


What is attack surface management?
Attack surface management is the continuous process of discovering, classifying, validating, and remediating every digital asset and exposure that an attacker could target. It covers everything from internet-facing web applications to internal misconfigurations buried deep inside your cloud environment.
The goal is straightforward: give security teams an always-current, attacker's-eye view of their organization so they can find and fix exposures before adversaries do.
Before going further, it helps to distinguish a few terms that people often use interchangeably:
Attack surface: The total collection of all points where an unauthorized user could attempt to enter or extract data from your environment.
Attack vectors: The specific methods an attacker uses to exploit an entry point, such as phishing, exploiting an unpatched API, or social engineering.
Vulnerabilities: Specific weaknesses in software, configuration, or design that an attacker could leverage as part of an attack vector.
Threat surface: The subset of the attack surface currently targeted by active threats. The attack surface is broad and relatively static; the threat surface shifts with attacker behavior.
The word "continuous" is what separates this discipline from a traditional asset inventory. Your attack surface changes every time a developer provisions a cloud resource, deploys a container, connects an API, or spins up an AI inference endpoint. A one-time inventory is outdated within hours.
Watch 12-min Wiz demo
Watch how Wiz automatically discovers external-facing assets, validates real exploitability, and connects exposures to internal cloud context

Why are companies seeking attack surface management?
Traditional security models assumed a relatively stable set of known assets behind a firewall. That assumption broke years ago. Cloud adoption, API proliferation, remote work, IoT and OT devices, and AI workloads have made the attack surface dynamic, distributed, and harder to track than anything security teams managed a decade ago.
Consider a concrete example. Cloud resources like storage buckets and serverless endpoints receive provider-assigned public addresses (e.g., name.s3.us-east-2.amazonaws.com) that sit outside your organization's known DNS space. Conventional external scanners built around known domain inventories will never find them.
Wiz Research found that 39% of cloud environments had at least one significant exploitable risk in the past six months. The surface keeps growing in other directions too. Vendor integrations, SaaS platforms, and supply chain dependencies create connection points that attackers can exploit, and 65% of large organizations cite them as their greatest cyber resilience challenge.
Meanwhile, organizations deploying AI models, training pipelines, and inference endpoints are adding entirely new categories of assets that most legacy tools were never designed to discover.
This discipline also supports compliance programs that require continuous visibility into public-facing assets and exposures. PCI DSS 4.0 requires organizations to scan external attack surfaces and protect public-facing applications. NIST CSF 2.0 emphasizes asset identification and risk understanding. SOC 2 common criteria such as CC6 and CC7 expect organizations to control access and monitor security events. Frameworks like GDPR and ISO 27001 mandate ongoing risk assessment and data protection controls.
What are the types of attack surfaces?
Attack surfaces span multiple dimensions. Understanding each type helps you spot where blind spots are most likely to hide and which tools cover each.
External attack surface
The external attack surface includes every internet-facing asset: domains, IP addresses, APIs, web applications, certificates, and exposed services. This is the traditional focus of external attack surface management (EASM) tools.
The limitation is that outside-in scanning alone cannot tell you what an exposed asset can reach internally. It cannot tell you whether that asset holds admin credentials or connects to sensitive data stores.
Internal attack surface
The internal attack surface covers misconfigurations, overprivileged identities, lateral movement paths, unpatched workloads, and insecure network segmentation inside your environment. Identity and access permissions, such as service accounts, IAM roles, stale credentials, and excessive standing access, are increasingly the primary internal surface.
This internal context is what determines the true blast radius of any external exposure. An internet-facing VM with read-only access to a test database is a very different risk than one with admin access to production PII.
Cloud and API attack surface
Cloud environments introduce patterns that traditional tools struggle with: storage buckets with public URLs, dynamically assigned IPs, serverless endpoints, container registries, and ephemeral workloads that exist for minutes. Multi-cloud environments compound the problem because AWS, Azure, and GCP each use different resource names, identity models, and network constructs.
Every API endpoint is also an entry point with its own authentication, authorization, and input validation surface. Akamai documented 150 billion web application and API attacks from 2023 through 2024, confirming that APIs have become a primary attack vector.
AI attack surface
AI systems bring their own exposure patterns: inference endpoints accessible over the internet, publicly reachable training data stores, model API keys embedded in client-side code, and overprivileged AI service accounts.
Here is a practical example. A publicly accessible SageMaker notebook or Azure ML inference endpoint might run with an overprivileged IAM role that can read from a training data lake containing PII. The exposed AI asset is not just internet-reachable. It also has a path to sensitive data, turning an isolated configuration issue into a material exposure.
Emerging threats like prompt injection, model inversion, training data poisoning, and insecure model serialization add risk categories that conventional tools do not assess. Securing AI systems needs to be a core part of any modern security strategy.
Human and social engineering attack surface
Phishing, pretexting, baiting, and impersonation attacks target human psychology rather than technical vulnerabilities. Insider threats from employees, contractors, or partners with legitimate access can bypass technical controls entirely.
Physical device theft and unauthorized facility access round out this category. Security awareness training, phishing simulations, and strong authentication, including multi-factor authentication (MFA) across all accounts, are critical complements to technical controls.
The Overlooked Attack Surface: Securing Code Repositories, Pipelines, and Developer Infrastructure
Read more

How does attack surface management work?
This discipline follows a continuous lifecycle. Discovery without context creates noise. Context without discovery leaves blind spots. The quality of each step depends on how much of both you have.
Discovery and mapping
Discovery means finding every asset across external and internal environments: domains, IPs, cloud resources, APIs, AI services, IoT devices, SaaS integrations, and shadow IT. The hardest part is shadow cloud, where resources with provider-assigned addresses sit outside known domain inventories.
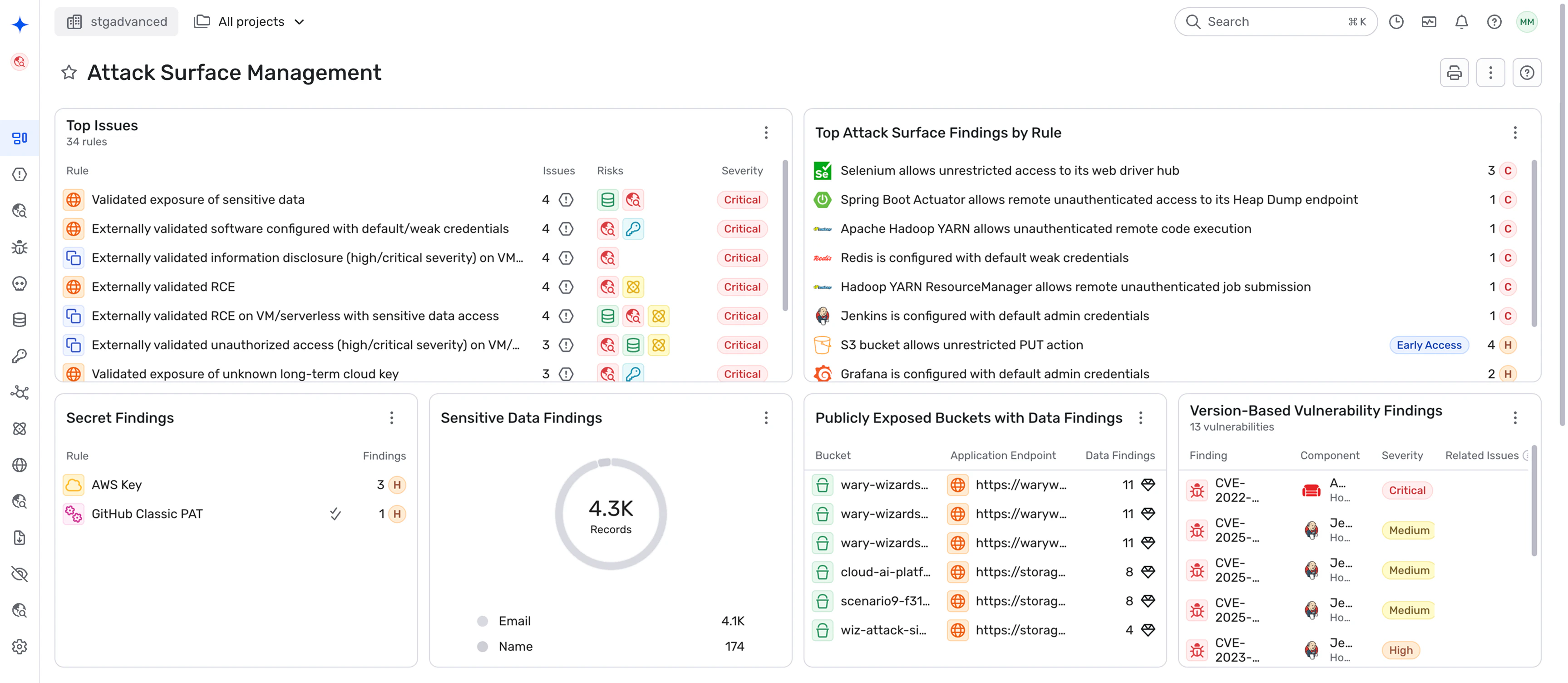
Combining cloud API-based inventory (inside-out) with external scanning (outside-in) closes the gaps that either approach misses alone. Discovery should also categorize what it finds:
Known assets: Actively managed resources your team tracks.
Unknown assets: Shadow IT, orphaned resources, and forgotten services that still consume network resources.
Third-party and vendor assets: SaaS integrations, APIs, and supply chain components you do not directly control.
Rogue or malicious assets: Attacker-created lookalike domains or leaked credentials found on the dark web.
Classification and context
After discovery, each asset needs to be categorized by type, environment, owner, and business function. Then it gets enriched with internal context like identity permissions, data access paths, and network connectivity.
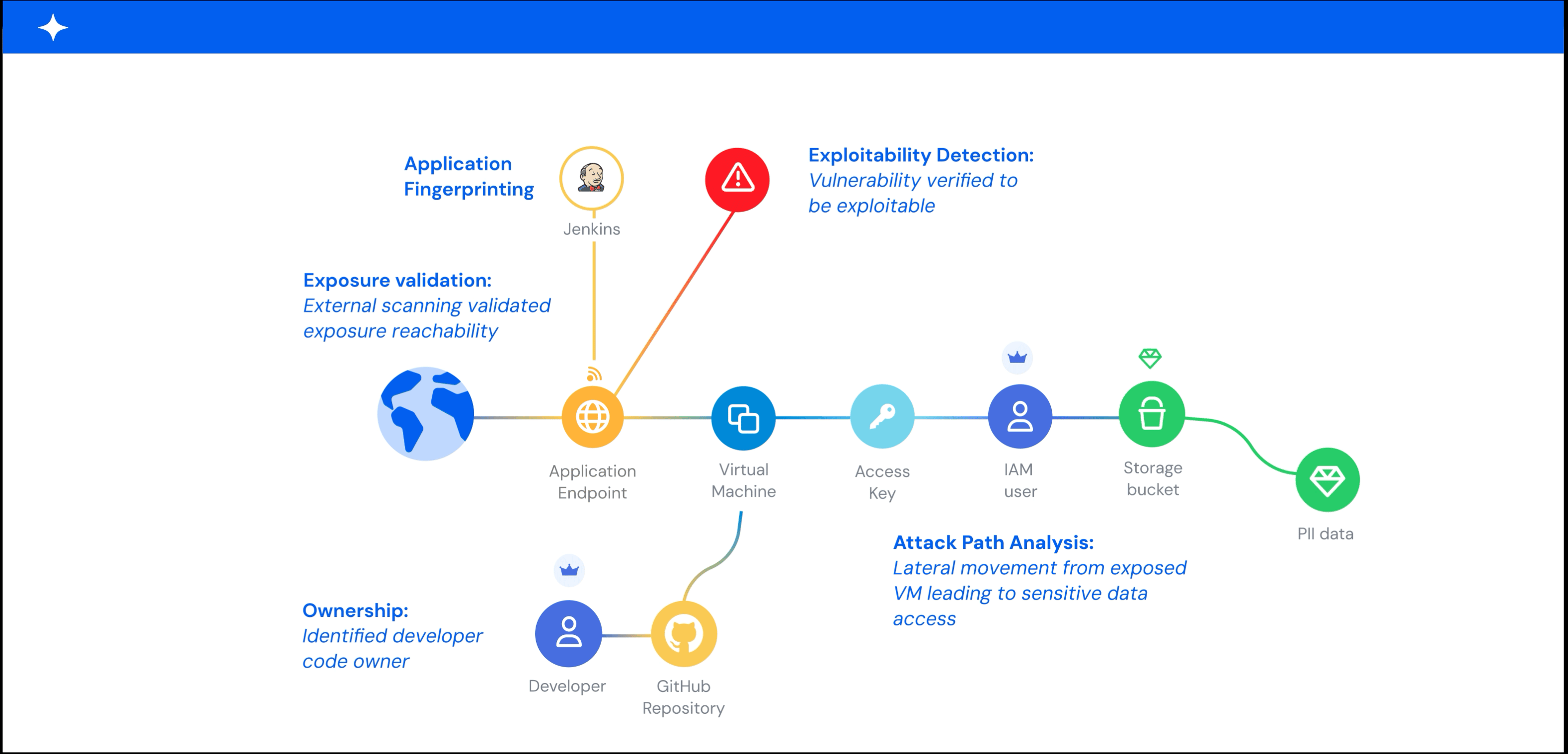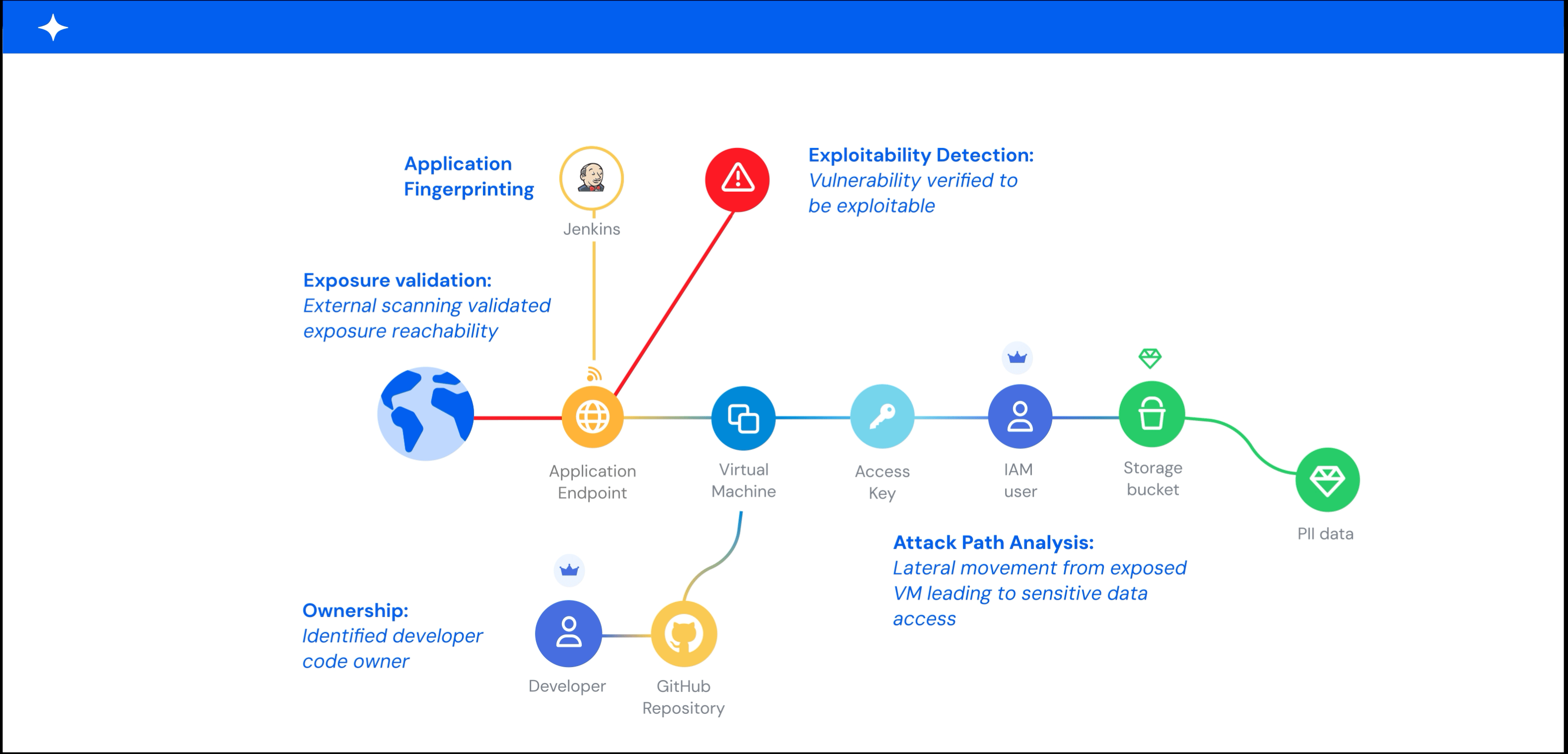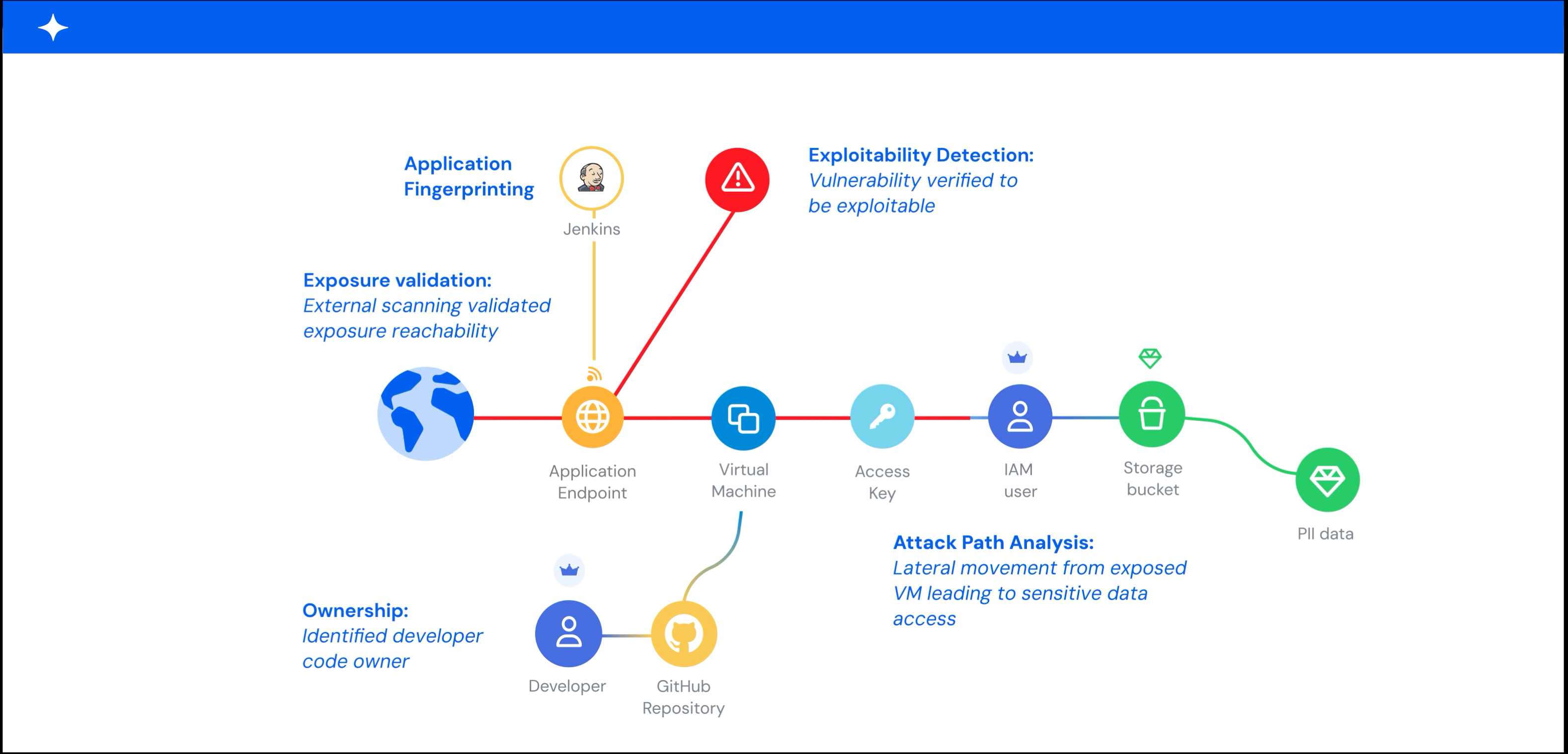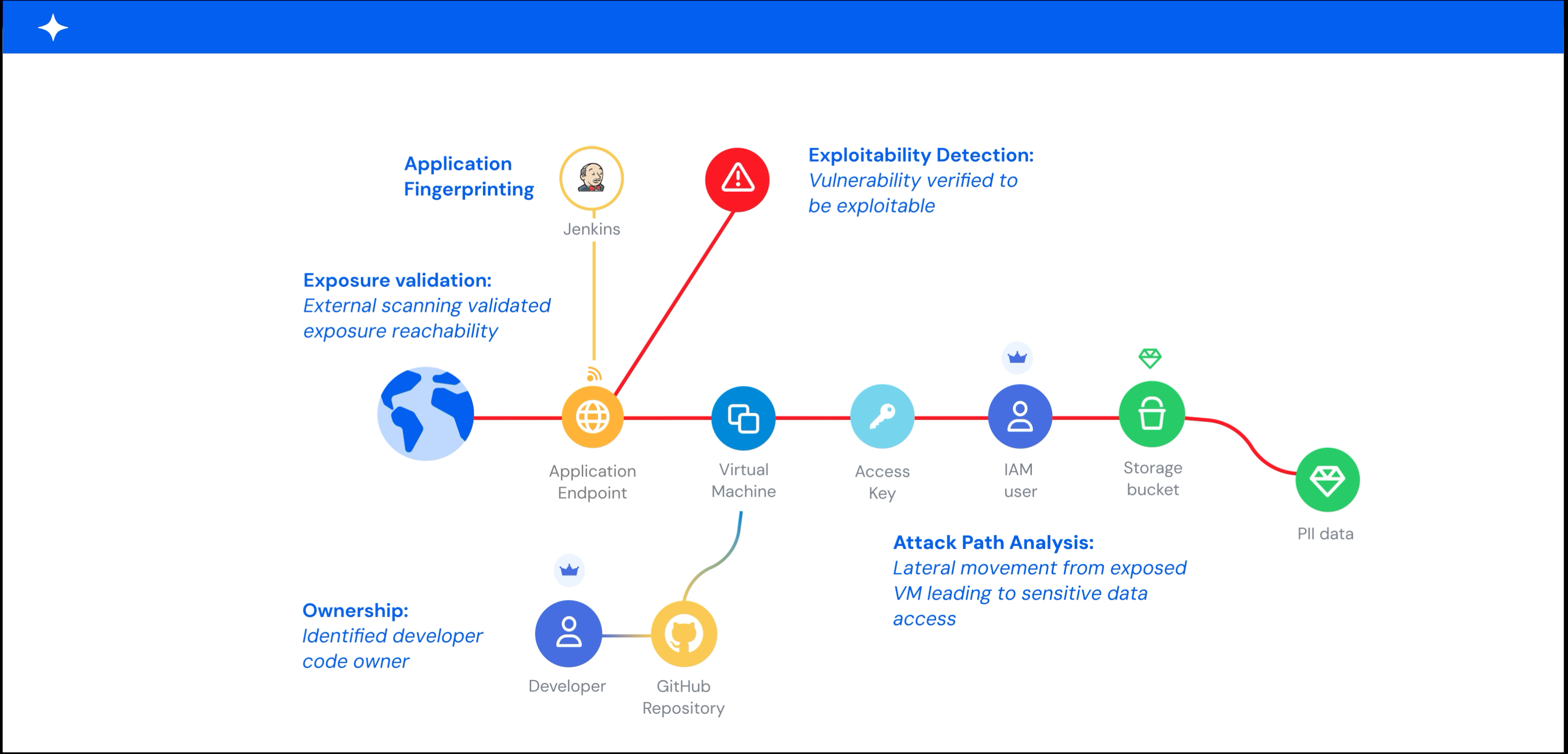
A graph-based model makes this context actionable. It maps relationships between assets, identities, permissions, network paths, and data stores, and it shows which exposures create real blast radius or lateral movement paths. Without that internal context, you end up with flat, unprioritized asset lists that overwhelm teams.
Validation and testing
There is a big difference between theoretical risk and validated risk. A CVE existing on a host is theoretical. An attacker being able to reach that host, exploit the CVE, and access production data is validated.
The strongest validation combines what external scanning reveals with what internal cloud context confirms, correlating an externally reachable exploit with the identity permissions, data access paths, and network connectivity visible only from inside the environment. Techniques like penetration testing, red teaming by ethical hackers, and dynamic application security testing (DAST) add depth that automated scanning alone may miss.
How to prioritize what matters
The shift in modern programs is from "how many assets are exposed" to "which exposures actually lead to business impact." Walk through a narrowing example.
You start with 171 instances flagged for running IMDSv1, the exploitable version of the cloud instance metadata service. Filter to only those that are internet-facing and the number drops sharply. Filter again to those with a vulnerability that has a known exploit, and it drops further. Add data access context, and you are left with a handful that also reach sensitive data.
Individual findings that are low or medium severity in isolation can become critical when they appear together on the same asset. These toxic combinations, where a misconfiguration, an exploitable vulnerability, and a path to sensitive data all converge, are far more actionable than isolated vulnerability scores.
Remediation and ownership
Knowing who owns an exposed asset is as important as knowing the asset is exposed. Tracing an exposure back through the deployment pipeline to the specific code repository, IaC template, and developer who introduced it turns remediation from a ticket-passing exercise into a targeted fix at the source.
The fix should integrate into existing developer workflows: ticketing systems, CI/CD pipeline guardrails, and connections to SIEM, EDR/XDR, and SOAR platforms for automated response. When remediation lives inside the tools developers already use, it actually gets done.
How do you reduce your attack surface?
Visibility alone does not reduce risk. You have to act on it. These are the strategies that make the biggest difference.
Eliminate unnecessary exposure: Remove unused assets, decommission forgotten services, and close open ports. Automated asset aging reports prevent drift.
Enforce least privilege and strong authentication: Implement MFA across all accounts, apply role-based or attribute-based access control, and audit IAM regularly for stale credentials.
Segment networks and apply zero trust: Break networks into isolated segments. Verify every session and trust nothing by default.
Patch based on exploitability: Prioritize patches by real-world exploitability and business impact, not just severity scores. Encrypt sensitive data at rest and in transit. Never leave default credentials in production.
Manage third-party risk: Assess vendor security posture, monitor supply chain connections for credential leaks, and require SBOMs from software suppliers.
Train people as a security layer: Run regular security awareness training with social engineering modules. The human attack surface bypasses technical controls entirely.
What are the challenges in attack surface management?
Even with strong tooling, several challenges persist across organizations of every size.
Shadow IT and shadow cloud: Cloud-native assets, undocumented API endpoints, and orphaned resources sit outside your known inventory and evade traditional scanning.
Identity and permissions blind spots: Most tools treat every exposed asset as equal severity, ignoring the permissions and data access that determine actual blast radius.
Ownership gaps: Security teams flag exposures but cannot determine who should fix them, leaving critical issues open for days or weeks.
Tool sprawl and fragmented context: Separate tools for external scanning, vulnerability management, cloud posture, and identity each produce findings without shared context, forcing manual correlation.
Third-party and supply chain opacity: Vendor-related assets and SaaS integrations expand the surface beyond your direct visibility and control.
Attack surface management vs. related disciplines
This discipline overlaps with several adjacent categories. Understanding where they differ helps you choose the right combination of tools.
| Category | Scope | Perspective | Context depth | Primary use cases |
|---|---|---|---|---|
| ASM | External + Internal | Outside-in + inside-out | Deep (exploitability + blast radius) | Continuous exposure reduction |
| EASM | External only | Outside-in | Limited internal context | Discovering unknown external assets |
| CAASM | Internal (asset inventory) | Inside-out | Moderat (aggregated tool data) | Building a complete asset inventory |
| CSPM | Cloud scope | Inside-out | Deep cloud context, no external validation | Detecting cloud misconfigurations |
These categories are converging. Vulnerability management works from a provided list of known assets. Attack surface management builds its own list, discovering assets that some vulnerability scanners may never see. CSPM monitors cloud configurations from the inside; the attacker's external perspective adds validation of whether those misconfigurations are actually reachable. Penetration testing delivers targeted, point-in-time depth. Continuous monitoring delivers breadth. They all complement each other.
How Wiz approaches attack surface management
Wiz tackles the core problem described throughout this guide: fragmented tools, missing context, and alert noise that bury real risk.
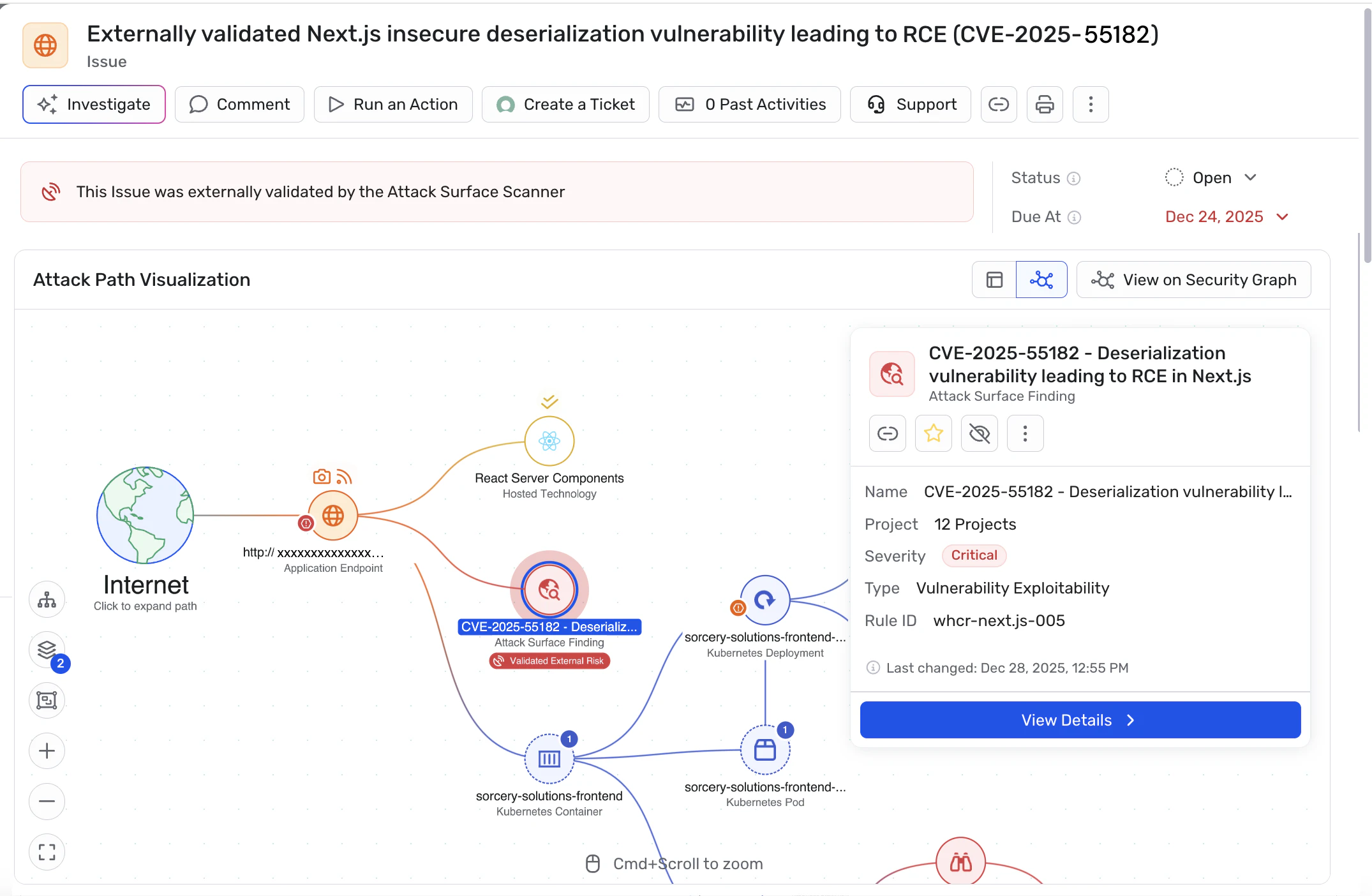
It starts with discovery. The Wiz ASM Scanner continuously finds external-facing assets, including shadow cloud resources with provider-assigned addresses, across cloud, AI, on-prem, and SaaS environments. You do not need to configure or maintain asset lists. The scanner then tests for real-world exploitability across web applications and APIs, checking for vulnerabilities, misconfigurations, exposed sensitive data, and default credentials.
When the scanner confirms a real risk, that finding flows into the Wiz Security Graph. This is what turns isolated alerts into actionable intelligence. The graph connects each finding to the identity permissions, data access paths, network connectivity, and code-level ownership from Wiz Code. So a single issue can show you the external exposure, the validated exploit, the sensitive data at risk, and the developer who owns the IaC template, all in one view.
Combined with Wiz UVM for ingesting third-party findings from tools like Qualys and Rapid7, real-time CSPM for continuous misconfiguration detection, and Wiz Defend for runtime threat detection and response, Wiz forms the foundation of a native cloud CTEM program.
Request a demo to see how Wiz unifies external and internal visibility with the context your team needs to fix what matters first.
See How Wiz Maps and Shrinks Your Attack Surface
Get a personalized walkthrough of Wiz ASM to see how agentless discovery, exploitability validation, and the Wiz Security Graph help your team find, prioritize, and fix the exposures that matter most
