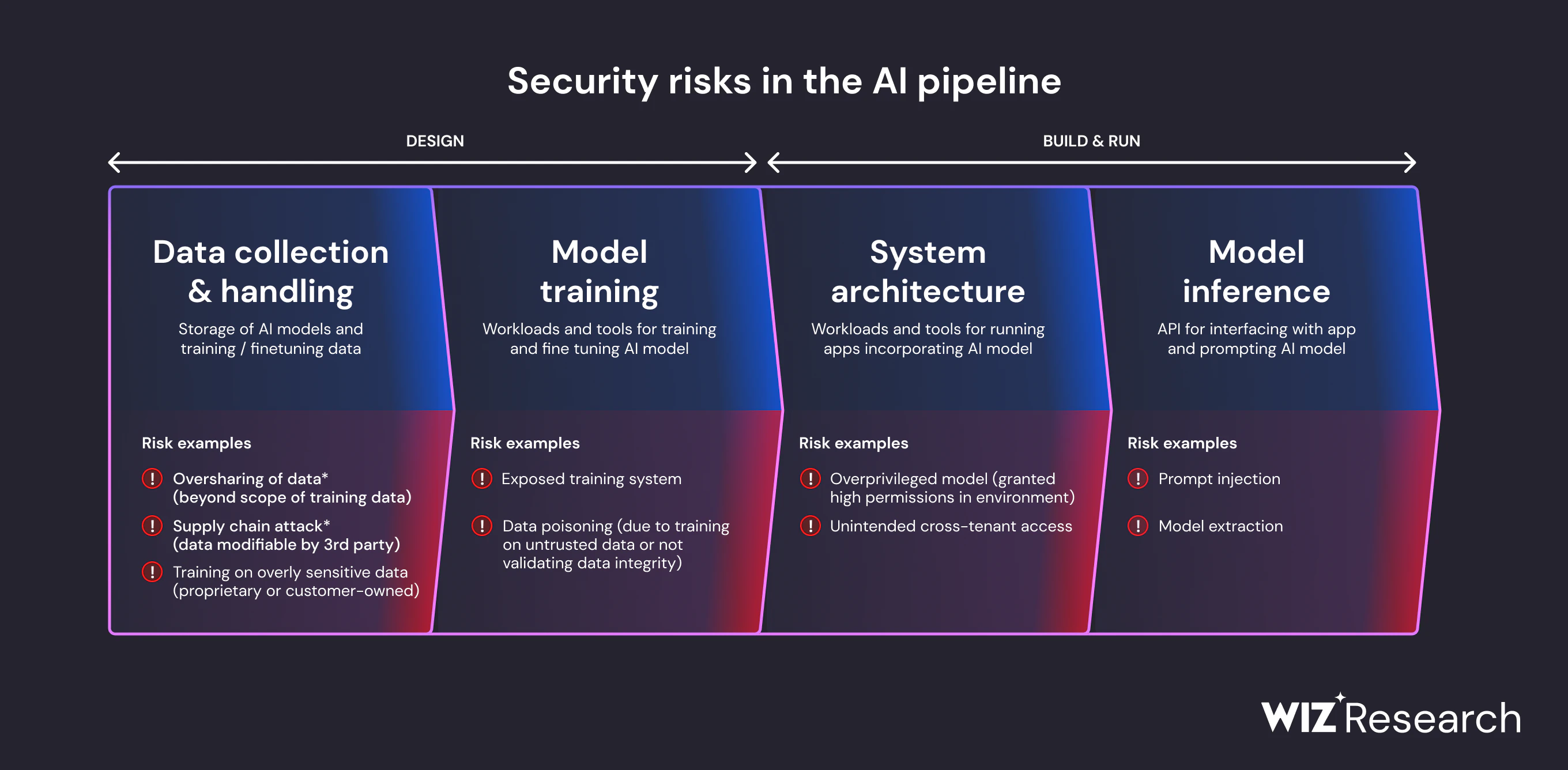
If you've experimented with AI within your organization, you know that it has incredible potential. But with that great power comes the even greater potential for an expanded attack surface.
Case in point: the recent findings related to Slack AI.
In 2024, security researchers discovered that attackers can manipulate Slack AI’s features to expose sensitive data through prompt injection attacks. They can then potentially trick the AI into revealing information from private channels that they don't have access to or embed malicious instructions in uploaded files that the AI processes. Plus, they could even manipulate the AI to create convincing phishing links within its responses.
You wouldn't want any such vulnerabilities in your systems—so it’s important to understand the risks at each stage of the AI development process and implement corresponding security measures.
AI Security Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

The top 7 AI security risks and how to mitigate them
Let’s explore the different types of AI risks, along with potential attack scenarios and mitigation recommendations:
1. Limited testing
AI models can behave in unexpected ways in production, which can adversely affect user experience and open up the system to a variety of known and unknown threats.
Real-life attack scenarios:
Malicious actors might manipulate the model’s behavior by subtly altering the input data (evasion attack) or by strategically positioning and manipulating data during model training (data poisoning attack).
Mitigation:
Introduce a wide variety of real-world examples and adversarial examples to test datasets.
Establish a comprehensive testing framework that encompasses unit tests, integration tests, penetration tests, and adversarial tests.
Advocate for adversarial training during model development to enhance model resilience against input manipulations.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

2. Lack of explainability
AI models can also behave in ways that are hard to understand and justify. But the less you understand AI logic, the harder it is to perform testing, which leads to reduced trust and an increased risk of exploitation.
Real-life attack scenarios:
An attack could attempt to reverse engineer the AI model to gain unauthorized access (model inversion attack). An attacker could also manipulate input data directly (content manipulation attack) to compromise your model.
Mitigation:
Advocate for the use of interpretable models and techniques during model development.
Implement post hoc explainability techniques to analyze and interpret the AI model’s decisions after deployment.
Establish clear, documented guidelines that AI developers can use as a reference point to maintain transparency.
3. Data breaches
The exposure of sensitive data can harm customers and cause business disruptions. Furthermore, data breaches often lead to wide-reaching legal consequences that result from regulatory non-compliance.
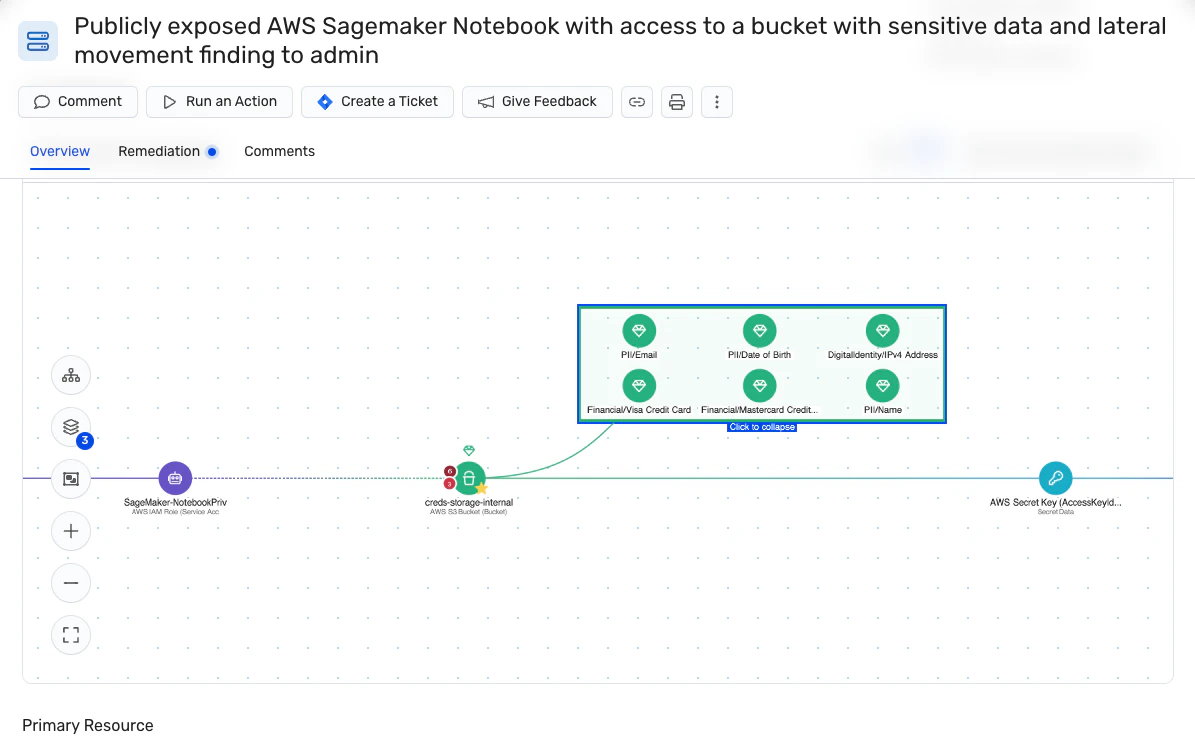
Real-life attack scenarios:
Cybercriminals might attempt to determine if an AI model includes a specific individual’s data (membership inference attack) or analyze the model’s output to extract sensitive information (attribute inference attack).
Generative AI (GenAI) applications, especially those built on large language models (LLMs), are particularly sensitive to these types of attacks, so it’s important to monitor GenAI security closely.
Mitigation:
Implement robust encryption for data at rest and in transit.
Ensure the use of differential privacy techniques during model development.
Regularly audit and monitor access to sensitive data following the principle of least privilege.
Adhere to data protection regulations like GDPR.
4. Adversarial attacks
Adversarial attacks compromise the integrity of the AI models, which results in incorrect or unwanted outputs that undermine system reliability and overall security posture.
Real-life attack scenarios:
Threat actors could aim to exploit the model's sensitivity to changes in input features by manipulating gradients during the training process (gradient-based attack). Threat actors can also reduce the model’s resistance to attacks by manipulating input features (model evasion through input manipulation).
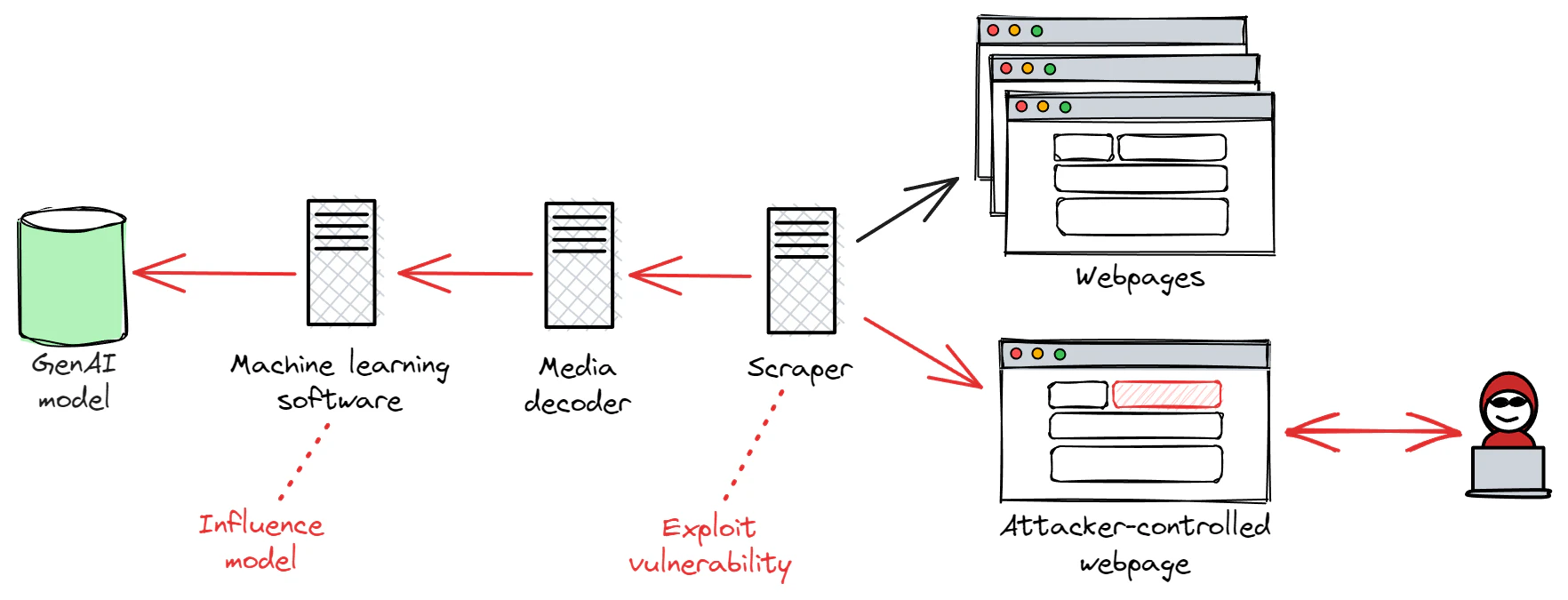
Indirect prompt injections can also pose a serious security risk to LLMs, resulting in either redirection or misdirection of their activities. By embedding malicious prompts within requested content, attackers can manipulate an LLM to gather sensitive data, execute harmful code, or redirect unsuspecting users to dangerous sites.
Mitigation:
Implement a routine for updating model parameters to fortify the model against attacks.
Employ ensemble methods to combine predictions from multiple models.
Conduct ethical hacking and penetration testing to proactively identify and address vulnerabilities in the AI system.
Establish continuous monitoring mechanisms to detect unusual patterns or deviations in model behavior.
Inside the 2026 CISO Budget Benchmark
See how 300+ CISOs are planning, spending, and prioritizing for the year ahead. Compare your strategy against peers and identify emerging trends.
Get the report

5. Partial control over outputs
Even with extensive testing and extended explainability, AI models can still return unexpected outputs that could be biased, unfair, or incorrect. This unpredictability arises because model developers have only partial control over outputs and users can further influence responses—whether intentionally or unintentionally—by crafting irregular prompts.
Real-life attack scenarios:
An attacker could aim to create hyper-realistic fake content using your AI model to spread misinformation (deepfakes), or a malicious actor may try to inject bias into your model via input manipulation (content-bias injection).
Mitigation:
Conduct bias audits on training data and model outputs using tools like Fairness Indicators.
Advocate for the implementation of bias-correction techniques, such as re-weighting or re-sampling, during model training.
Define and implement ethical internal guidelines for data collection and model development.
Promote transparency by sharing ethical guidelines for AI usage with users.
What you should know:
LLMs, combined with chat interfaces and software automation, enable attackers to:
Work faster and smarter: LLMs can generate and execute more attacks while making them harder to detect through enhanced polymorphism.
Create convincing deceptions: Attackers can also use them to craft highly plausible phishing lures and deepfakes by combining content from multiple sources, which makes brand impersonation more convincing.
Operate more independently: LLMs allow attackers to run sophisticated end-to-end attacks with greater autonomy by using AI to make decisions and control malicious operations with less human intervention.
Discover new vulnerabilities: Perhaps most concerning, attackers can leverage AI to uncover entirely new classes of attacks we haven't seen before.
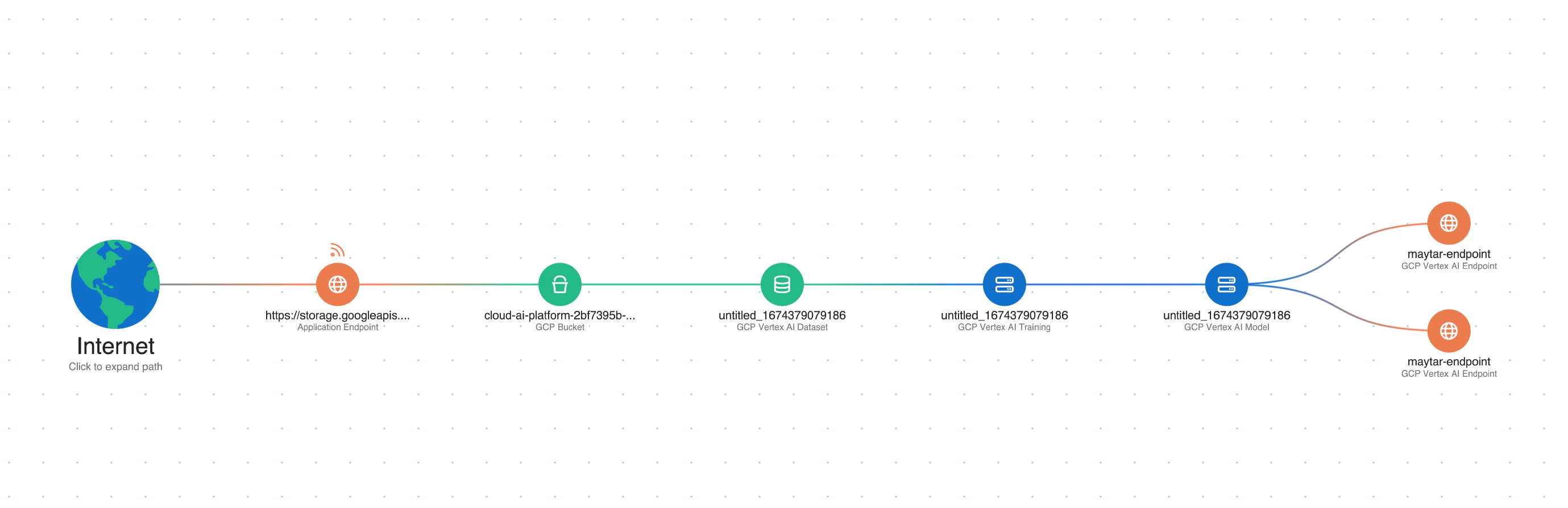
6. Supply chain risks
AI is heavily based on open-source datasets, models, and pipeline tools that have limited security controls in place. When attackers exploit these, supply chain vulnerabilities can not only compromise the AI system but also extend to other production components.
Real-life attack scenarios:
An attack could aim to tamper with or substitute model functionalities (model subversion) or attempt to introduce compromised datasets filled with adversarial data (tainted dataset injection).
Mitigation:
Vet and validate AI datasets, models, and third-party AI integrations to ensure their security and integrity.
Implement secure communication channels and encryption for data exchange in the supply chain.
Establish clear contracts and agreements with suppliers that explicitly define AI security standards and expectations.


7. Shadow AI
The presence of unauthorized or unnoticed AI systems, also known as shadow AI, introduces undetectable vulnerabilities without corresponding mitigation strategies.
Real-life attack scenarios:
If an employee uses ChatGPT from their browser without adjusting privacy settings, OpenAI may use sensitive or proprietary data to train its model. Employees may also use AI solutions that lack minimum security guarantees, which can introduce significant risks.
Mitigation:
Create standardized operations for AI support and AI risk management within your organization to streamline AI system deployment and monitoring.
Institute protocols for swiftly responding to and addressing any unauthorized AI deployment.
Conduct comprehensive education and training programs to ensure that personnel are well-informed about safe and authorized AI use.
Avoiding AI risks in cybersecurity: 3 impactful things you can do
We’ve talked about some specific AI security risks, as well as some ways to steer clear of those issues. However, there are also some overarching steps you can take to protect your AI systems:
Gen AI Security Best Practices [Cheat Sheet]
This cheat sheet provides a practical overview of the 7 best practices you can adopt to start fortifying your organization’s GenAI security posture.
Get Cheat Sheet

Build a rock-solid data governance framework
Without clear guidelines for how your organization manages data, the potential for security issues rises. Plus, your ability to prevent—or at least spot—those issues decreases.
Data governance in general encompasses:
Data classification based on sensitivity and business value
Risk assessment to identify potential threats and vulnerabilities to data assets
Security protocols like encryption, access controls, and monitoring systems
But more specifically, your framework should include the following:
Ethical guidelines: Establish principles for AI development and deployment, including how it relates to fairness and transparency. This includes outlining acceptable use cases and, if you can’t specify them all, how people can make smart decisions about when to use AI.
Bias detection: Put tools and processes in place to identify and mitigate algorithmic bias. These will likely include advanced statistical techniques and machine learning models.
Accountability measures: Specify what individual or team will own and ultimately be responsible for AI outcomes—both good and bad ones.
Maintain an up-to-date AI asset inventory
It’s safe to bet that AI is more ingrained in your org’s daily operations than you realize—even if your team is generally very open to experimenting with AI tools. You can only control that usage and reduce associated risks if you have full insight into the AI assets in use across your organization.
Here’s what should go into your AI asset inventory:
The AI you see: These are your front-facing tools, like the chatbots that greet your customers or the recommendation engines that suggest products on your website.
The AI you don't see: Hidden within your existing software are powerful AI features working quietly in the background—think fraud detection algorithms scanning transactions or machine learning models assessing credit risks.
AI add-ons: Traditional tools that offer additional AI capabilities as upgrades are also worth noting, particularly for tool consolidation.
Your custom AI solutions: Any proprietary algorithms or models your team has developed deserve special attention in your inventory.
For each asset, track the following:
Its purpose and capabilities
Where it lives in your system (such as cloud, on-premise, or edge devices)
What data it uses and how it performs
Its compliance status and potential risks
You’ll want to keep this information regularly updated. That way, as your tech stack evolves, you can avoid duplicate investments, spot potential security vulnerabilities, and ensure that all your AI tools align with your organization's policies.
Looking for AI security vendors? Check out our review of the most popular AI Security Solutions ->
Use AI-specific security solutions
Traditional cyber security and cloud security tools have their uses but aren’t well equipped to handle the challenges that AI introduces.
In contrast, AI-specific security tools have capabilities like:
Dynamic threat landscape adaptation: Thanks to machine learning algorithms that analyze vast datasets of global threat intelligence, AI-powered security systems can rapidly identify and adjust to new threat vectors and attack methodologies. This adaptability can make all the difference when countering sophisticated, evolving threats like polymorphic malware or advanced persistent threats.
Automated threat hunting and forensics: AI-driven solutions can proactively search for threats that have evaded initial detection. By automating the correlation of attack data across multiple sources and reconstructing attack timelines, they can speed up the forensic analysis process dramatically. Of course, the more complex your cloud environment, the more valuable this is, both in terms of time savings and resource allocation.
Explainable AI compliance and auditing: Advanced AI security solutions are now using explainable AI techniques to provide a transparent look at how AI navigates decision-making processes. This capability can help you meet regulatory requirements and conduct thorough security audits.
Other capabilities, like anomaly detection based on behavioral trends, also give purpose-built AI security solutions an edge over traditional options.


The modern leader's role in securing AI applications
A security-first mindset needs to permeate every level of modern companies’ initiatives. But for that to be possible, the leaders green-lighting AI-enabled or AI-centric projects need to set an example. This means actively championing and allocating resources for AI risk management—from hiring specialized talent to investing in sophisticated monitoring tools and regular security assessments.
But that’s only one piece of the puzzle. It’s just as important to create a culture where security doesn’t feel like a roadblock to innovation but is instead an enabler.
Leaders can drive this shift by making security considerations a natural part of their teams' AI development conversations. They can also encourage developers to think about potential vulnerabilities during the design phase, reward team members who proactively identify security risks, and regularly reinforce the message that it's better to take the time to build secure AI systems than to quickly deploy features that are full of vulnerabilities.
Protecting your AI applications with Wiz
As a key part of our mission to help organizations create secure cloud environments that accelerate their businesses, Wiz is the first cloud-native application protection platform to introduce a native and fully-integrated AI security offering.
Watch 12-min Wiz Demo: Cloud Risk Meets AI Awareness
See how Wiz secures cloud environments—covering everything from misconfigs and identity risks to protecting sensitive AI training data.
Watch demo now
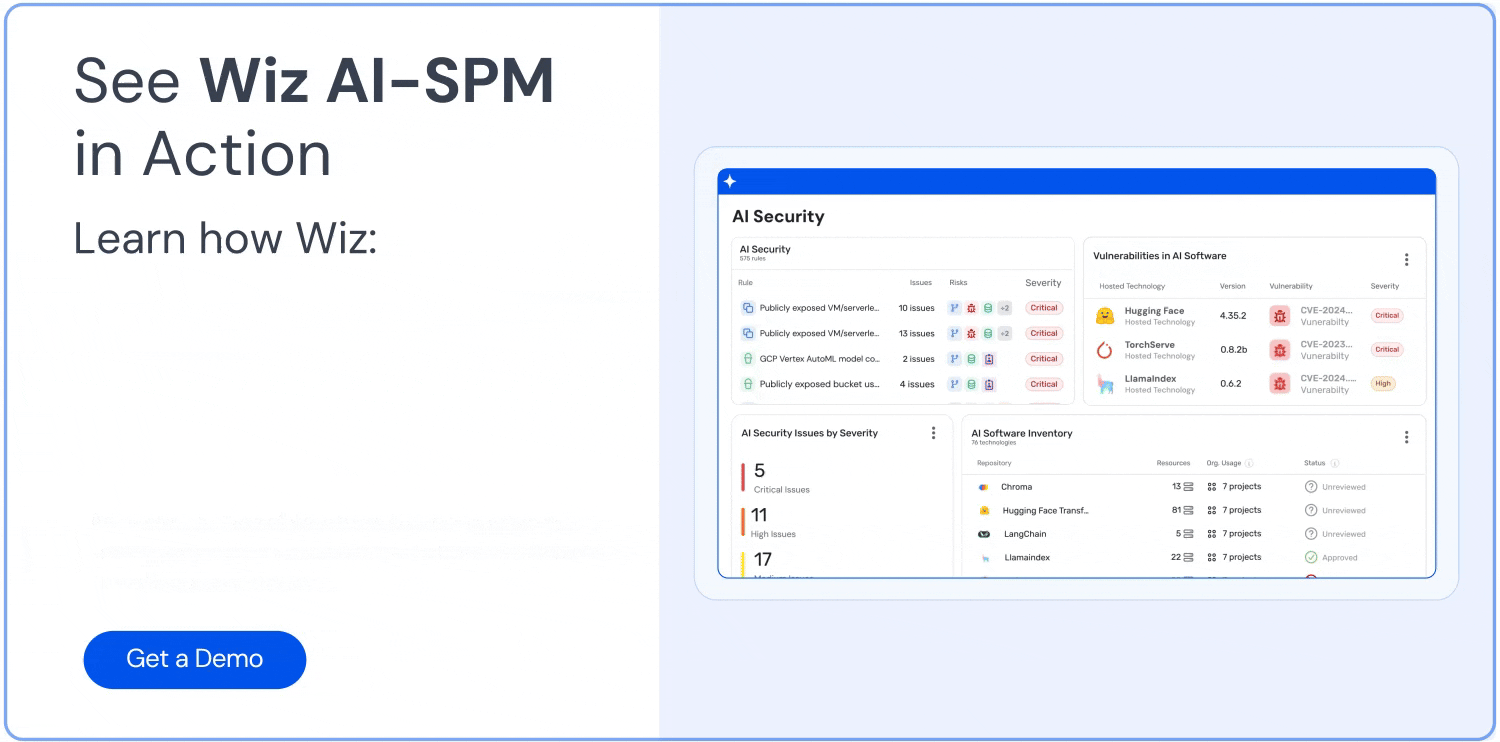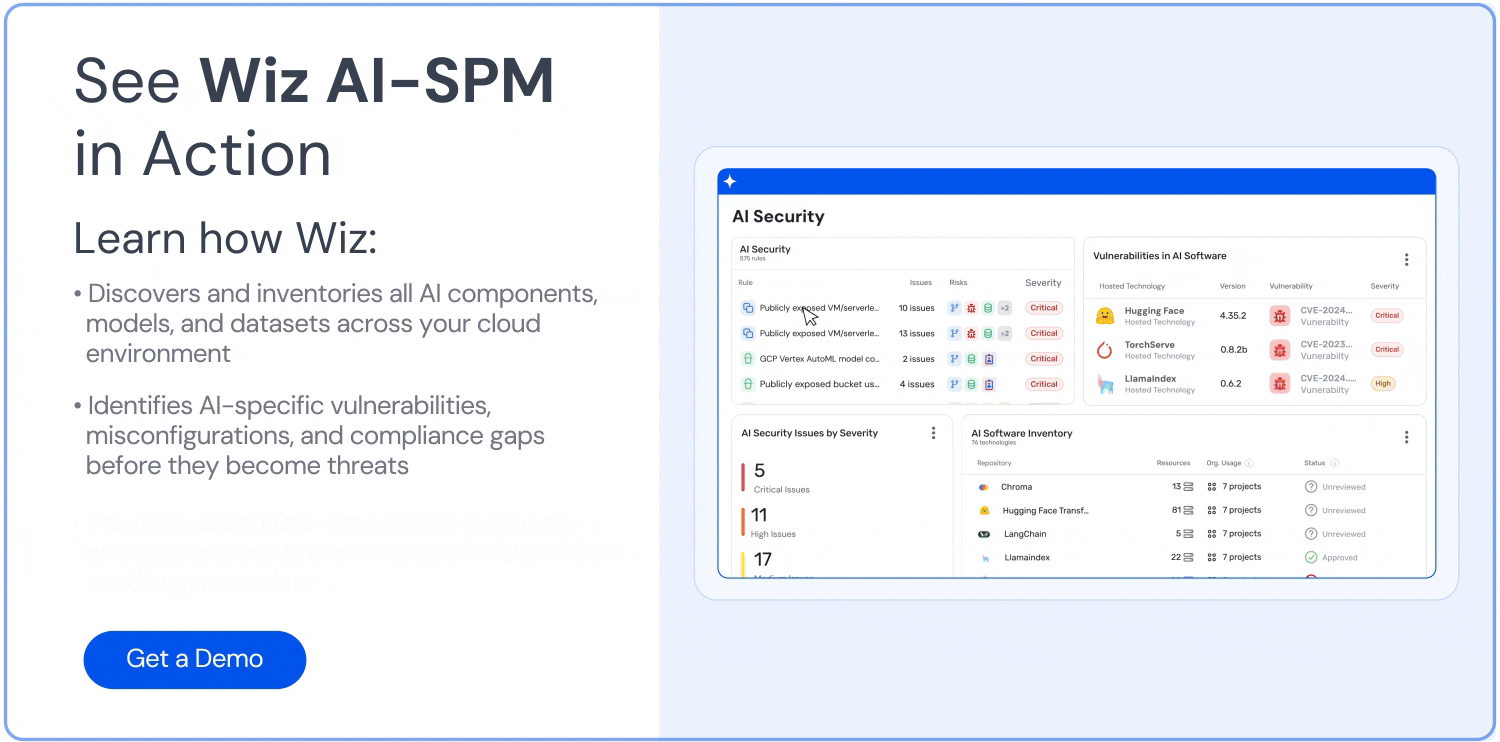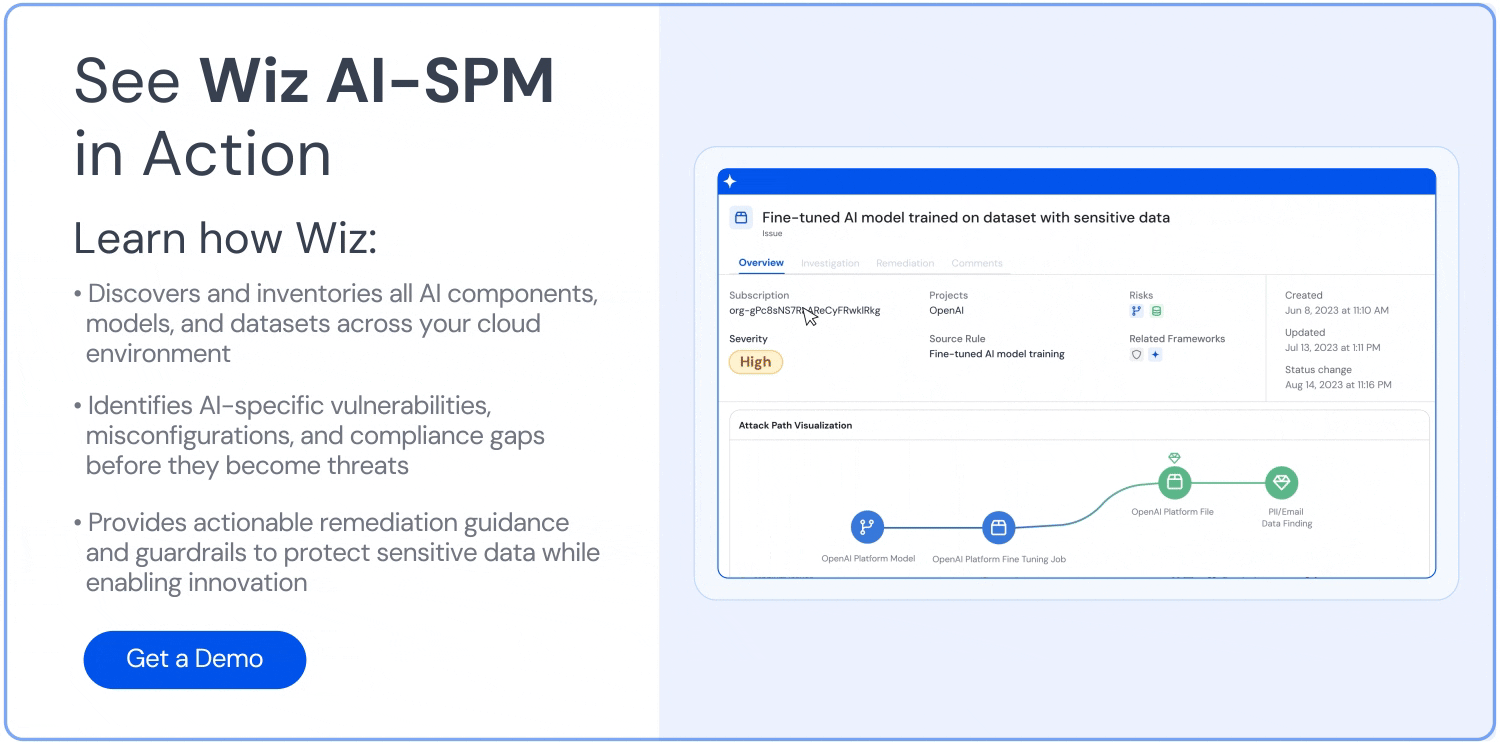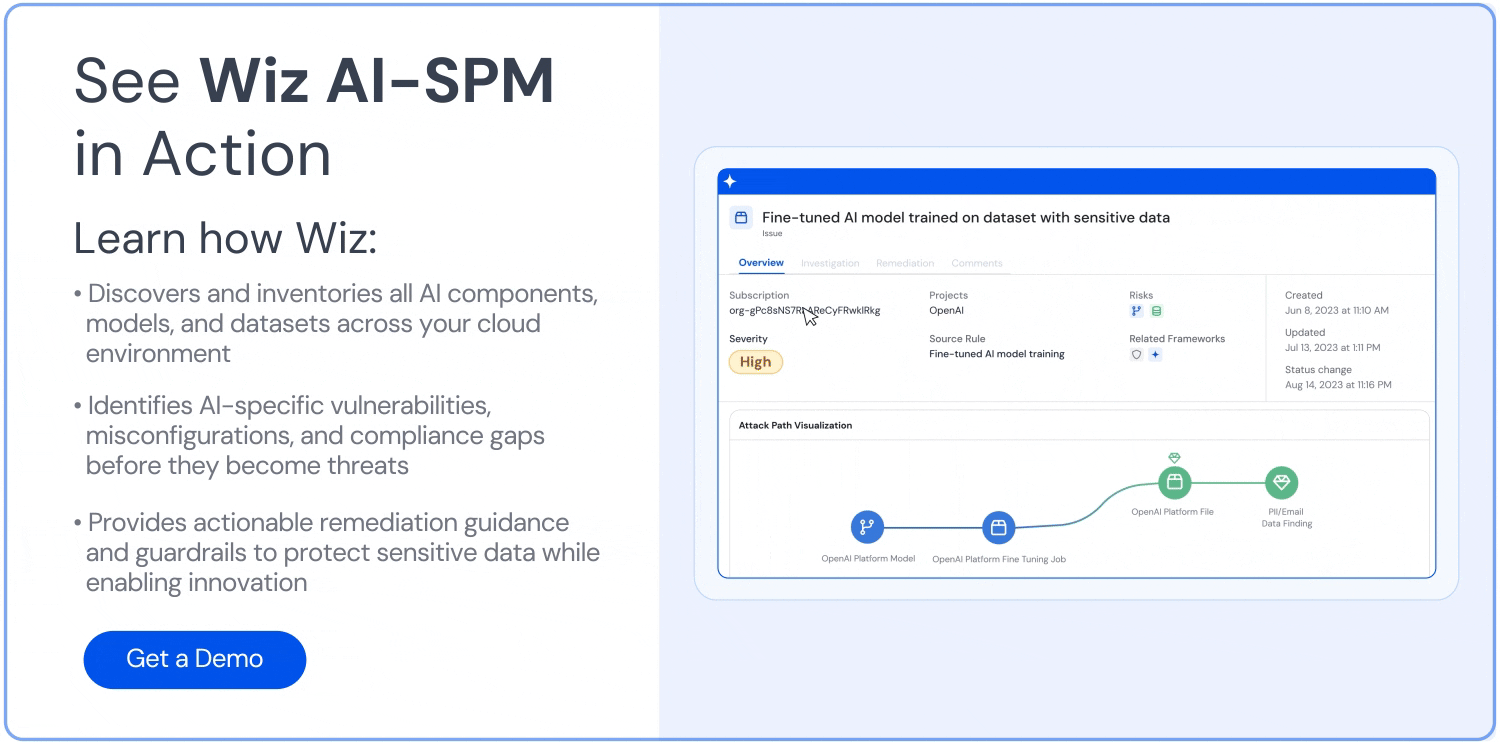
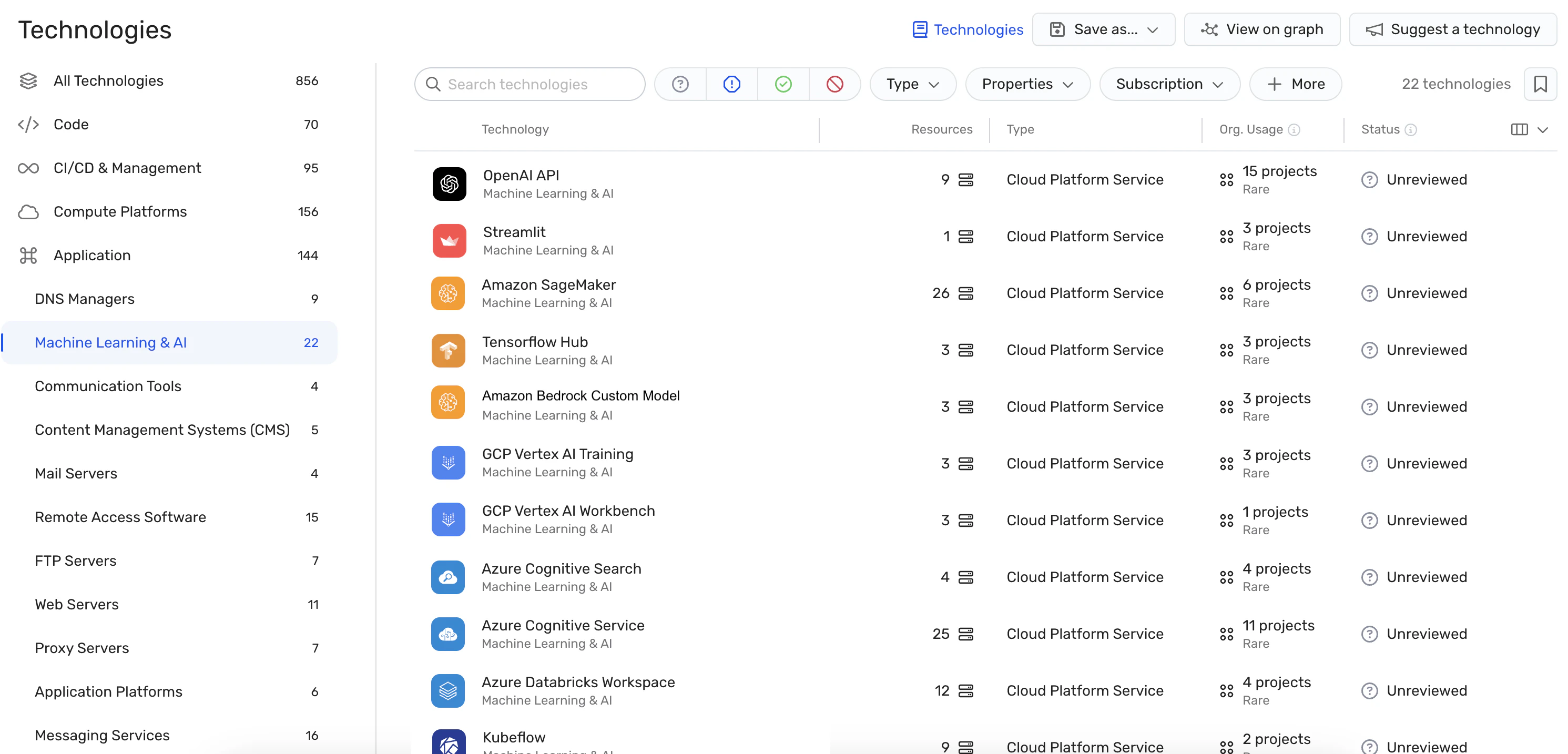
Our AI security posture management (AI-SPM) solution offers a variety of automated security functionalities. Here are just a few:
AI bill of materials (AI-BOM) management
The AI-BOM gives you full visibility over every AI service, technology, library, and SDK in your environment. You can use it to quickly discover your AI pipelines and detect shadow AI.
AI pipeline risk assessment
By testing your AI pipelines against known vulnerabilities, exposures, and other risks, AI-SPM allows you to uncover attack paths to your AI services, with a focus on spotting pipeline misconfigurations and sensitive data usage in training sets.
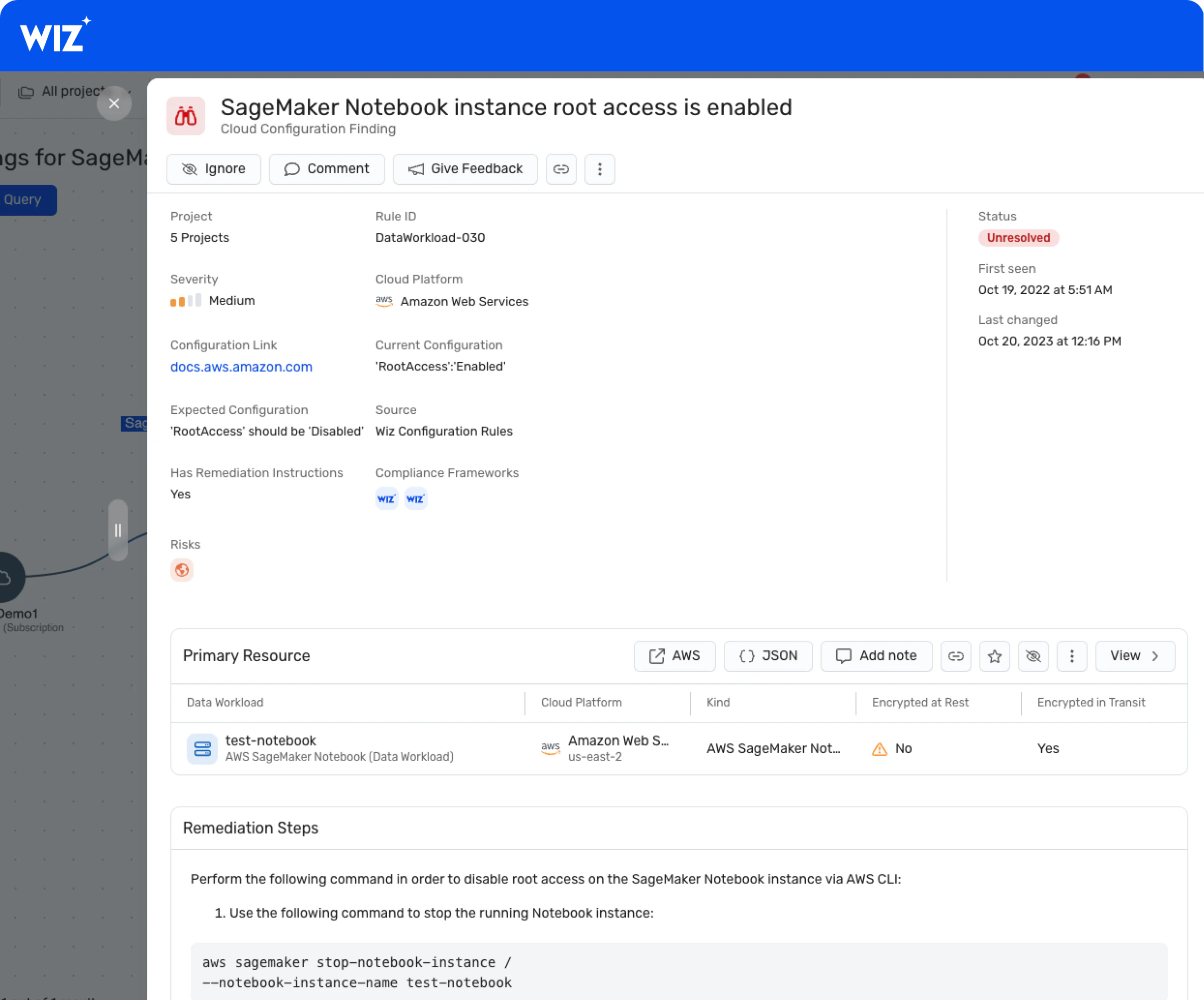
AI security dashboard access
You can navigate your AI security posture with Wiz’s dashboard, which offers a consolidated view of security risks. It also provides a prioritized queue of contextualized risks for your AI pipelines and lists vulnerabilities in the most popular AI storage solutions and AI SDKs, such as OpenAI and Hugging Face.
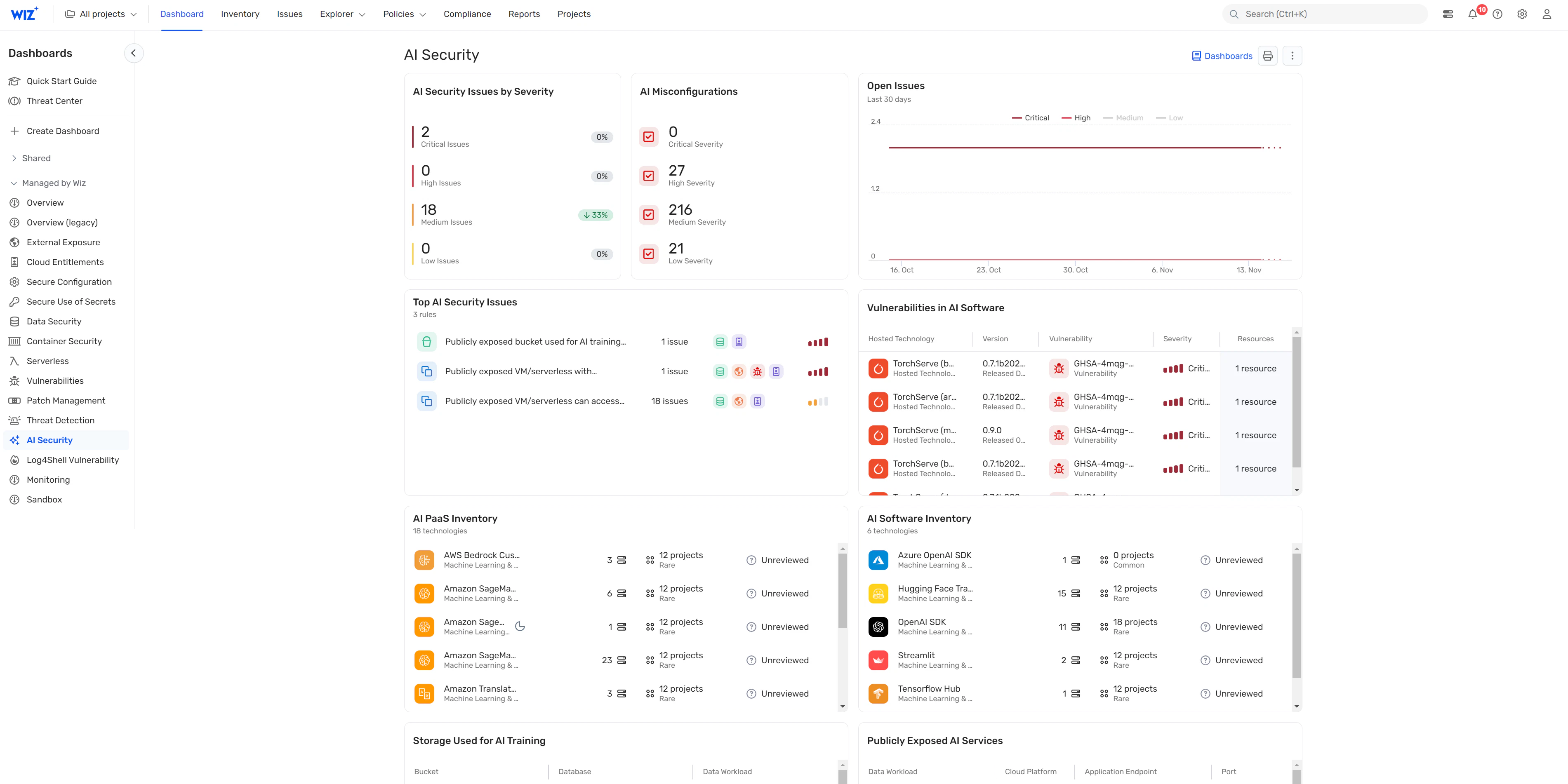
Ultimately, Wiz’s innovative approach to security provides end-to-end protection for your hybrid IT infrastructure, including robust safeguards for your AI systems. To keep those systems as secure as possible in the short- and long-term, though, you’ll need to monitor how the AI landscape is shifting.
The first step is reviewing our 2025 industry report, which summarizes findings from and trends across hundreds of thousands of public cloud accounts. Grab The State of AI in the Cloud today for an overview of how AI use cases are changing, key industry players, and more.