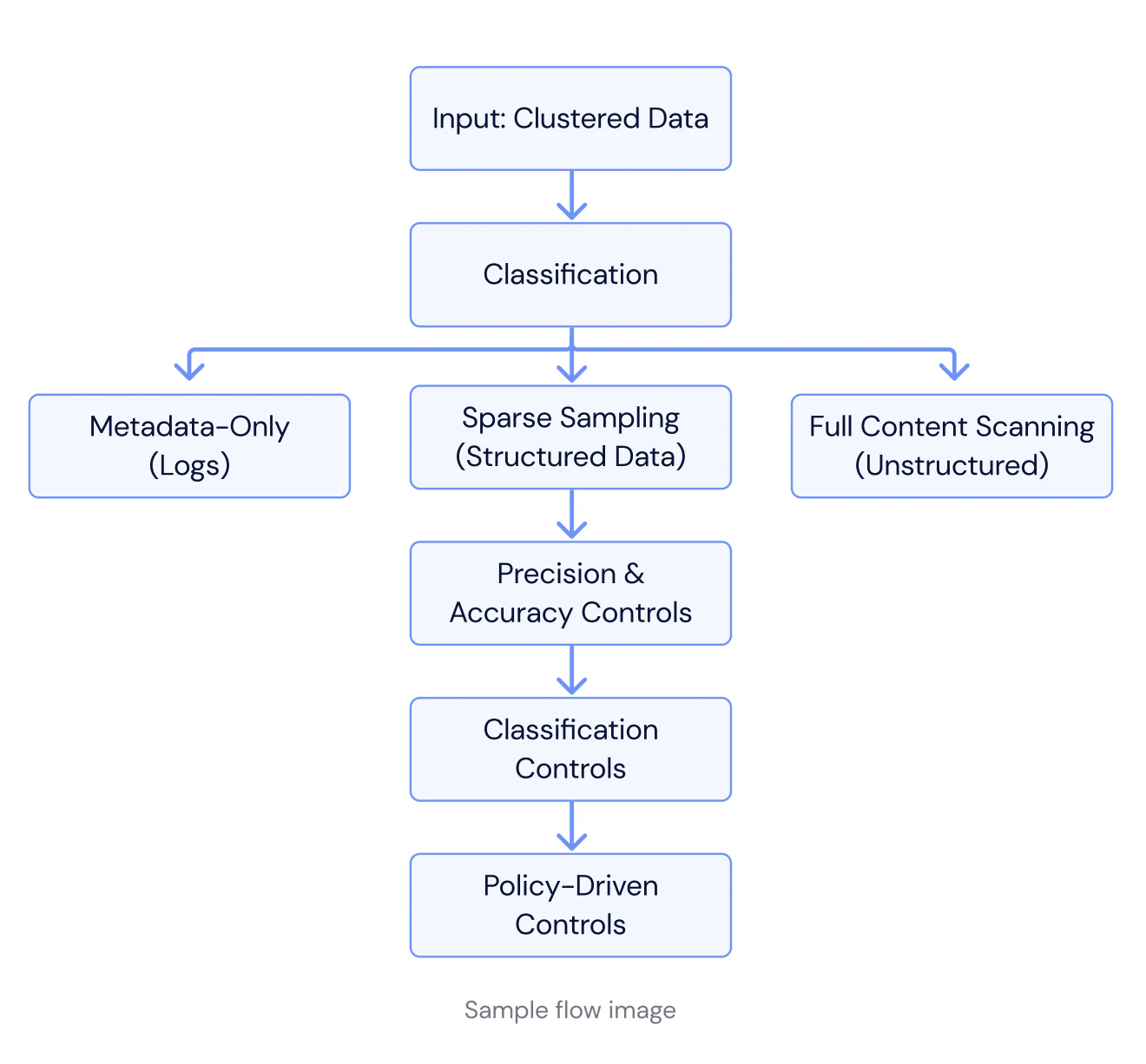
Tiered Classification Methodologies: Rather than using a one-size-fits-all approach, effective classification employs multiple strategies based on data type and context:
Metadata-Only Classification: For well-defined data types like operational logs or cloud-native telemetry, classification can be achieved without scanning content by analyzing naming conventions and patterns.
Sparse Sampling: For large, repetitive datasets like database backups, intelligent sampling classifies content quickly and confidently by validating similarity and incrementally expanding the sample until statistical confidence is reached.
Full Content Scanning: For heterogeneous, unstructured datastores where sensitive data may be embedded unpredictably, deep content inspection identifies embedded sensitive information.
This tiered approach optimizes for both accuracy and performance at scale, ensuring resources are allocated efficiently while maintaining classification accuracy.
Adaptive Classifiers: Tailoring 'Sensitive' to Your Environment: A key innovation in modern data classification is the ability to define what 'sensitive' means in your specific environment. Advanced classification systems can learn from the actual data in your environment to highlight patterns that matter to your business—even when they don't match generic templates. This complements standard classification libraries and custom rules to align with internal policies, contracts, and compliance frameworks.
Enrichment and Precision Controls: Once classification is complete, each finding should be enriched with layered context:
Sensitivity Levels: Tag data as public, internal, restricted, or highly confidential
Compliance Tags: Apply regulatory frameworks like GDPR, HIPAA, PCI DSS, CCPA
Business Context: Map data to ownership teams and business units
Risk Profile: Include potential impact, blast radius, and access paths
To ensure classification results are trustworthy and actionable, implement:
Confidence scoring to assign severity levels for prioritization
False positive reduction through ignore rules
Human-in-the-loop review for validation
Continuous feedback loops to improve classification over time
Policy-driven customization allows you to align classification with your organization's specific standards and risk appetite through custom rules, policy templates, and nomenclature customization.
Remediation: Discovering and classifying sensitive data is essential, but the real value comes from remediating issues to improve your security posture. An effective remediation framework should address these five key areas:
Reduce: Eliminate stale, duplicated, orphaned, or shadow data to mitigate risk and decrease cloud costs, effectively controlling data sprawl.
Restrict: Tighten IAM and network access controls by removing unused or excessive permissions, minimizing potential attack vectors.
Relabel: Ensure all data assets are accurately labeled in accordance with internal policies and industry standards to enhance data governance.
Relocate: Enforce data residency requirements by storing data only in authorized regions, addressing compliance needs and reducing legal risks.
Reconfigure: Implement appropriate encryption, retention policies, versioning controls, and other security configurations to protect data integrity.
Effective remediation strategies should combine manual investigation capabilities, automated remediation workflows, and customized automation to streamline the resolution process. By addressing these five areas systematically, organizations can transition from reactive security practices to proactive data protection.
Free Cloud Security Risk Assessment
Connect with a Wiz expert for a personal walkthrough of the critical risks in each layer of your environment.
Request Assessment

Benefits of classifying cloud data
While handling data is complex, classifying cloud data lets you use your data more securely. Not only that, but knowing exactly what and where your sensitive data is lets you save money and save time when it counts the most—during an audit or security incident. Here are some other benefits:
Enhanced data governance and compliance: Cloud data classification gives you clarity on data ownership and can improve your consistency in data handling. And with a clear audit trail, compliance reporting becomes much simpler.
Better risk management: Cloud data classification helps you prioritize your security efforts and understand where you can improve your program. Insight into data sensitivity helps with risk assessment and management, and it also helps you create business continuity plans that make sense based on actual risk.
Reduced attack surface: Cloud data classification lets you build uniformity and consistency into your security program. This minimizes unauthorized access and lets you target security controls to focus on your most sensitive data.
Faster incident response and breach containment: Finally, cloud data classification helps you deal with incidents in progress. You’ll know exactly where your sensitive data resides, so you can focus containment efforts. You’ll also have a better understanding of the impact and scope, which helps you contain the blast radius and prioritize remediation efforts.
Data security and classification
Cloud data classification is an important step on the way to implementing granular access controls and encryption based on data sensitivity levels. This is the key to least privilege, zero trust, and many other best practices.
Understanding the level of confidentiality and risk for each data type lets you put safeguards in place to protect your most sensitive assets. More importantly, it’s a key enabler for moving towards a data-centric security approach.
Traditional approaches
Traditional approaches to security tend to be perimeter-focused, building “castle walls” around your environment. Traffic is checked at the “gate.” The drawback? Once a user is inside, it’s easy to gain access to sensitive data.
Network-centric approaches build on perimeter-focused techniques by adding access limitations through micro-segmentation and other measures like behavioral traffic analysis. This approach can protect endpoints, networks, and applications. But without a deep awareness of where your crown jewel data is located, it can’t ensure airtight coverage where you need it.

Data-centric security approach
A data-centric approach, on the other hand, works from the assumption that perimeters and networks can and might be breached. So it focuses on protecting the data itself.
Data-centric security is platform-agnostic and works well for today’s distributed workforce. And it saves teams work because monitoring and alerting are prioritized based on classification levels. Data-centric tools let you know immediately when your most essential assets are at risk, so you can lock down your data and minimize exposure.
But data-centric security works from the assumption that you know exactly where your data is and what type of data it is. So you first need to find and classify all your data—an extremely daunting job.
Fortunately, today’s data security posture management (DSPM) tools are up to the task.
The role of DSPM in data classification
DSPM is a tool or toolset that adds data-centric security to your existing security stack. Modern DSPM solutions take a comprehensive approach to data security through:
Unified Visibility: Creating a complete inventory across cloud and DBaaS environments with multi-cloud coverage and deep resource identification.
Intelligent Analysis: Applying tiered classification logic from metadata-only analysis to full scanning, with format-aware parsers and semantic clustering to understand relationships between data assets.
Contextual Enrichment: Adding business, compliance, and risk context to findings, including sensitivity levels, compliance tags, business ownership, and access path insights.
Actionable Remediation: Providing both manual and automated remediation options, including AI-generated remediation steps and customizable automation workflows through third-party integrations.
This comprehensive approach enables organizations to transition from reactive to proactive data security management, effectively mitigating risks across the entire data lifecycle.
Wiz DSPM
When DSPM is integrated with other security tools as part of a cloud native application protection platform (CNAPP), you get the highest possible level of protection for your data by aligning access controls and enabling automated incident response. As part of a CNAPP, DSPM also helps cut alert fatigue and prioritize critical security events by providing context-aware alerts for your top-priority data.
Wiz is a CNAPP solution that builds DSPM right into the mix. It provides all the benefits of DSPM to protect your sensitive data while also performing other mission-critical security tasks.
You shouldn’t have to choose between data-centric security and traditional approaches that focus on networks and apps. Both are important, and that’s why Wiz supports both.
Since your teams have so much on their plate, why not make their lives easier?
Wiz DSPM lets your teams work more effectively because it correlates data from all your security tools, so you can…
Uncover hidden vulnerabilities and apply consistent policies
Assess data risks alongside other cloud risks (to capture more threats)
Enhance compliance with regulatory requirements thanks to continuous assessments
Wiz is easy to roll out and configure. There are no agents to deploy, and you can manage your entire environment through a single pane of glass so that nothing falls through the cracks.
Protect your most critical cloud data
Learn why CISOs at the fastest companies choose Wiz to secure their cloud environments.
