
Data categorization involves identifying where application data resides and then grouping that data based on context and content. Categorization is an essential process. After all, data in modern applications goes beyond databases: It’s typically distributed across silos, and sensitive information may be passed to all components of the application architecture, posing a significant risk to data security.
Another reason data categorization is critical? It’s the starting point of your data security journey. Data categorization is the first step of data security posture management (DSPM), which identifies all the locations where data is, profiles categorized data based on risk, offers root cause analysis, and suggests remediation actions.
In this article, we'll explore the different types of data categorization, strategies for effective management, and how to avoid common pitfalls that can complicate cloud data governance.
Cloud Data Security Snapshot 2025
54 % of cloud environments expose sensitive data on public-facing VMs—prime targets for exfiltration. Benchmark your own exposure and get remediation guidance in the report.
Download snapshot

Data classification vs. categorization: Drawing the line
Over the last few years, data security vendors have started offering sensitive data classification to filter risks based on impact. But sometimes, what they call classification is really categorization and vice versa. If you're a practitioner looking to implement DSPM, it's important to understand the difference in order to achieve your security goals.
Categorization and classification are both data management strategies that aid in strategic decision-making.
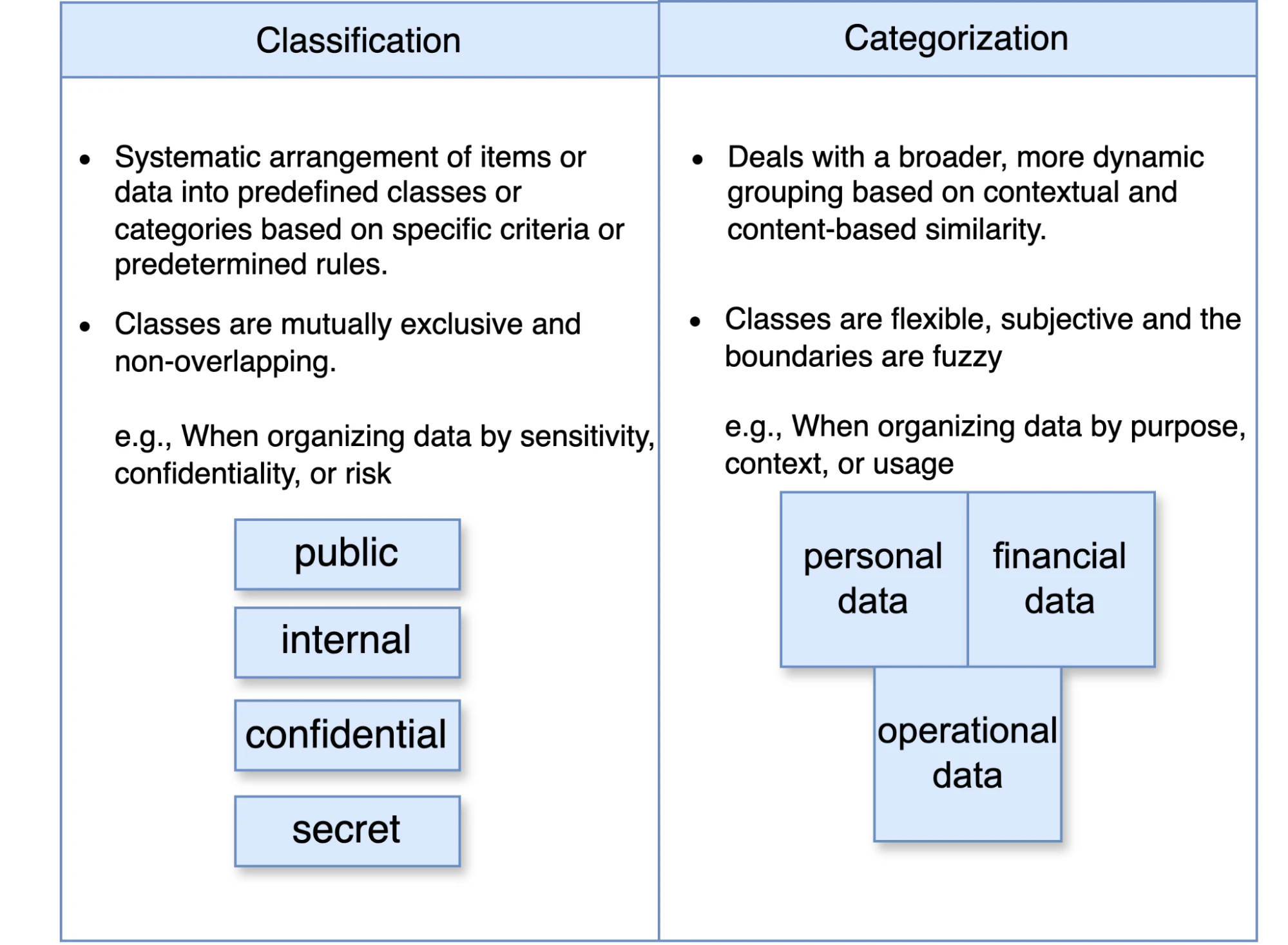
By grouping similar types into accessible categories, we make information easier to use and understand, helping decision-makers draw insights and make informed choices. And while classification also involves organizing data into groups, it primarily focuses on protection and compliance. For example, data labeled as “confidential” is usually encrypted and accessible only to authorized personnel.
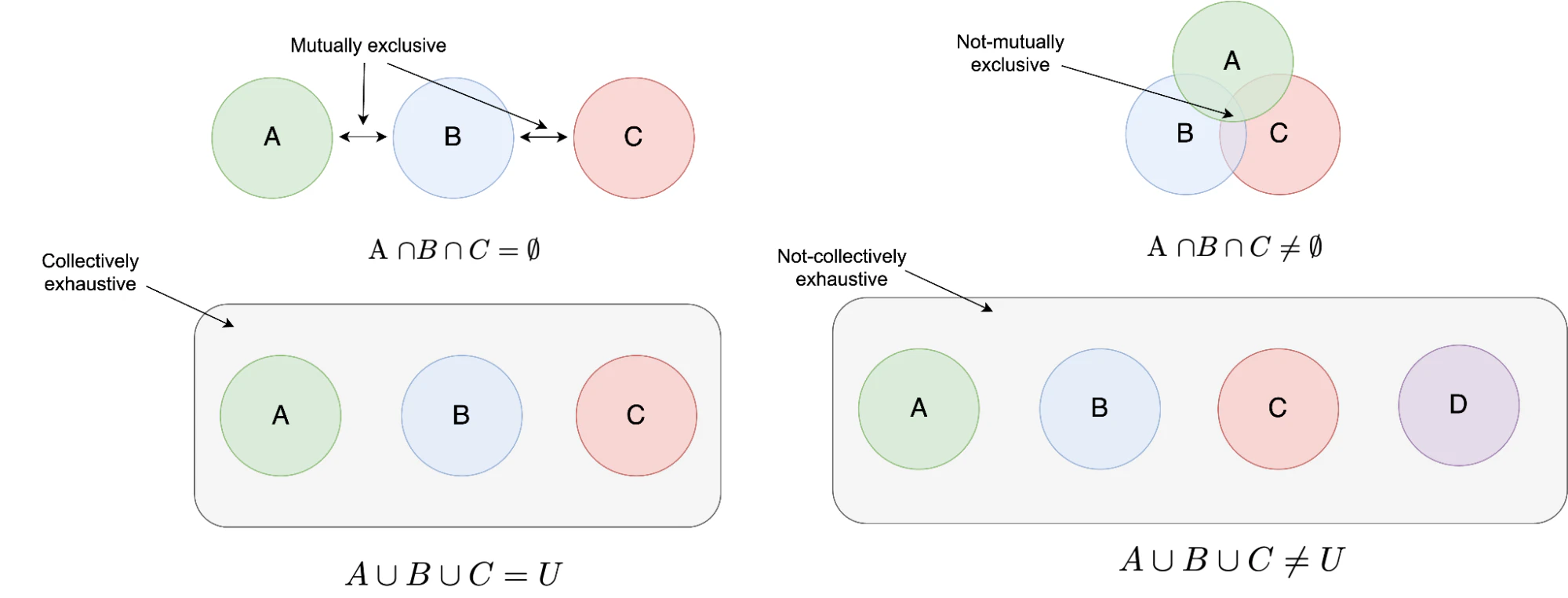
To clearly differentiate between data classification and data categorization, you can use the MECE (mutually exclusive and collectively exhaustive) framework. Data classification always follows MECE. Data categorization, on the other hand, is always non-MECE.
While categorization is often non-MECE, some models attempt to bring a MECE-like structure to categorization, particularly in highly regulated environments or structured data ecosystems. Hierarchical taxonomies, for example, can create clearer, non-overlapping categories by nesting data into parent-child relationships, reducing ambiguity and ensuring consistency.
That said, categorization inherently allows for some degree of overlap because data can belong to multiple categories based on its content, context, or use case. For instance, a financial transaction record might be categorized both under "customer data" and "financial data." Unlike classification, which strictly enforces mutually exclusive categories for compliance and security purposes, categorization focuses on making data more accessible and contextually meaningful across different teams and use cases.
By leveraging structured taxonomies and metadata tagging, organizations can minimize overlap and bring more order to their categorization efforts while maintaining the flexibility needed to support multiple data contexts.
The MECE framework has two parts. First, “mutually exclusive” ensures that there are no overlapping categories, making each class distinctly separate. Second, “collectively exhaustive” means that when you combine all the classes together, they cover all possible data points without leaving anything out.
Typically, data is first identified and then categorized. DSPM solutions can automatically detect data that resides in silos and label it based on contextual and content-based similarities. With categorization, the boundaries between these labels can be fuzzy and sometimes overlap. In other words, data elements might qualify for more than one category, making the categorization collectively inexhaustive.
Once the data is categorized, it is classified by sensitivity, which is then used to identify risk profiles that could lead to data leakages or breaches.
While data categorization is a foundational step in understanding what data you have and where it resides, it is only one piece of a broader data security posture management (DSPM) strategy. A comprehensive DSPM solution, like Wiz DSPM, extends far beyond categorization by integrating security insights, access controls, and attack path analysis to proactively mitigate risks.
Here's how Wiz DSPM takes data security further:
Risk-Based Prioritization – After categorizing data,DSPM automatically assesses its sensitivity and exposure, highlighting high-risk data assets that require immediate attention.
Access Control and Exposure Analysis – DSPM doesn’t just show where data is—it also maps who (or what) has access to it, helping organizations identify excessive permissions and reduce identity-based risks.
Data Movement Tracking – By monitoring how data flows across environments, DSPM can detect unauthorized transfers, shadow data, or potential exfiltration points before they become security incidents.
Attack Path Prevention – DSPM correlates data exposure with real attack paths that adversaries could exploit, helping security teams cut off potential breach points before they can be leveraged.
By embedding categorization within a broader security strategy, DSPM ensures that organizations don’t just know where their data is—but also how to protect it, who is interacting with it, and where security risks may arise.


Types of data categories
Since there are no predefined rules, data categorization is a dynamic process. That said, we can still identify several types of categorization by examining best practices.
Grouping based on data content involves categorizing data based on its subject matter or its intended use. For instance, financial details, personal identification information (PII), health records, and operational data can be categorized into their respective groups.
Grouping based on context takes into account where and how data is used or created. For example, you might sort data according to different business processes, project requirements, or user roles. For instance, data used by the marketing team might be categorized differently from data used by the research and development team, reflecting their different contextual uses.
Grouping based on storage location organizes data based on where it’s stored, such as on-premises servers, in the cloud, or in hybrid environments. Each storage location might have different security and access protocols, making it important to sort data this way to ensure it is managed and protected.
Grouping based on data structure means categorizing data based on its format and structure. Structured vs. unstructured data are the two main categories: Structured data is typically stored in relational databases with clear schema, but unstructured data might not have a schema and are typically stored in non-relational databases. There’s also semi-structured data, which falls somewhere in the middle. It has some organization, often featuring tags or other markers to separate semantic elements and is commonly found in formats like JSON or XML files.


Example
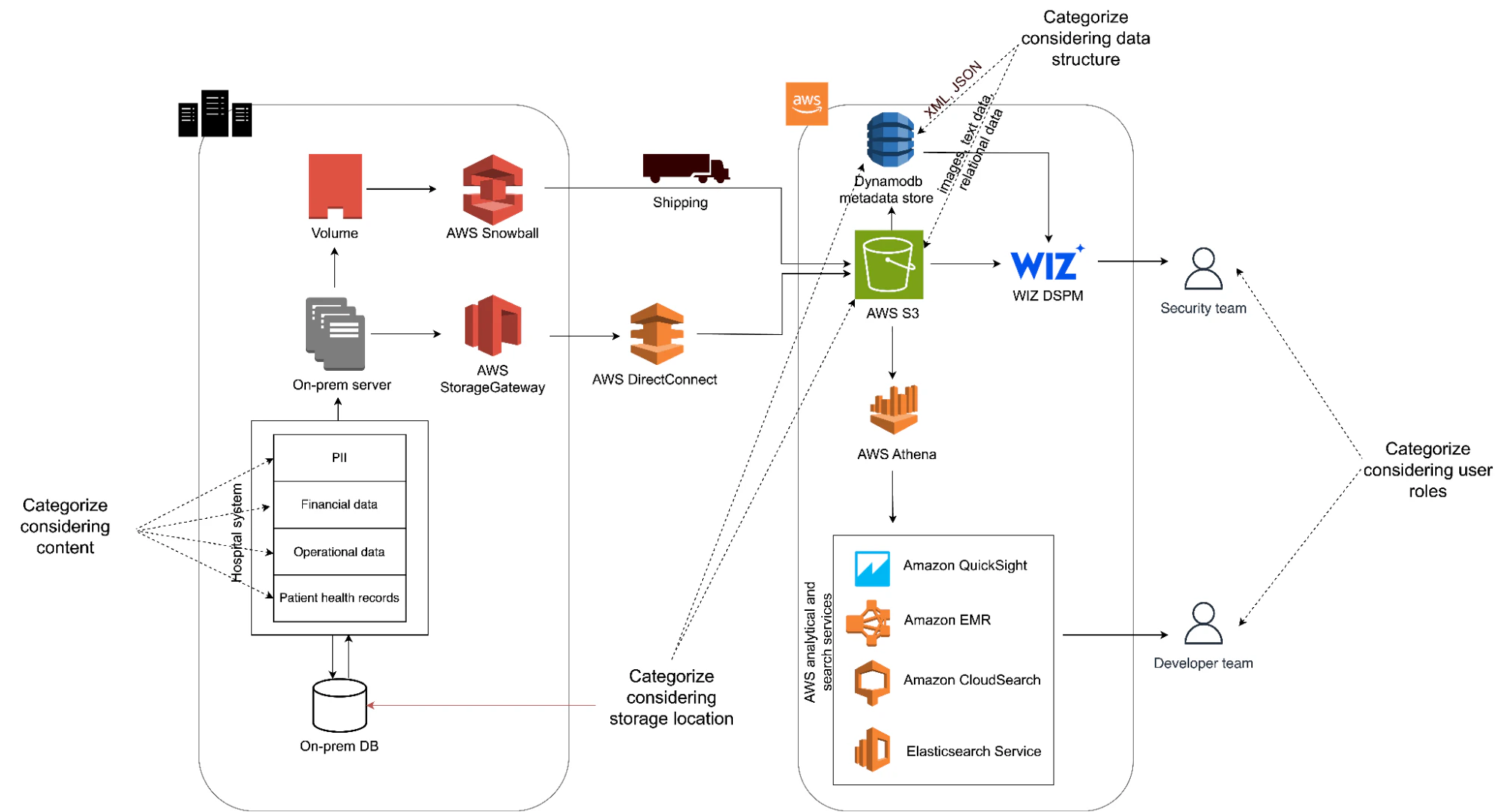
Imagine a healthcare application running in an AWS environment that’s designed to handle, store, and secure large amounts of data (figure 3). We can categorize this data based on content, context, storage, and structure.
Strategies for effective data categorization in your organization
Data categorization strategies and best practices are not there to impose rules on your system. Instead, they guide you in making the right foundational architectural decisions.
Data categorization tools
Using tools is the key to solving the challenges associated with manual categorization. Tools help ingest information hidden in silos, including metadata and shadow data. This information is then categorized and analyzed, aiding in business decision-making.
For enhanced cloud data management and security, there are vendor-specific tools like Amazon Macie, and Microsoft Purview, or even more advanced third-party solutions. DSPM is particularly useful because it goes beyond simple categorization—it correlates data risk with access exposure, maps real attack paths, and proactively prevents security threats. By providing deep insights into where sensitive data is stored, who (or what) has access to it, and how it moves across cloud environments, DSPM enables organizations to take a risk-driven approach to data security.
Unlike traditional categorization tools, DSPM identifies excessive permissions, monitors anomalous access patterns, and visualizes attack paths that could expose critical data assets. This comprehensive view of data security posture allows security teams to move from reactive to proactive defense, preventing breaches before they occur.
DSPM also tracks how data moves, helping you proactively cut off potential attack paths to prevent data leaks and breaches. Recently, DSPM tools have started incorporating AI, further improving the efficiency of automated data categorization.

Developing a data taxonomy for categorization
Data taxonomy is about systematically structuring data into categories (parent nodes), subcategories (terminal nodes), and attributes. This organization reduces the fuzziness in boundaries, makes the data easier to navigate, and maintains consistency across an application’s architecture.
A taxonomy sets specific rules for categorization, such as defining what falls within the scope, the definitions of each category, how these categories are interconnected, and the purpose of each category. If all we have is a category name without any contextual metadata, it might lead to significant data sparsity, complicating security efforts.
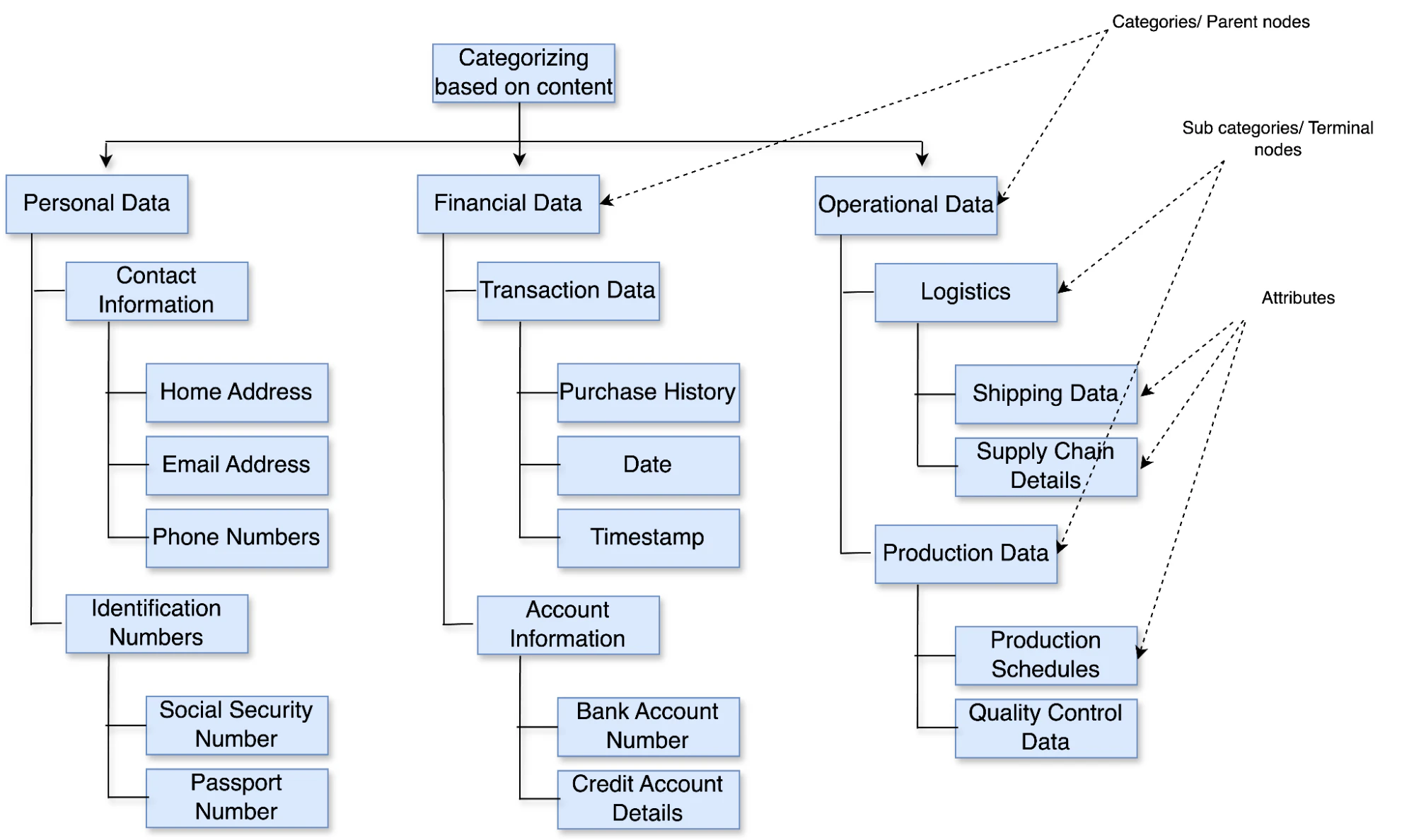
You can improve the organization and searchability of a taxonomy with metadata tagging, which lets you add descriptive labels to categories and subcategories (figure 6).

Data governance and policies
Here are some key data governance frameworks and their take on data categorization:
ISO 8000: Emphasizes organizing data by domains (e.g., supplier data, product data) and ensuring quality and consistency within each domain.
COBIT: Provides a governance framework where each data domain (e.g., customer data, product data, financial data) has defined ownership, responsibilities, and controls aligned with business objectives. This means you can categorize data by its domain or purpose, not just how confidential it is.
GDPR: Requires you to document categories of personal data, data subjects, and processing activities.
HIPAA: Focuses on distinguishing protected health information (PHI) from non-PHI data. The concept of “Designated Record Sets” formalizes which healthcare records fall under HIPAA’s privacy and security rules, grouping them into distinct data categories.
CCPA: Explicitly calls for disclosure of “categories of personal information,” “categories of sources,” and “categories of third parties” in your privacy notices and consumer rights responses.
See Wiz Cloud in Action
In your 10 minute interactive guided tour, you will:
Get instant access to the Wiz platform walkthrough
Experience how Wiz prioritizes critical risks
See the remediation steps involved with specific examples
Conclusion
Mastering data categorization sets the foundation for stronger DSPM. By distinguishing between categorization and classification, mapping out your data taxonomy, and tapping into automated tools, you can tame even the most scattered data environments.
Yet for many organizations, finding and monitoring data across siloed systems remains an uphill battle. That’s where Wiz DSPM comes in. By automatically discovering and categorizing data, Wiz gives you real-time visibility into who has access, how data travels, and where potential leaks might occur. It’s a holistic, streamlined approach that doesn’t just flag issues—it guides you through remediation, keeping sensitive data well-guarded.
If ensuring airtight data categorization while simplifying your security operations is at the top of your list, seeing Wiz in action could be the next step. Schedule a demo and learn how easy it can be to classify, categorize, and protect your critical data with Wiz.
Protect your most critical cloud data
Learn why CISOs at the fastest companies choose Wiz to secure their cloud environments. Get a demo
